
What is Transformer?
보는 논문 마다 Transformer와 Attention가 빠지지 않고 등장하곤 합니다.
이에 대해서 공부하고 정리해 봤습니다.
Transfomer
글 미리보기 :
- Transformer는 번역에서 RNN 셀을 이용하지 않고 순차적 계산도 하지 않는다.
- 이를 통해 속도를 크게 향상 시켰다
- 성능도 크게 오르게 되었다.
- RNN을 사용 안하는데 단어의 위치와 순서 정보도 활용할 수 있다.
- 인코더 디코더 방식을 활용한다
Attention은 뭐지?
번역을 하는 상황을 가정해보자
논문참고* Attention is All you Need
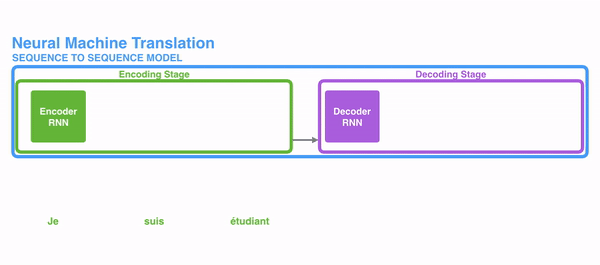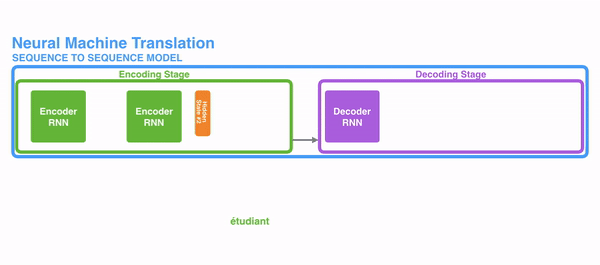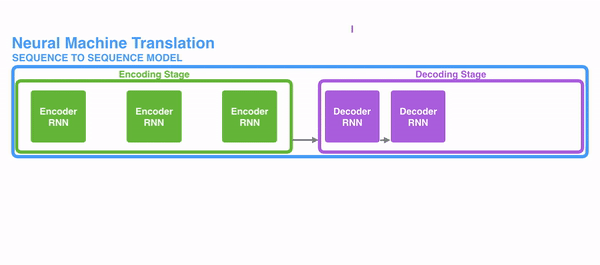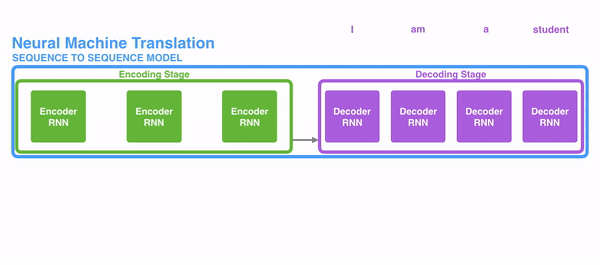
RNN을 통해 번역을 하는 상황을 가정해 보자. 한 단어를 다른 언어로 번역하는 일을 하기 위해서는 word embedding작업이 필요하다. 일단 임베딩에 관한 설명은 간단하게만 하고 넘어가자면, 텍스트를 수치화 하는 개념이다. 워드 임베딩이 끝난 후에 단어는 정해놓은 차원의 공간으로 임베딩 된다.
RNN은 인풋 벡터와 히든 state의 벡터를 받아 아웃풋 벡터를 뱉어 낸다. 신경망 번역기의 구성은(Seq 2 Seq) Encoder와 Deoder로 이루어져 있다. 인풋이 인코더로 들어오면 이를 기반으로 hidden state를 만들어내고 업데이트를 하게 된다. 업데이트 된 hidden state는 차례로 인코더에 input값과 들어가 최종 hidden state를 만들어내고, 이것이 디코더로 들어가서 인풋에 대한 번역된 아웃풋을 출력하게 된다. 이 과정에서 업데이트 된 마지막 hidden state는 디코더에게 전달되는 context라고 할 수 있다. decoder 역시 hidden state를 갖고 있고 time step이 지나가면서 하나씩 이 hidden state를 다음으로 넘기는 과정이다.
Attention!
je suis etudiant라는 문장을 i am a student로 바꿀 때, je와 i라는 단어를 연결시켜 해석 하는게 더 정확한 결과를 가져오는 게 당연할 것이다. 여기서 특정 문맥을 더욱 상세히 보게 해주는 것이 바로 Attention이다. 즉, 순차적으로 계산되는 각각의 RNN cell에서 나오는 state를 모두 활용해보자는 것이다.(보통 RNN번역에서는 최종 hidden state만을 context로 이용해서 번역한다.)
이 Attention은 보통의 Seq2Seq모델과는 두 가지 점에서 차이를 보인다.
Seq2Seq model with Attention
- 인코더는 디코더에 더 많은 데이터를 보낸다. 마지막 hidden state를 디코더에 보내는 대신, 모든 hidden state를 디코더에 보낸다.
- Attention 디코더는 아웃풋을 내기 전에 추가적인 작업을 거친다. 각 타임스텝에 있는 디코더에 해당하는 인풋의 부분들에 집중을 하기 위해서, 디코더는 다음과 같은 작업을 한다.
- 각 인코더의 hidden state는 인풋 문장의 특정 단어와 관련된 부분을 가지고 있다. (먼저 step 4에 해당한다고 하자, step 3까지 만들어진 h1,h2,h3 인코더 hidden state가 존재)
- 각 hidden state에 대해서 점수를 매긴다.(점수를 매기는 법에 대해서는 일단 무시하고 넘어감)
- 점수를 softmax화 해서 이 점수로 각 hidden state를 곱한다. 이를 통해서, 높은 점수를 가진 hidden state를 더 상세히 보고, 점수가 낮은 hidden state는 빼낸다
- 가중치가 적용된 hidden state 벡터들을 합한다.
여기서 만들어진 context vector는 step4에 있는 디코더를 위한 것이다. 점수를 매기는 작업은 각 time step의 디코더에서 진행된다.
이제 정리를 하자면,
- Attention 디코더 RNN은 임베딩된
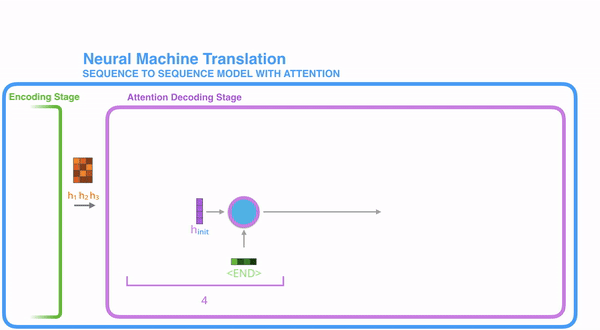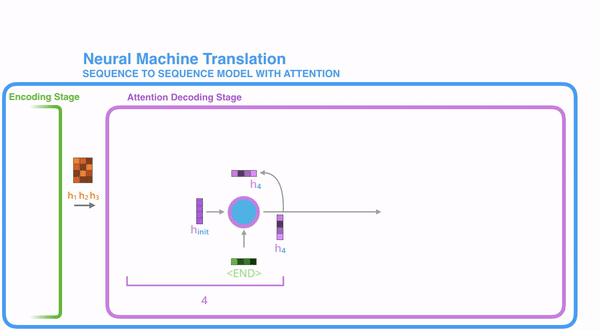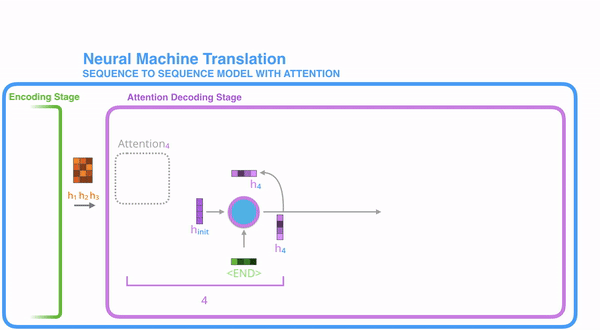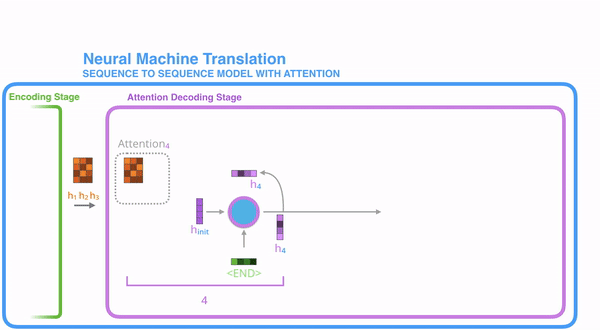
토큰을 받고 디코더의 시작 hidden state를 받는다. - RNN은 인풋을 처리하고 아웃풋과 새로운 hidden state 벡터(h4)를 만든다. output은 버려진다.
- Attention 단계에서, 우리는 인코더의 hidden state와 h4 vector를 이용해 context vector(C4)를 만들어내고 이것은 다음 time step에 사용된다.
- h4와 C4를 하나의 벡터로 합친다. (concatenate, 갖다 붙인다)
- 이 벡터를 Feed forward neural network에 넘긴다.
- feed forward neural network의 아웃풋은 이 time step에 대한 결과물을 가리킨다.
- 다음 time step까지 반복한다.

Illustrated Transformer
transformer는 Attention is All You Need의 논문에서 제안 되었다. 먼저 high level에서 살펴보자.
A High level look
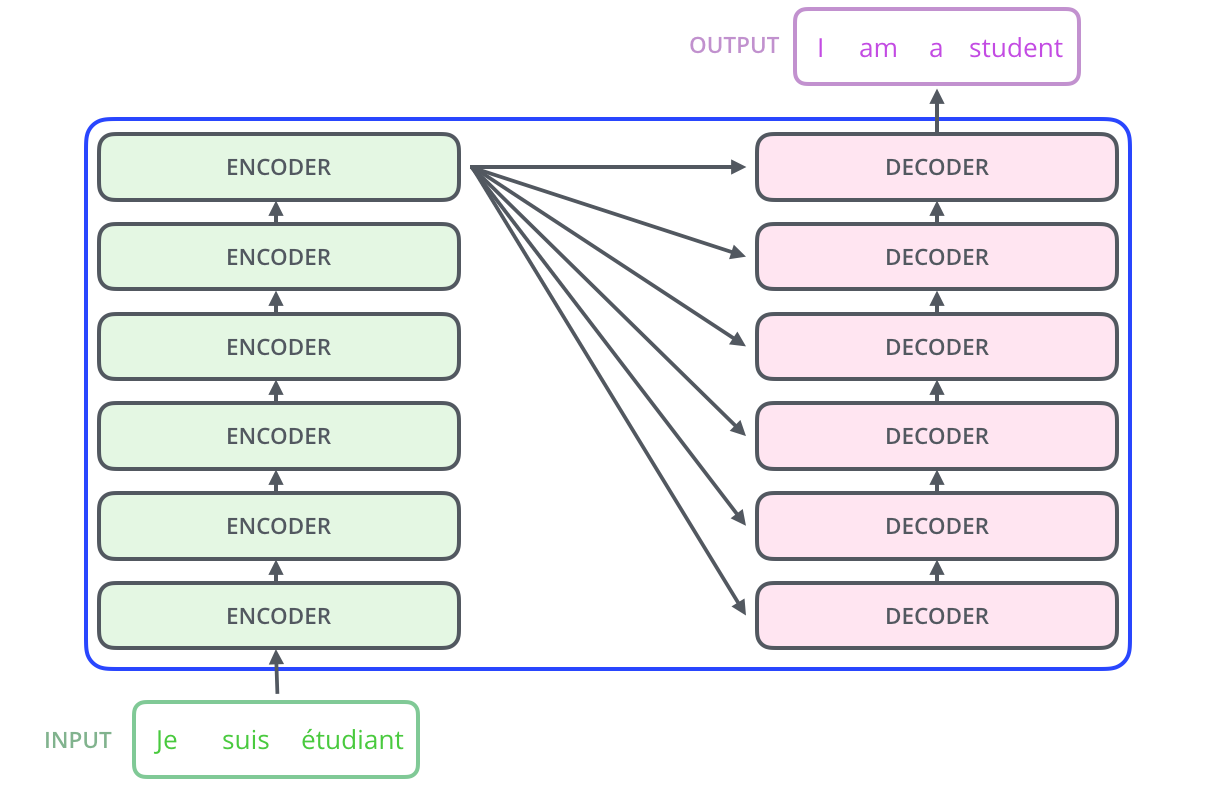
번역기 모델을 가정하고, transfomer을 사용한다고 하면, 인풋은 transformer를 통해 처리되고 output 이 나오게 된다. transformer의 구성을 보면, 인코딩과 디코딩 파트, 그리고 이를 연결해주는 부분으로 이루어져 있다. 인코딩 파트는 encoder를 stack시켜놓은 구성이다. 인풋 벡터와 아웃풋 벡터가 같기 때문에 쌓는 것이 가능한 게 transformer의 특징이다. 디코딩 부분 역시 decoder가 stack되어 있는 모습이다. 인코더들은 모두 같은 구조를 갖지만 weight를 공유하지는 않는다. 각각은 self-attention과 Feed Forword Neural Network의 sub layer로 구성되어 있다.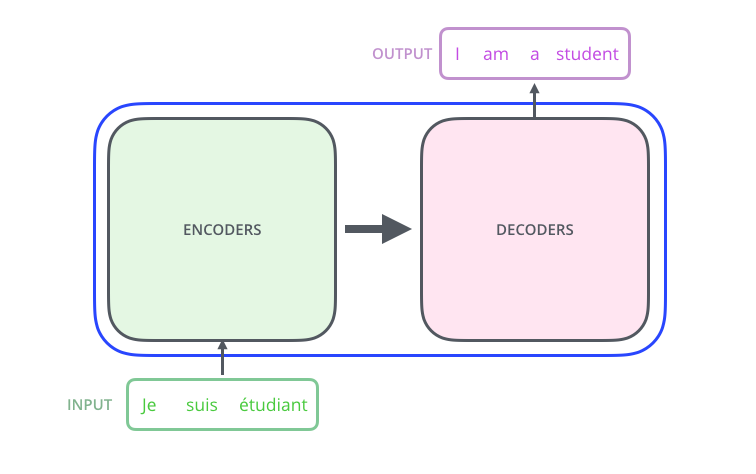
인풋은 첫번째로 self-attention layer로 들어간다. 이 layer는 인코더가 인풋 문장에 있는 다른 단어들을 볼 때, 특정 단어로 인코드 하는 것을 돕는다. 이 self-attention을 중점적으로 보도록 하자. self-attention의 아웃풋은 feed forward NN으로 들어간다. 똑같이 생긴 feed forward NN이 독립적으로 각 포지션에 들어가 있다.(인코더 또는 디코더에 다 들어가 있음)
디코더는 특이한 점이 있는데, self-attention과 FFNN 모두를 갖고 있지만, 이 사이에 Encoder-Decoder Attention이라는 layer를 추가적으로 갖고 있다는 것이다. 이것은 attention layer로써 인풋 문장에 대한 적절한 부분들에 대해 집중할 수 있도록 도와주는 역할을 한다.
이 구조로 번역을 해보자
번역을 위해서, 위에서 했던 것과 같이 word embedding부터 실시한다. 임베딩은 맨 아래 인코더에서부터 시작한다. 모든 인코더에 공통되는 부분은, 512차원의 벡터를 받는다는 것이다. 벡터의 길이는 하이퍼 파리미터로서 우리가 설정할 수 있는 부분이다. 보통 이 값은 훈련 셋에 있는 가장 긴 문장을 기준으로 설정된다. 단어 임베딩이 끝나면, 각 단어들은 인코더의 두 레이어로 들어가게 된다.(self attention layer, FFNN layer)
여기서 Transformer의 큰 특징이 드러난다. 각 포지션에 있는 단어는 지정된 인코더의 path를 따라 간다는 것이다. self-attention에는 이런 의존성이 존재한다. FFNN에는 의존성이 없지만 그러므로 FFNN을 타면서 여러 path들이 병렬로 처리가 가능하게 된다.
Encoding
인풋 벡터를 받으면 인코더는 이 벡터들을 self-attention 층으로 보낸다. 그리고 FFNN을 통하고, 결과물을 만들어 다음 인코더로 보내게 된다(구조상 위로 보낸다). 문장 번역을 하는 예를 들어 보자.
”The animal didn’t cross the street because it was too tired”it은 무엇에 해당되는 것일까? street일까 아니면 animal일까? 사람들에게는 아주 쉬운 질문이지만, 알고리즘 상으로 답을 내기에는 어려운 질문이다.
it을 처리할때, self-attention은 it을 animal과 연결하는 것을 허용한다. 모델이 각 단어를 처리할 때, self-attention은 다른 위치에 있는 인풋 시퀀스를 보는 것을 허용해서 이 단서들을 이용해 단어를 잘 인코딩 하도록 돕는 역할을 한다.
결국 self-attention은 인코딩 파트에서 Transformer가 다른 연관된 단어를 갖고 우리가 지금 처리 중인 것에 대해서 잘 이해할 수 있도록 하는 방법이다. 다른 말로하면, self-attention은 self-attention 점수를 각 단어마다 매겨서 단어와 단어끼리의 매칭 점수를 이용해 연관정도를 파악하는 것 이라고도 할 수 있다. 더 자세히 알아보자.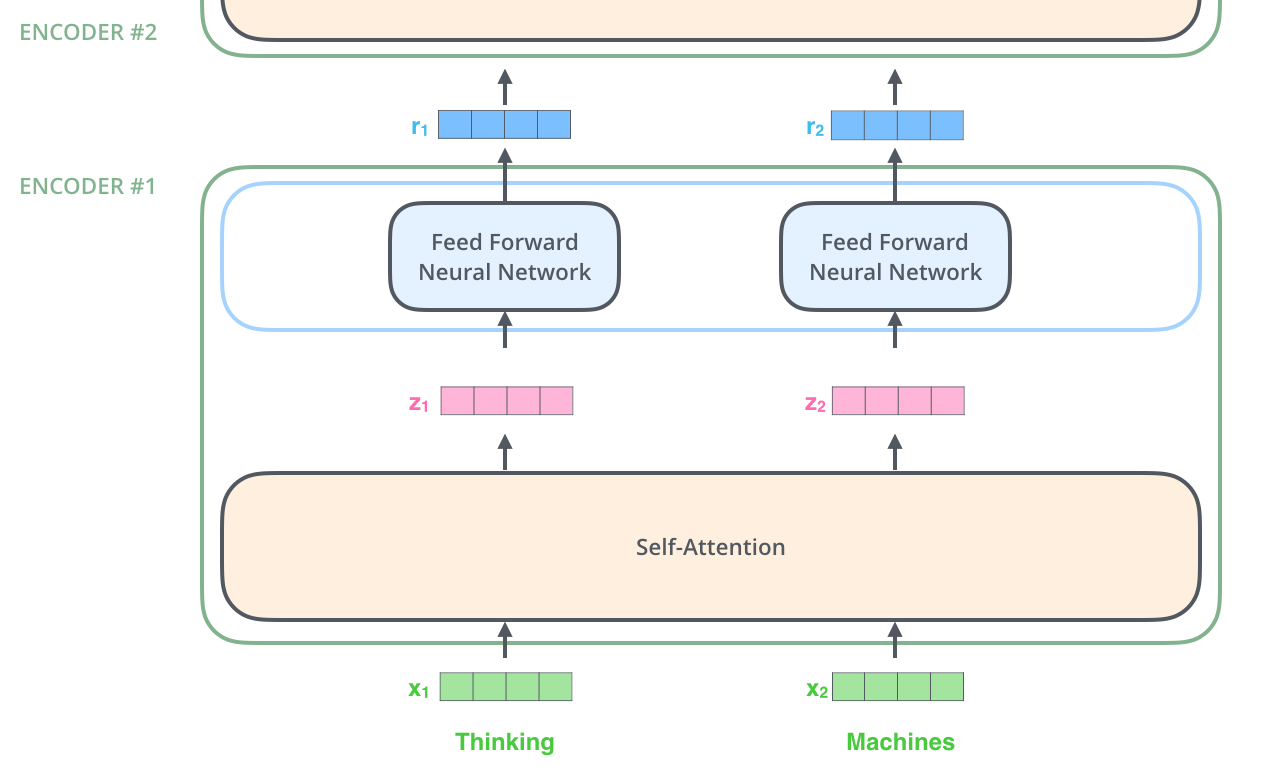
Self-attention in detail
self-attention이 벡터들을 갖고 어떻게 계산하는지 보도록 하자. 첫 번째로 self-attention의 계산에서는, 각 인코더의 인풋 벡터들에서 세 개의 벡터들을 생성한다. 각 단어에서 이제 Query Vecotor를 만들어낸다. Key Vector, Value Vector로 이루어진다. 이 벡터들은 훈련단계에서 학습된 3개의 행렬들을 곱하여 생성된다.(Q, W, K)
주목할 점은 이 새 벡터들이 임베딩 벡터보다 차원이 작다는 것이다. 이것들의 차원은 64이고, 임베딩과 인풋/아웃풋 벡터들은 512차원이다. 이 행렬들이 작아질 필요는 없다. 이것은 단순히 multihead attention 상수를 계산하기 위한 것이기 때문에 선택의 문제다.
query, key, value 벡터들?
이 세 벡터들은 attention에 대해 생각할 때 유용하게 계산되는 abstraction들이다. 하단에 attention이 어떻게 계산되는지를 진행해보면, 이 세 벡터들의 역할에 대해서 잘 이해할 수 있다.
두 번째로 self attention점수를 내는 것이다. Thinking이라는 단어에 대해서 self-attention 점수를 계산한다고 해보자. 우리는 문장에 있는 이 단어에 대한 각 단어들의 점수가 필요하다. 점수는 특정 위치에서 단어를 인코딩 할 때 입력 문장의 다른 부분에 집중할 정도를 결정한다. 이 점수는 각 단어에 점수를 매길 때 query vector와 key vector의 dot product로 계산된다. 그래서 만약 우리가 #1포지션에서 self-attention을 한다면 첫 점수는 q1과 k1의 dot product로 계산될 것이다. 두 번째 점수는 q1과 k2의 dot product로 계산된다.
세 번째와 네 번째는 점수를 8로 나눠주는 것이다.(key value의 차원에 루트 씌운 값) 이렇게 하게되면, Key 벡터의 차원이 늘어날수록 dot product 계산시 값이 증대되는 문제를 막아주게 되어 안정적으로 gradient를 흐르게 만들어 줄 수 있다. 그리고 결과를 softmax 처리에 보낸다. softmax는 점수를 normalize해서 그 값들이 모두 1까지 갖는 양수로 만든다. softmax 스코어는 이 위치에서 각 단어가 얼마나 표현될지를 보여주는 점수인데, 분명히 그 위치의 단어는 가장 높은 점수를 갖겠지만 가끔은 현재 단어와 관련된 다른 단어를 위치시키는 것이 좋을 때도 있다. 예를 들어 it이 어떤 걸 의미 하는가에 대해서 궁금할 때.
다섯 번째는 각 value 벡터를 softmax 점수로 곱하는 것이다. 여기서의 포인트는 우리가 집중하고 싶은 단어의 값을 유지하고 관련없는 단어의 값을 떨어트리는 것이다. 여섯 번째는 가중치가 곱해진 벡터들을 더하는 것이다. 이 과정을 통해 이 위치의 self-attention 레이어 값을 얻게된다. 이것을 통해 self-attention 계산이 완료된다. 결과로 나온 vector는 FFNN에 보낼 수 있는 벡터이다. 이 계산은 matrix form으로 되어있다면 더 빠르게 가능하다.(Matrix Factorization으로 한번에 계산이 가능함) 이제 단어 수준에서 계산을 살펴 보자.
Matrix Calculation of self-attention

첫 번째는 Q, K, V 행렬을 계산하는 것이다. 임베딩을 matrix X로 만들 때 훈련된 가중치 행렬(WQ, WK, WV)를 곱해서 이 세가지 행렬을 이미 만들어 냈다. X와 WQ를 곱해서 Q가 나오고 WK를 곱해서 K, WV를 곱해서 V가 나오게 된다.
행렬들에 관련된 것이기 때문에, 이 2-6댠계를 하나의 공식으로 응축하여 self-attention의 아웃풋을 계산할 수 있다. Matrix Factorization을 통해서.
multi head attention
multi head attention은 attention layer를 head의 수 만큼 병렬로 수행하는 것을 말하는데, 이를 통해서 모호한 문장을 해석하는데 연관된 정보를 다른 관점에서 바라보게 만들어서 퍼포먼스를 상승시키는 효과가 있다(it 구분하기 등). attention layer의 퍼포먼스는 다음 두 가지 방법을 통해 향상시킨다.
- multi head attention은 단어의 위치를 잡는 능력을 여러 위치들로 잡는 것으로 확장한다. 이전에 실시해서 얻은 값에는 다른 인코딩 값이 있긴 하지만, 단어 그 자체의 값에 의해 dominate 될 수 있다. multi head attention을 이용하면 “The animal didn’t cross the street because it was too tired”라는 문장에서 우리는 it이 의미하는 것이 무엇인지 번역할 때 유용할 것이다.
- multi head는 attention layer에 representation subspace들을 제공한다. multi head attention을 통해 여러개의 QKV 가중치 곱 행렬을 가질 수 있다. 각 셋들은 랜덤하게 값이 들어가고, 훈련이 끝나면, 각 셋들은 input 임베딩들을 다른 representation subspace에 투영하는데 사용된다.
만약 input X를 8개의 다른 attention head에 넣고 계산하게 되면, 8개의 다른 Z 행렬들이 등장하게 된다. FFNN은 사실 8개의 행렬에 대해 예상하지 못한다. FFNN은 single 행렬을 기대하게 되는데 그래서 우리는 이 여덟개의 행렬을 응축해 하나의 matrix로 만들어야 한다.
- concatenate 한다
- W0 행렬을 가중치 matrix와 곱해 훈련한 데이터를 만든다
- 결과는 정보를 가진 모든 atttention head의 값을 가진 Z matrix이다. 이걸 FFNN에 보낸다
이 과정을 그림으로 요약하면 다음과 같다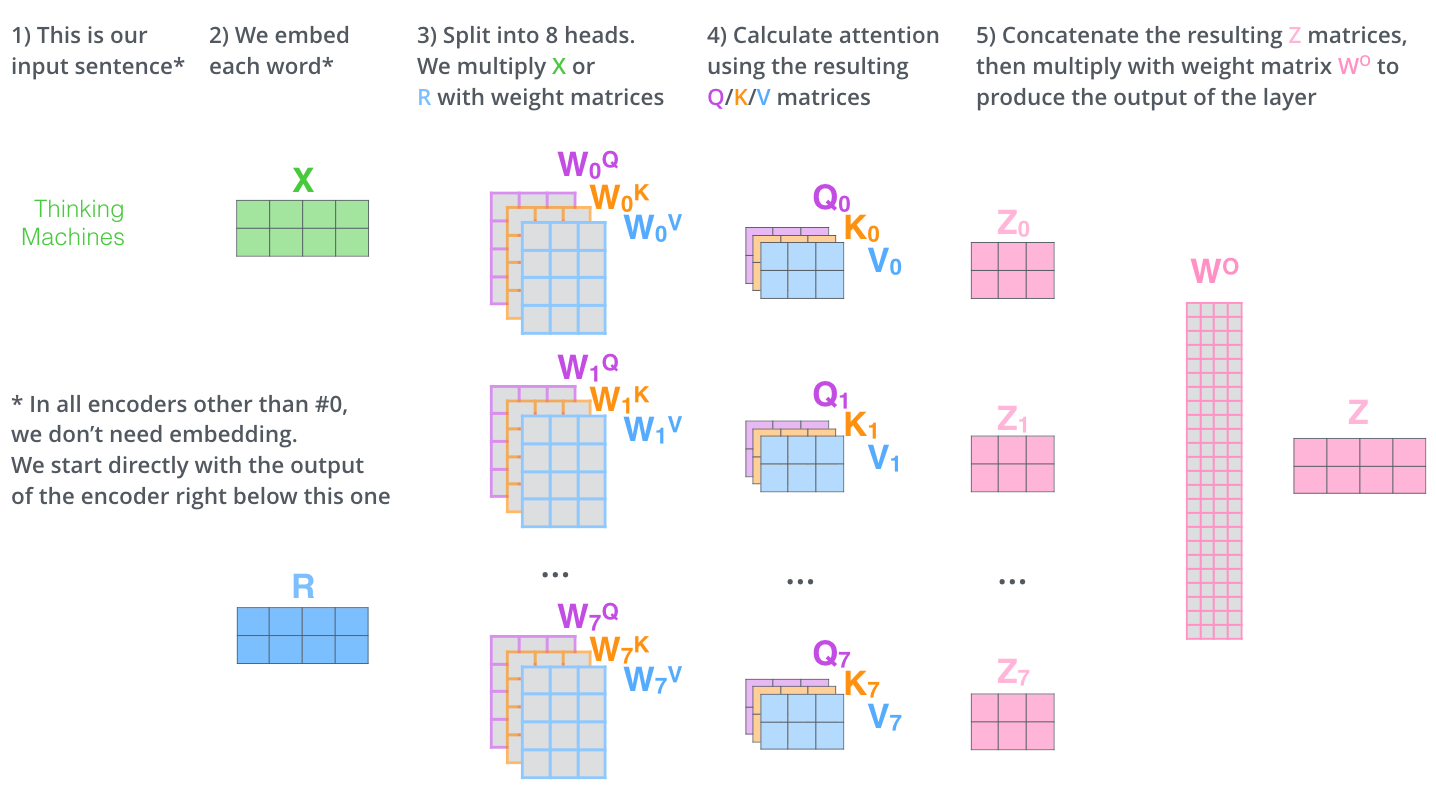
모든 attention head를 더하면 굉장히 다양한 해석이 등장한다.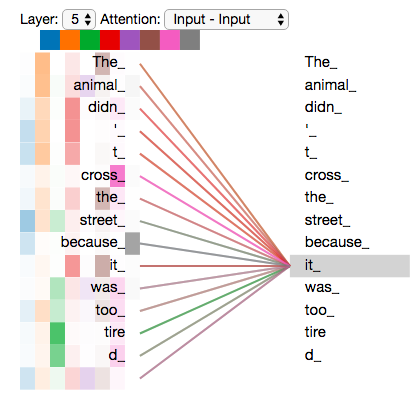
Positional encoding을 통한 시퀀스 순서 나타내기
모델을 설명하면서 하나 놓친 부분은, 인풋 시퀀스의 순서를 어떻게 설명하느냐이다. RNN에서는 문장의 길이가 짧긴 하지만 각 단어의 sequence 정보를 잘 활용할 수 있었다. 하지만, Transformer는 속도가 느린 RNN을 사용하지 않고 Matrix Factorization을 활용하기 때문에 시퀀스 정보를 전달해 주는 과정이 필요하다.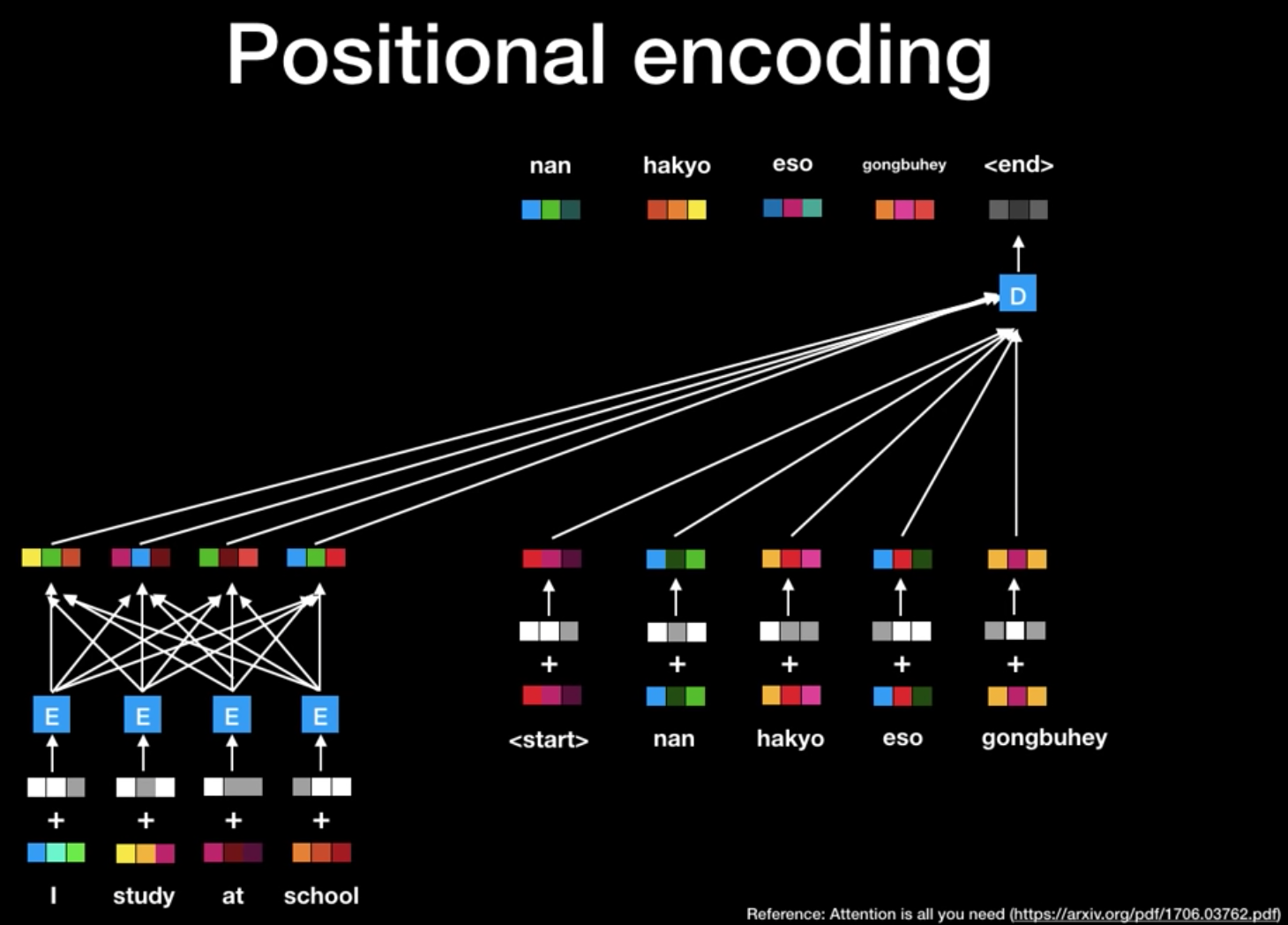
transfomer는 각 인풋 임베딩에 벡터를 더하고, 이 벡터들은 상대적인 위치 정보들을 갖게 되어 모델이 학습하는 패턴을 따르게 된다. 이것을 통해 각 단어의 위치를 결정하고 또는 시퀀스에 있는 다른 단어들과의 거리를 결정한다. 여기서 포인트는 이러한 벡터 값을 임베딩에 더하면 Q / K / V 벡터로 투영 된 후 내적시 임베딩 벡터간에 의미있는 거리를 제공할 수 있다는 것이다. positional encoding을 통해서 얻을 수 있는 또 하나의 장점은 훈련 셋보다 긴 문장이 들어왔을 때에도 scale이 가능하다는 것이다.
Residuals
인코딩 구조에서 한 가지 더 설명할 부분은 residual이다. positional encoding은 학습이 진행될 수록 역전파에 의해서 정보가 많이 손실된다. 각 인코더에 있는 각 sub-layer에서 residual connection을 취해주고 더해줌으로써 이 정보 손실을 막아준다. Residual connection 후에는 layer-normalization 단계를 통해서 학습의 효율을 증진시켜준다.
인코더는 이렇게 작업이 끝난다. 정리하자면, 인코더는 임베딩 - multi head attention - FFNN 그리고 Residual Connection으로 이루어진다.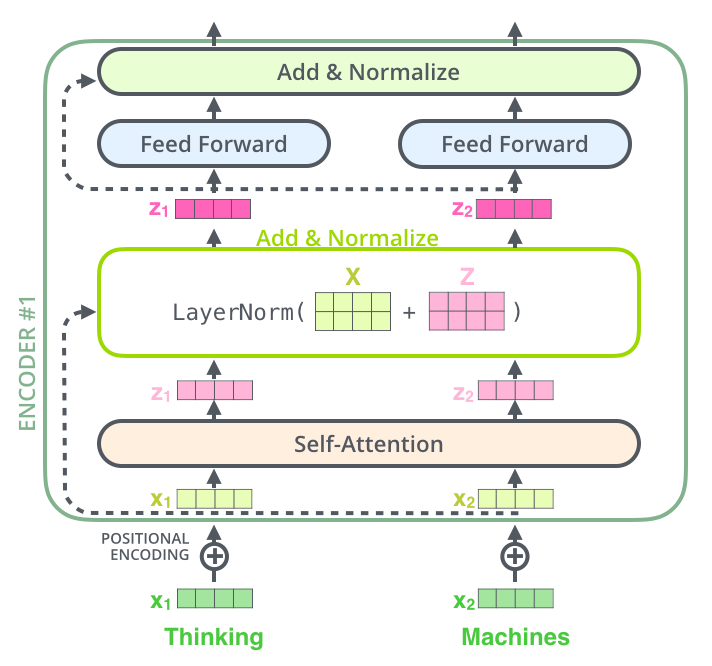
Decoder
가장 위의 encoder의 아웃풋은 attention 벡터 셋 K, V로 변환된다. 이 두 벡터들은 각 디코더의 질문에 사용된다. K와 V는 encoder-decoder attention 층에서 디코더가 인풋 시퀀스에 적절한 자리에 집중하는 것을 돕는다.
디코더는 masked Multi head attention - multi head attention - FFNN의 구조로 이루어져 있다. 디코더 입력값은 Query로 사용되고 Encoder의 최종 결과값을 Key, Value로 사용한다. 이것은 디코더의 현재값을 Query로 encoder에 질문하는 모습이 되겠고, 인코더 출력값에서 중요한 정보를 K, V로 획득해서 디코더의 가장 적합한 다음 단어를 출력하는 과정이라고 볼 수 있다.
이 과정이 Decoder layer 에서 쭉 이어지게 되고, 이후에는 linear layer와 softmax layer를 지나게 된다. 일반적으로 softmax를 이용해서 가장 높은 확률값을 전달해주는 과정이 여기서도 이루어 지게 된다. 가장 높은 확률값을 지닌 단어가 다음 단어로 오게 된다. 하지만 여기서도 Lable smoothing을 통해 한층 더 성능을 높여준다. one hot encoding으로 값을 확확 죽이는 것 보다, 정답은 1에 가깝게, 오답은 0애 가깝게 만들어 주는 과정이다. Thanks가 고맙다와 감사하다로 label된 것을 예로들면, 고맘다와 감사하다는 둘 다 잘못 label된 것이 아니다. 하지만 one hot encoding을 시켜버리면, 이 둘은 완전히 다른 결과값을 갖게 될 것이다. 이렇게 되면 학습이 효율적으로 학습이 진행되지 않게 되는데, 이를 방지하는 것이 label smoothing인 것이다.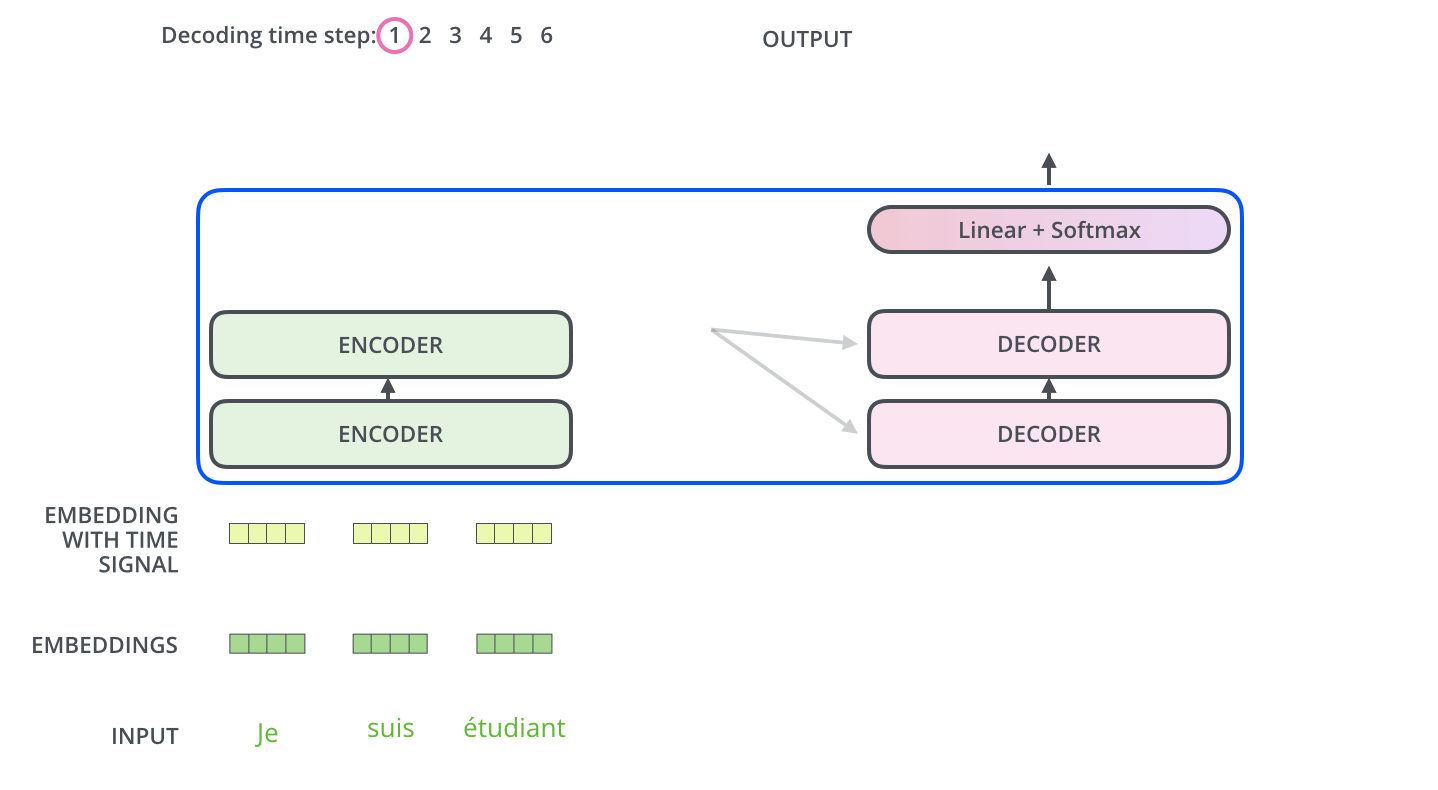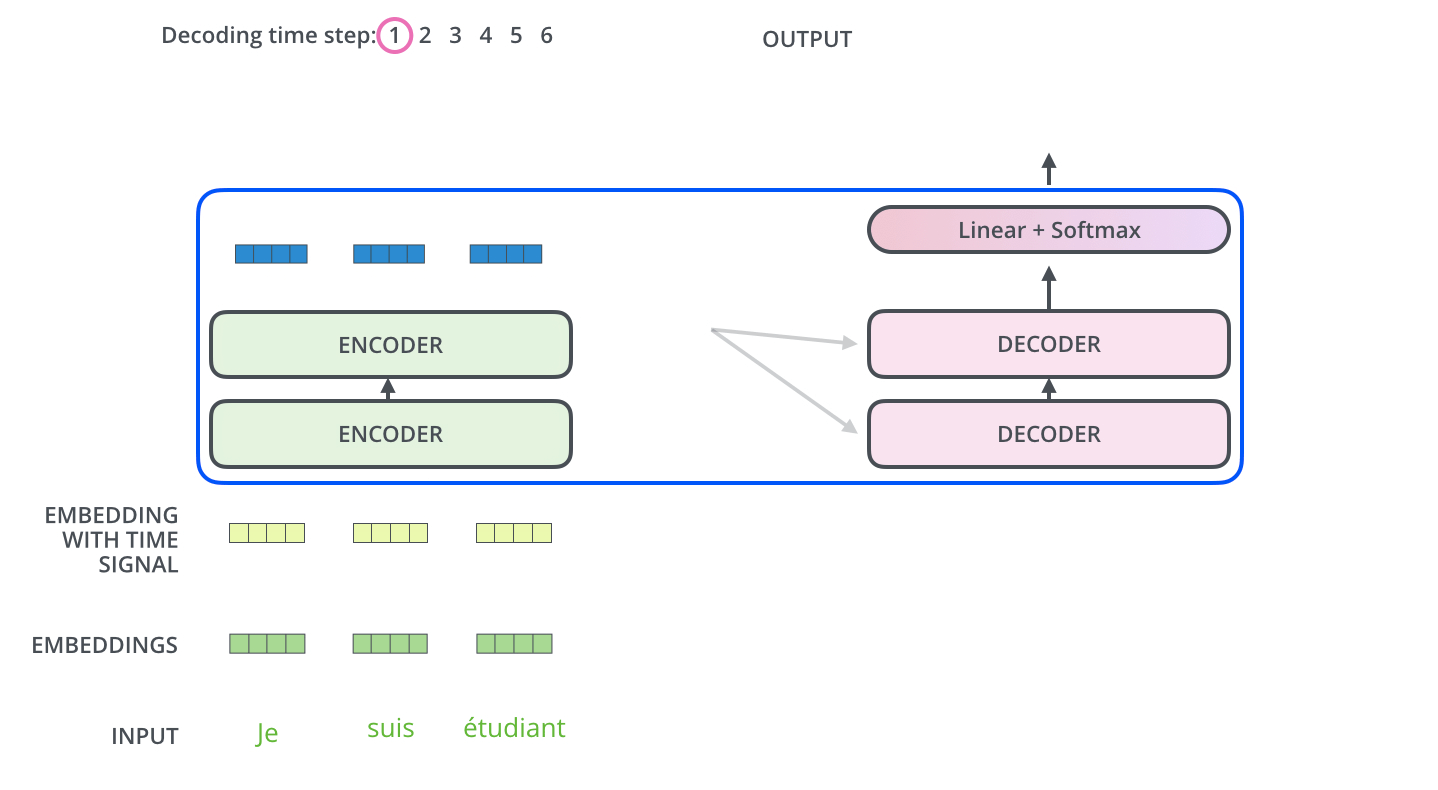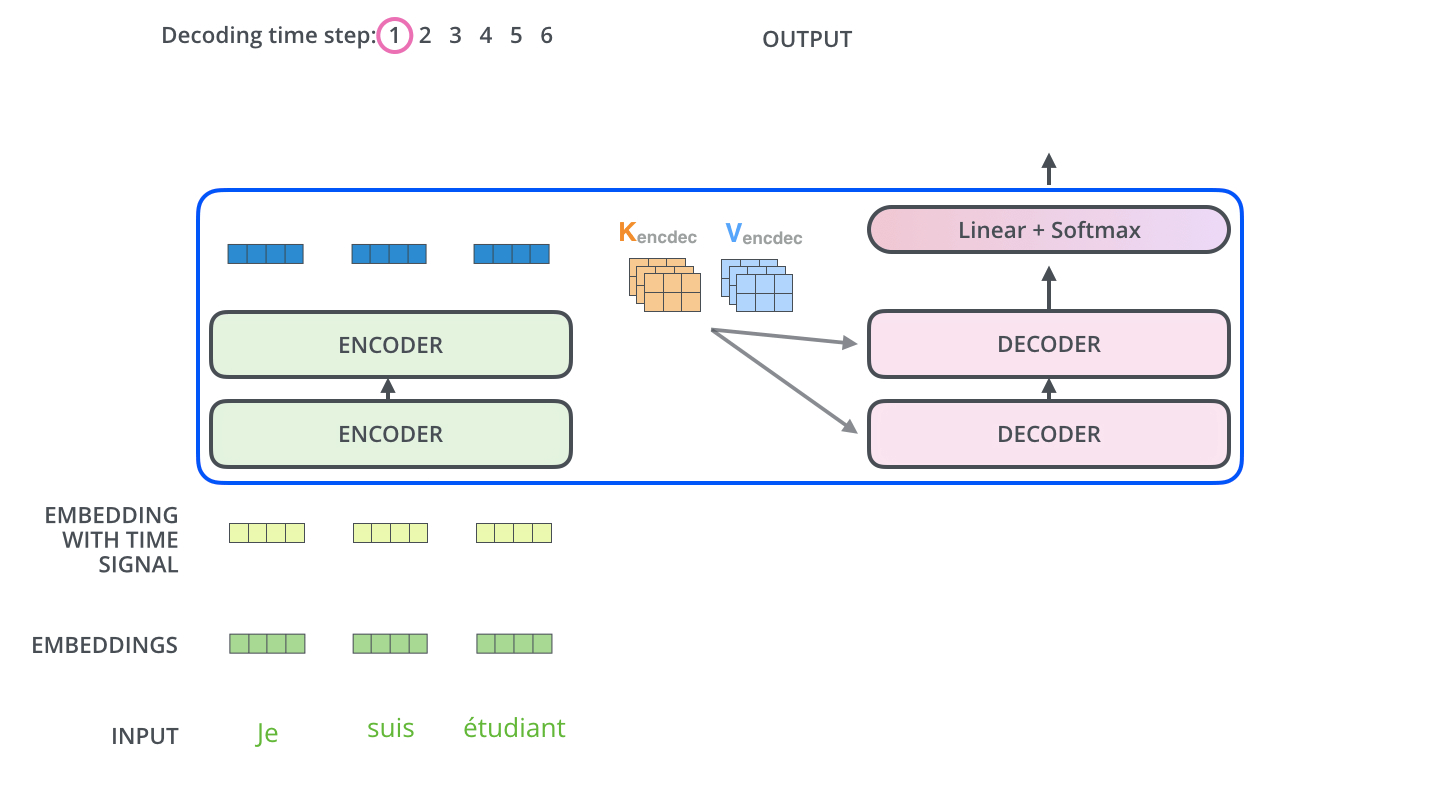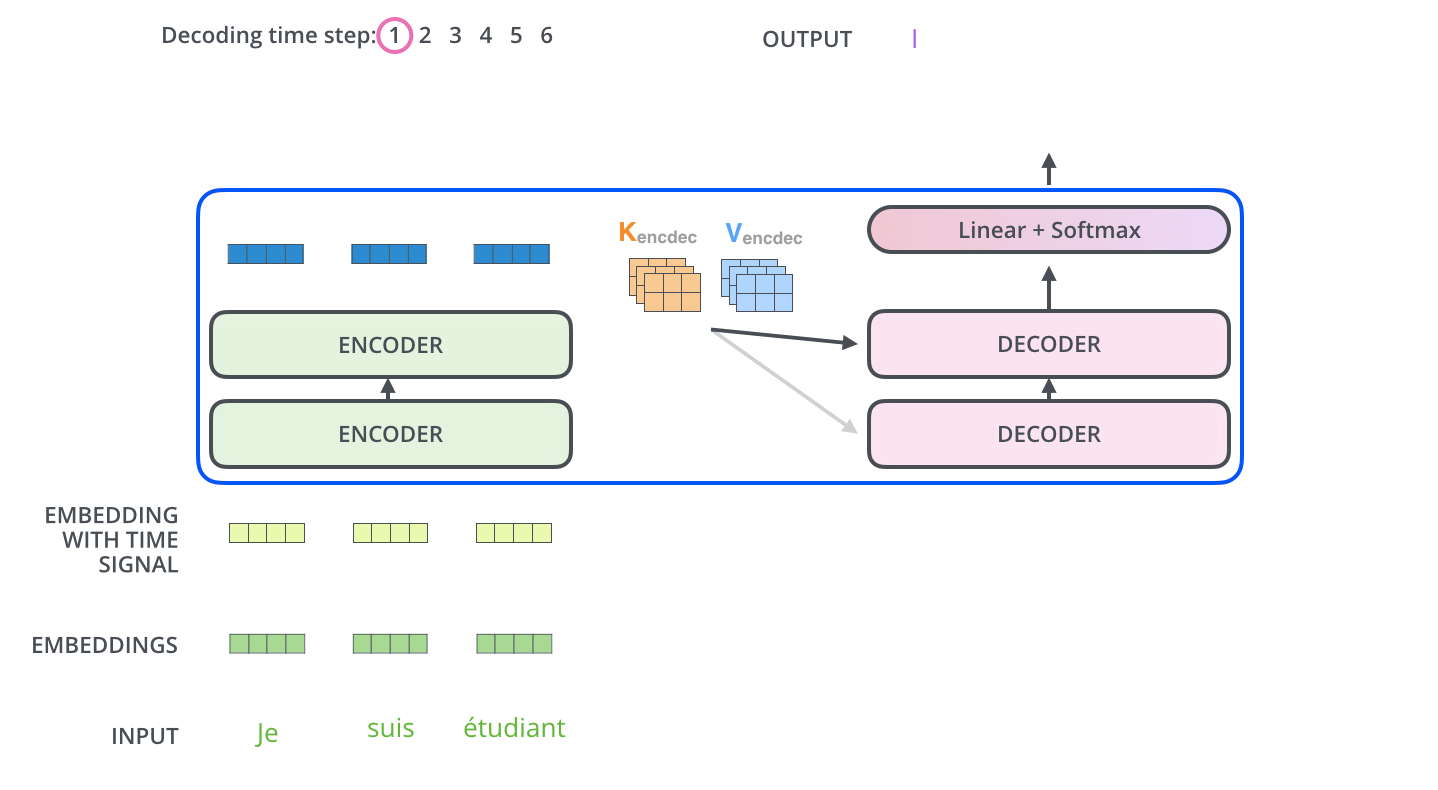
위의 과정은 <EOS>가 나올 때까지 반복된다. 각 스텝의 아웃풋이 가장 아래의 디코더에 주입되고, 디코더는 디코딩된 결과를 bubble up한다. 인코더가 그랬던 것 처럼 디코더의 인풋에 임베딩하고 임베딩 벡터에 positional 인코딩을 취해 각 단어의 위치를 가리킨다.
encoder-decoder attention 층은 multihead self-attention과 비슷하게 작동하지만, Query Matrix를 층 아래에 생성한다는 것과 K, V matrix만 인코더 스택의 아웃풋에서 취한다는 것에서 차이가 난다.
The Loss Function
‘merci’를 “thanks’로 바꾸는 작업을 한다고 해보자. 이 작업은 아웃풋이 확률 분포에서 thanks 단어를 가리키는 걸 원한다는 것을 뜻한다. 하지만 이 모델은 훈련되지 않았고, 제대로 번역되지 않을 것이다. 어떻게 잘 학습된 분포와 학습이 안된 분포를 비교할까? 간단하게, 하나를 잡고 다른 걸 빼면 된다. cross entropy나 Kullback-Leibler divergence를 살펴보자.
하지만 이 예는 너무 단순화한 예이다. 보통 우리는 문장단위의 번역을 한다. “je suis étudiant”를 “i am a student”로 번역한다고 해보자. 각 확률분포는 vocal_size의 길이로 표현된다. 여기서는
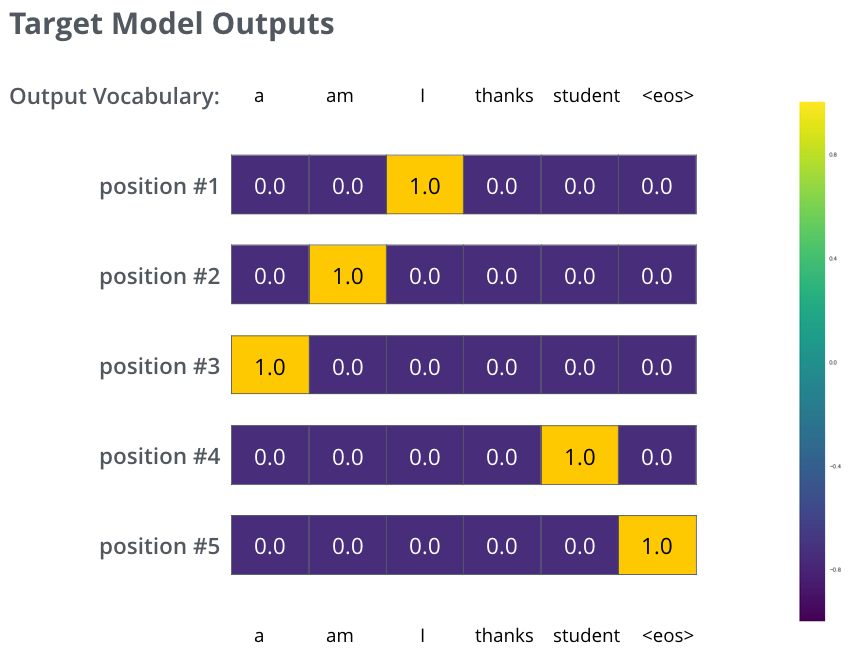
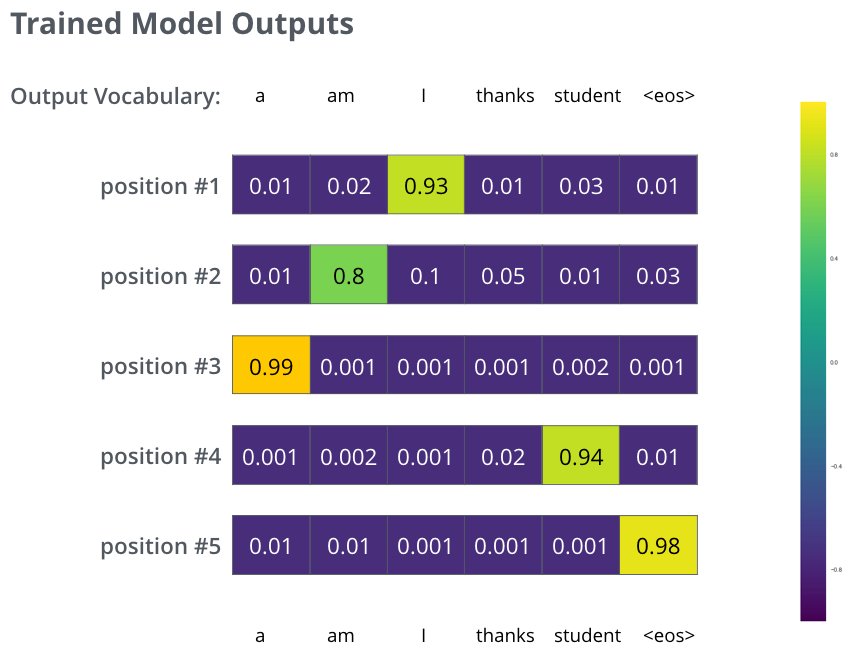
Reference
Jay Alammar : https://jalammar.github.io/
허민석님 유튜브 : https://www.youtube.com/watch?v=mxGCEWOxfe8&t=786s)
medium 글 : https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09
What is Transformer?