
CRAFT 요약 Character Region Awarenness for Text Detection)
이미지 효과가 있는 글자를 인식하는 CRAFT에 대해서 파헤쳐보자
CRAFT (Character Region Awarenness for Text Detection)
Clova AI Research, NAVER Corp.
이미지에서 정보를 얻기 위한 방법을 찾기 위해 SOTA 논문을 뒤지던 중에 발견한 논문. Naver Clova AI Research 팀에서 작성했다.
이 논문의 요약은 다음과 같다. 어떤 텍스트가 논문에 있는 글처럼 바르게 작성되어 있지 않고, 그래픽 효과로 휘어져 있거나, 크기가 각각 다른 경우에 CRAFT를 사용하면, text detection이 잘 된다는 것이다. 실제 OCR 프로젝트를 해 본 경험이 있다면, 글자가 조금만 틀어져도 인식이 제대로 되지 않는 다는 것을 느낄 수 있다. 그러한 점에서 이 논문이 눈에 띄었고 집중해서 볼 수 밖에 없었다.
그럼 도대체 왜 잘되는 것 일까? 하나 하나 파헤쳐 보자.
1. Introduction
CRAFT는 기본적으로 CNN으로 디자인되어 있고, 여기서 $region$ $score$과 $affinity$ $score$이 나오게 된다. $region$ $score$은 이미지에 있는 각각의 글자들을 위치 시키는 데에 사용되고, $affinity$ $score$은 각 글자들을 한 인스턴스에 묶는데에 사용된다. 문자 수준의 annotation이 부족하기 때문에 CRAFT에서는 약한 정도의 supervised leargning 프레임 워크를 제안한다. 일반적으로 사용하는 텍스트 이미지 데이터 셋에 글자 수준의 groud-truth 데이터가 없기 때문이다. 데이터 셋으로는 ICDAR을 사용했고 그 외에 MSRATD500, CTW-1500 등을 통해 실험했다.
2. Related Work
생략
3. Methodology
CRAFT의 주 목표는 일반 이미지에 있는 각 글자들을 정확하게 포착하는 것이다. 이를 위해 딥러닝을 학습시켜서 글자의 위치와 글자들 간의 affinity(글자 옆에 글자가 있는 것 정도로 해석)를 예측한다. 데이터를 학습시킬 때, 이와 관련된 데이터 셋, 즉 글자 하나하나 학습시키는 데이터가 없으므로, 이 모델은 약한 지도학습 방법으로 학습된다.
3.1 Architecture
VGG-16에 Batch Normalization이 적용된 네트워크를 backbone 모델로 사용했다. 이 모델에는 디코딩 파트에 skip-connection이 있는데 이것은 U-Net과 비슷한 구조로 Low-level의 feature들을 취합한다. 최종 아웃풋에는 score map에 해당하는 두 개의 채널이 있고, 여기에서 위에서 말한 $region$ $score$과 $affinity$ $score$이 나오게 된다.

3.2 Training
3.2.1 Ground Truth Label Generation
Training Image를 위해서 $region$ $score$과 $affinity$ $score$에 대한 ground thruth 라벨을 생성해야 한다. 이 라벨은 글자 단위의 박스를 이용해 만든다. $region$ $score$은 주어진 픽셀이 글자의 중앙에 있을 확률이고, $affinity$ $score$는 인접한 글자들의 공간의 가운데에 있을 확률이다. 이 가운데에 있을 확률을 가우시안 히트맵으로 인코딩한다. 왜냐하면 ground truth 지역이 엄격하게 경계쳐져 있지 않기 때문이다. 이 히트맵은 $region$ $score$과 $affinity$ $score$ 모두에 사용된다.

제안된 ground truth는 receptive field의 크기가 작은걸 사용함에도 불구하고, 모델이 크거나 또는 긴 텍스트를 찾아내는 것을 가능케 한다.
3.2.2 Weakly-Supervised Learning
학습에 사용되는 데이터는 단어 단위의 annotation을 가지고 있다. weakly-supervised learning을 사용해서 실제 이미지에 단어 단위의 annotation이 들어오면, 이미지에 글자 부분을 crop하고, 학습된 모델이 이미지에 있는 글자 지역을 예측해 글자 단위의 bounding-box를 만든다.

위의 사진에서 그 구조를 파악할 수 있다.
- 먼저 단어 단위의 이미지들이 crop된다.
- 학습된 모델이 $region$ $score$를 예측한다.
- watershed 알고리즘이 글자 단위로 쪼갠다.
- crop단계에 사용했던 inverse transform을 사용해서 글자 박스의 좌표들이 원래의 이미지 좌표로 변형해 넣는다.
만약 모델이 부정확한 region score로 학습되게 된다면, 결과의 글자들은 blurred 되어 나타나게 된다. 이것을 막기 위해서, psuedo-GT(제안된 Ground Truth)의 퀄러티를 측정한다. text annotation의 강력한 시그널인 word length를 이용해서 측정하게 되는데, 이것을 이용하면 psuedo-GT의 confidence를 계산할 수 있다.
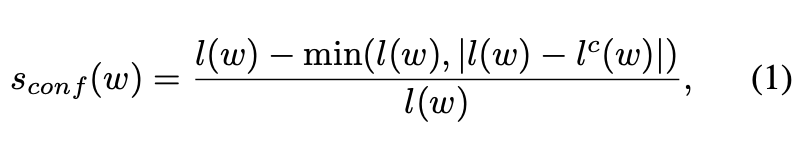
먼저 첫 번째 식에 있는 변수들에 대해서 설명해보자. $s_{conf}(w)$는 우리가 구하려는 샘플 $w$에 대한 confidence 값이다. $R(w)$와 $l(w)$는 각각 샘플 $w$d에 대한 bounding box 영역과 단어의 길이이다. 글자단위로 쪼개는 과정에서 글자들의 추정된 bounding box들과 이에 상응하는 글자들의 길이를 알아낼 수 있다. 이 길이는 $l^c(w)$로 표현된다. 결국 이 식에서 confidence라 함은, 단어의 길이라는 정보를 이용해서 얼마나 단어의 길이를 잘 인식했는지를 나타내는 수치라고 할 수 있다.
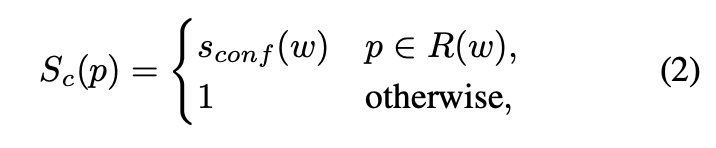
이제 두 번째 식을 보자. $S_c(p)$는 pixel-wise의 confidence map이다. 이 픽셀이 $R(w)$에 속하면 아까 구한 $s_{conf}(w)$를 사용하고, 그렇지 않으면 confidence를 1로 준다.
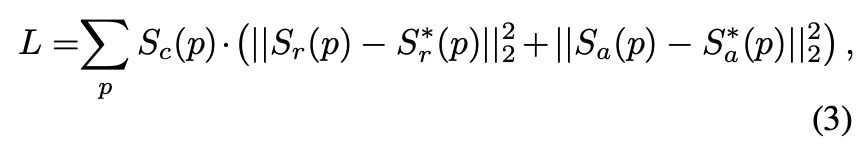
마지막으로 L을 구하는 식을 보면, $S_{r}^\star(p)$와 $S_{a}^*(p)$는 각각 pseudo-GT의 region score과 affinity map을 의미한다. 그리고 $S_{r}(p)$와 $S_{a}(p)$는 각각 예측된 region score과 affinity map을 의미한다. 합성 데이터로 훈련시킬 때, 우리는 진짜 ground truth를 얻을 수 있으므로, $S_{c}(p)$는 1로 설정된다. 훈련이 수행되면, CRAFT모델은 각 글자들을 더 정확하게 예측할 수 있고, confidence 점수인 $s_{conf}(w)$ 는 점진적으로 증가하게 된다. 즉, 학습할 수록 confidence가 올라가게 되어 글자가 더 잘 인식된다는 말이다.
학습을 하면서, 만약 confidence score가 0.5보다 낮으면 추정된 글자의 바운딩 박스들은 모델을 학습하는데 악영향을 주기 때문에 무시하도록 설정된다.
3.3 Inference
추론 단계에서, 결과물이 다양한 모양으로 전달된다. 예를들어, 단어 박스나 글자 박스들이나 다른 다각형 등으로 나오게 된다. 평가를 위해서 IoU(word-level intersection-over-union)을 사용한다. $QuadBox$를 만들어서 글자를 큰 박스로 인식하고 각 글자들을 polygon을 생성한다. 이 방식을 통해서 휘어져 있는 text 전체에 대해서 효과적으로 다룰 수 있게 된다. 이것은 OpenCV에 있는 $connectedComponents$와 $minAreaRect$를 사용해 만들 수 있다.
4. Discussions
Robustness to Scale Variance 비록 데이터 셋에 있는 텍스트의 사이즈는 매우 달랐지만, 모든 데이터에 대해서 단일 스케일의 실험을 진행했다. 상대적으로 작은 receptive fiel는 큰 이미지에 있는 작은 글자를 잡는데 적합했고, CRAFT는 이를 통해서 다양한 글자들을 잡아내는데 robust하다는 결과이다.
Multi language issue IC17에는 Bangla와 Arabic 글자들이 있지만, synthetic text 데이터 셋에는 Bangla와 Arabic 글자들이 포함되어 있지 않다. 게다가, 두 언어는 각각의 글자들을 개별적으로 세그먼트하기가 힘들다. 왜냐하면 모든 글자들이 필기체로 이루어져있기 때문이다. 그러므로 이 모델을 두 글자들을 분간해 내지 못하고, Latin이나 한글, 중국어, 일본어 등을 찾지 못한다.
Generalization ability 3개의 다른 데이터 셋들로, fine-tuning을 하지않고 실험 해 보았을 때, SOTA의 퍼포먼스를 보여주는 것을 확인했다. 이 모델이 한 데이터 셋에 오버피팅 되는 것 보다, 여러 글자들에 일반적인 성능을 내는 것을 증명하는 결과이다.
5. 결론
글자 단위의 annotation이 주어지지 않았을 때 각 글자들을 detect하는 CRAFT 모델을 제시했다. $region$ $score$과 $affinity$ $score$로 다양한 모양의 텍스트 모양들을 커버할 수 있다. 여기에 weakly supervised learning을 사용해 pseudo-ground truth를 만들어 내었다. CRAFT는 SOTA에 해당하는 퍼포먼스를 보여줬으며 일반화 성능과 scale 변동에 덜 민감하지만, multi language를 다루지는 못한다는 점에서 한계를 보인다.
CRAFT 요약 Character Region Awarenness for Text Detection)