
pyspark trouble shooting, schema
pyspark로 작업 하던 중 파일이 읽히지 않는다면?????
cannot cast DOCUMENT into a ArrayType
Pyspark Trouble Shooting
간만에 pyspark로 작업할 일이 생겼다. 거의 한 달 만에 쓰는 거라 조금 어색했다. purchase관련 데이터와 view데이터를 갖고 작업을 해야 했었다. Purchase 데이터로 분석을 끝내고, view 데이터를 열어봤다. 파일이 커서 돌려놓고 dataframe을 만든 후 show()를 통해서 잘 불러왔는지 확인하려고 했었다.

cannot cast DOCUMENT into a ArrayType
자주 보지만 정이 안드는 친구가 등장했다. 도대체 이해가 되지 않았다. purchase데이터를 읽어올 때와 똑같은 방식으로 schema를 지정해줬고 변수명도 다 바꿔서 문제가 없을 줄 알았는데 에러가 발생한 것이다. DOCUMENT를 ArrayType으로 바꿀 수 없다는 내용인데… 왜 아까는 됐고 지금은 안되는지 참… 답답했다.
에러메세지를 복붙해서 구글을 뒤져봤지만, 문제를 해결할 만한 소스는 없었다. 결국 혼자 답을 찾아보기로 했다.
데이터의 구조
그 전에 사전지식으로 알아야 할 점은, 데이터가 어떻게 구성되어 있느냐이다. 글을 읽는 사람들의 이해를 돕기위해 간단하게 설명을 해보자면, purchase데이터에는 사용자의 구매내역이 들어있고 이는 purchase라는 칼럼에 잘 담겨있다. 구매내역이란 구매한 상품 내용, 상품의 갯수, 상품의 가격, 상품의 이미지 등등이 들어있다. 이 데이터는 한 칼럼에 담겨있으므로 묶어줄 수 있는 자료구조가 필요하다. 여기서 사용되는 자료구조는 list이며, 리스트 안에는 dictionary형태로 담겨 있다.
[{‘purchaseGoods’ : ‘값싸고질좋은 상품’}, …]
예를 들면 이런식으로 담겨 있는 것이다. pyspark로 데이터를 불러올 때는 schema를 지정해서 가져온다. list로 묶여있는 경우에는 ArrayType(list가 pyspark에서는 ArrayType으로 나타난다)으로 지정하고 이걸 purchase 데이터에 적용했을 때에는 너무나 잘 불러와졌었다. printSchema를 쳐봐도 잘 나왔다.
데이터의 차이점
view데이터를 불러오는 코드를 다시 들여보고 printSchema를 하니 역시 잘나왔다. spark의 신기한 점 중에 하나인데, spark는 직접 작업을 수행하는, collect나 show 등을 수행하기 전까지는 작업 스케쥴링만 해놓고 실제로는 돌지 않는다. 그렇게 지나가려는 순간 이상한 점을 발견했다.
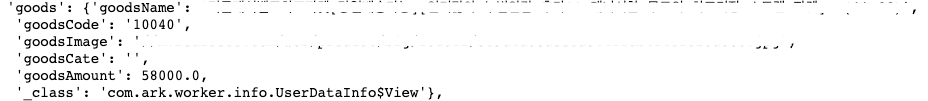

둘의 구조를 비교해보자. 뭔가 다른 점이 보인다. 위의 goods에서는 그냥 dictionary로 묶여있고, 밑에 있는 purchase에는 list로 묶여있다. 이 차이점 때문에 동일한 schema를 사용하게 되면 에러가 발생하게 되는 것이다.
list는 ArrayType으로 지정하면 된다면, dictionary는 무엇일까?
dictionary는 StructType으로 지정하면 된다. 스키마를 제대로 지정하고 나면 제대로 데이터가 나오게 된다.
purchase Schema
1 | purchaseSchema = StructType([ |
view Schema
1 | viewSchema = StructType([ |
추가로 이런 타입들을 지정할 때는
1 | from pyspark.sql import StructType, ArrayType |
이런식으로 불러와야 한다. import가 되지 않았다면, 에러가 발생한다.
pyspark trouble shooting, schema
http://tkdguq05.github.io/2020/05/10/trouble-shooting_pyspark/