
Kubernetes Beginning
자 이제 쿠버네티스에 대해 공부해보자. Docker in kubernetes, k8s architecture, cluster, and pods.
지난 글들로부터 가상화에 대해서 공부했고, 도커에 대해서 살펴봤습니다. 쿠버네티스는 가상화와 도커가 기본이 되는 시스템입니다. 가상화와 도커에 대해서 기억이 잘 나지 않는다면 잠시 보고 와도 좋습니다.
인프라의 기초, Docker에 대해서 알아보자.
클라우드 서비스의 기초. Virtualization, 가상화에 대해서
Kubernetes?
쿠버네티스를 최초로 만들고 사용한 곳은 구글입니다. 시스템에 배포 가능한 어플리케이션 구성 요소의 수가 많아지면서 모든 구성 요소의 관리가 어려워질 수 밖에 없기 때문입니다. 구글은 전 세계에서 소프트웨어 구성 요소와 인프라를 잘 배치하고 관리하는 방법이 필요하다는 것을 최초로 깨달은 회사일 것입니다. 수십만 대의 서버를 운영하고 엄청난 규모의 배포관리를 처리하는 기업입니다. 이로 인해 구글은 수천 개의 소프트웨어 구성 요소를 관리하고 비용 효율적으로 개발, 배포할 수 있는 솔루션을 개발해야만 했습니다. 그래서 등장한 것이 쿠버네티스의 전신인 보그-오메가 이며, 2014년에 구글은 쿠버네티스를 출시하게 됩니다. 구글이 만든 시스템답게 정말 잘 됩니다!
만약 구글이 모놀리스 어플리케이션으로 개발을 했다면 어땠을까요? 아마 이 정도의 확장은 불가능 했을 것 입니다. 모놀리스 어플리케이션이란 한 덩어리처럼 개발을 하는 것입니다. 큰 돌로 이루어진 건축물에 비유를 할 수 있습니다. 이와 반대되는 개념은 마이크로스서비스 기반 어플리케이션입니다. 이는 단일 역할을 책임지는 여러 조각으로 구성된 소프웨어로 구성되어 있습니다. 구글은 각 부분이 알아서 잘 돌아가는 MSA구조로 이루어져 있기 때문에 이렇게 확장할 수 있었습니다. 그리고 그것을 가능하게 해준 것이 바로 쿠버네티스입니다.
쿠버네티스는 컨테이너화된 어플리케이션을 쉽게 배포하고 관리할 수 있게 해주는 소프트웨어 시스템입니다. 어플리케이션은 컨테이너에서 실행되어 동일한 서버에서 실행되는 다른 어플리케이션에 영향을 주지 않아 동일한 하드웨어의 다른 조직의 어플리케이션이 실행될 때 영향을 주지 않습니다. 이를 통해 쿠버네티스를 사용하게 되면, 제공된 하드웨어를 최대한으로 사용할 수 있게 됩니다. 쿠버네티스를 활용하면 모든 노드가 하나의 거대한 컴퓨터 처럼 수천대의 노드에서 어플리케이션을 실행할 수 있습니다.
Kubernetes을 사용하면 좋은 점
먼저 개발자가 어플리케이션 핵심 기능에 집중할 수 있게 됩니다.
쿠버네티스를 클러스터의 운영체제로도 생각할 수 있습니다. 이렇게 되면 어플리케이션 개발자가 특정 인프라 관련 서비스를 어플리케이션에 구현하지 않아도 됩니다. 쿠버네티스를 활용하면 되니까요. 쿠버네티스에는 서비스 디스커버리, 스케일링, 로드밸런싱, 자가치유, 리더선출 같은 것들이 들어갑니다. 따라서 어플리케이션 개발자는 기능을 구현하는 데 집중을 하면 되고, 인프라에 관련된 고민을 하지 않아도 됩니다.
운영 팀이 효과적으로 리소스를 활용할 수 있습니다.
쿠버네티스는 클러스터에 컨테이너화된 어플리케이션을 실행하고 구성 요소들 간에 연결되는 방법에 대한 정보를 제공하며, 이를 이용해 모든 어플리케이션이 계속 실행되도록 합니다. 어플리케이션은 어떤 노드에서 실행되든 상관이 없기 때문에 쿠버네티스는 언제든지 어플리케이션을 재배치하고 조합함으로써 주어진 리소스를 잘 활용할 수 있게 됩니다.
Kubernetes Architecture
쿠버네티스 클러스터가 어떻게 구성되어 있는지 알아봅시다. 쿠버네티스는 두 가지 유형으로 나눌 수 있습니다. 마스터 노드와 워커 노드입니다.
- 마스터 노드는 쿠버네티스 컨트롤 플레인을 실행합니다. 컨트롤 플레인은 전체 쿠버네티스 시스템을 제어하고 관리합니다.
- 워커 노드는 실제 배포되는 컨테이너 어플리케이션을 실행합니다.
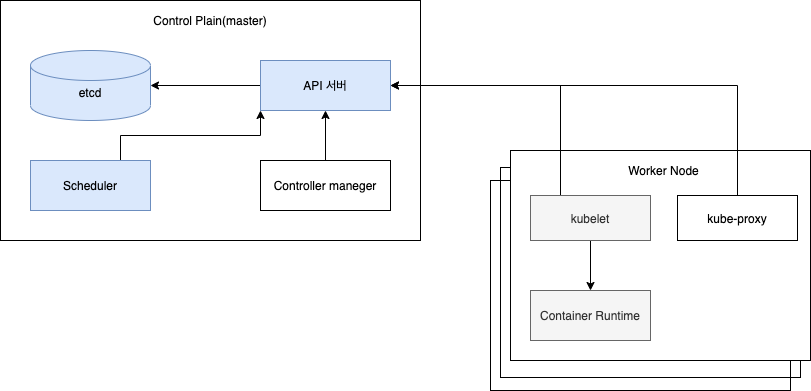
Control Plain
컨트롤 플레인은 클러스터를 제어하고 작동시키는 역할입니다. 하나의 마스터 노드에서 실행하거나 여러 노드로 분할되고 복제되어 고가용성을 보장할 수 있는 여러 구성 요소로 구성 되어 있습니다. 그 구성요소는 다음과 같습니다.
Kubernetes API 서버 : 사용자 , 컨트롤 플레인 구성 요소와 통신한다.
Scheduler : 어플리케이션의 배포를 담당한다.(스케쥴링이라는 용어는 파드가 특정 노드에 할당됨을 의미합니다.)
노드가 배정되지 않은, 새로 생성된 파드를 감지하고 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트입니다. 스케쥴링 결정을 위해서 고려되는 요소들은 다음과 같습니다.
- 리소스에 대한 개별 및 총체적 요구 사항
- 하드웨어/소프트웨어/정책적 제약
- 어피니티(affinity) 및 안티-어피니티(anti-affinity) 명세
- 데이터 지역성
- 워크로드-간 간섭
- 데드라인
Controller Manager : 컨트롤러 매니저는 구성요소 복제본, 워커 노드 추적, 노드 장애 처리 등과 같은 클러스터 단의 기능을 수행한다.
etcd : 클러스터 구성을 지속적으로 저장하는 신뢰할 수 있는 분산 데이터 저장소이다.
Node
워커 노드는 컨테이너화된 어플리케이션을 실행하는 시스템입니다. 어플리케이션을 실행하고 관리하며 서비스를 제공하는 작업은 다음 구성 요소에 의해 수행됩니다.
- Contianer Runtime : 컨테이너를 실행하는 도커나 rkt 등등
- kubelet : API 서버와 통신하고 노드의 컨테이너를 관리한다.
- kubelet은 파드를 관리한다고 생각하면 됩니다. 클러스터의 각 노드에서 실행되는 에이전트로 kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리합니다. kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 원할하게(Health) 동작하게 합니다. kubelet은 쿠버네티스를 통해 생성되지 않은 컨테이너는 관리하지 않습니다.
- kube-proxy : 어플리케이션 구성 요소 간에 네트워크 트래픽을 로드밸런싱한다.
- kube-proxy는 클러스터의 통신을 담당합니다. 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스 개념의 구현부입니다. kube-proxy는 노드의 네트워크 규칙을 유지 관리합니다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 밖에서 파드로 네트워크 통신을 할 수 있도록 해줍니다.
kube-proxy는 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용합니다. 그렇지 않으면 kube-proxy는 트래픽 자체를 forward합니다.
- kube-proxy는 클러스터의 통신을 담당합니다. 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스 개념의 구현부입니다. kube-proxy는 노드의 네트워크 규칙을 유지 관리합니다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 밖에서 파드로 네트워크 통신을 할 수 있도록 해줍니다.
Kubernetes cluster가 상호작용하는 방법
클러스터는 마스터와 노드들로 구성이 되어있고 각 노드들은 도커, kubelet, kube-proxy 데몬을 실행합니다. 우리가 설치한 kubectl 명령어를 실행하면 마스터 노드에 쿠버네티스 API 서버로 REST요청을 보내서 클러스터와 상호작용하게 됩니다.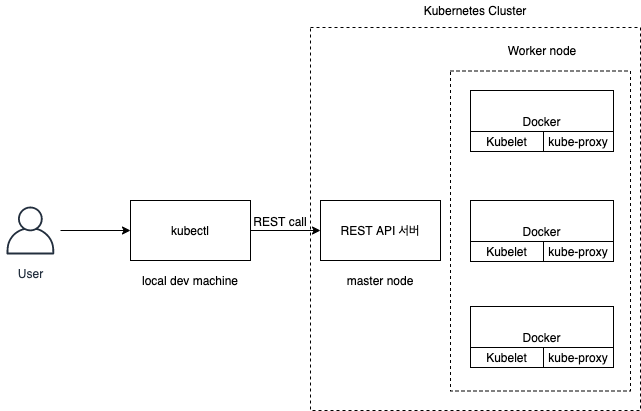
1 | $ kubectl get nodes |
이제 명령어로 node들을 확인할 수 있습니다.
이렇게 간단하게 쿠버네티스 클러스터 구조에 대해 살펴봤습니다.
Docker in Kubernetes
지난 번 도커 글을 연장해서 쿠버네티스로 이어지는 흐름을 만들어보겠습니다. 지난 도커 글에서는 간략한 소개만 했기 때문에 이미지와 이미지 레이어에 대한 이야기를 깊게 못해서 조금 더 설명을 해보겠습니다.
Docker Image
우리가 어떤 어플리케이션을 만들었다고 가정합시다. 이 어플리케이션을 이미지로 구성해서 내 환경과 같이 만들어, 어떤 환경에서 누구나 작업하게 만들고 싶습니다. 이렇게 이미지로 패키징하기 위해서는 Dockerfile을 만들어야 합니다. 이 파일에는 도커가 이미지를 생성하기 위해 수행해야 할 지시 사항들이 담겨져 있습니다. 이 Dockerfile은 .py와 같은 파일과 같은 위치에 있어야 합니다. Dockerfile을 살펴보겠습니다.
책 Kubernetes in Action의 예제를 사용하겠습니다.
1 | FROM node:7 |
FROM은 기본 이미지로 사용할 컨테이너 이미지를 정의합니다. ADD는 로컬 디렉토리의 app.js 파일을 이미지의 루트 디렉토리에 동일한 이름으로 추가한다는 뜻입니다. ENTRYPOINT는 이미지를 실행했을 때 수행돼야 할 명령어를 나타냅니다.
1 | $ docker build -t <name> . |
이 명령어를 이용하면 이름대로 이미지가 빌드됩니다. 도커에게 현재 디렉토리의 컨텐츠를 기반으로 이름으로 적힌 이미지를 빌드하라고 요청합니다. 도커는 Dockerfile을 보고 명령에 기반해 이미지를 빌드합니다. 이미지가 컴퓨터에 저장돼 있지 않으면, 도커는 Docker Hub에서 이미지를 다운 받습니다. 도커의 이미지는 하나의 큰 덩어리 파일이 아니라 여러개의 레이어로 구성됩니다. 그래서 빌드를 할 때 필요한 이미지가 있다면 필요한 이미지 레이어만 다운로드 하는 것 입니다.
도커 이미지를 배포하는 것은 저번 글에서 설명을 했습니다. 이제 컨테이너 이미지에 어플리케이션을 패키징하고 도커 허브를 통해 사용할 수 있게 됐습니다.
1 | $ docker tag kubia luksa/kubia |
이제 쿠버네티스 클러스터에 어플리케이션을 배포할 수 있게 됐습니다. 배포를 위해서는 쿠버네티스 클러스터가 필요합니다.
쿠버네티스 클러스터를 구성하는 법은 다양합니다. mini kube를 설치하는 방법도 있고, AWS에 EKS나 GCP를 이용해서 node를 만들고 쿠버네티스 환경을 만들 수 있습니다. 각자의 환경이 구성되었다고 가정하고 진행하겠습니다.
Kubernetes client 설치
kubectl CLI 클라이언트가 있어야 쿠버네티스를 다룰 수 있습니다.
1 | * 리눅스 기준 |
kubectl 정보가 나오면 성공입니다.
이제 아까 전에 만든 node.js 어플리케이션을 구동해 보겠습니다.
1 | $ kubectl run kubia --image=luksa/kubia --port=8080 --generator=run/v1 |
–image=luksa/kubia 부분은 실행하는 컨테이너 이미지를 명시하는 것이며, -port=8080은 쿠버네티스에 어플리케이션이 8080포트를 수신 대기해야 한다는 것을 알려줍니다. –generator부분은 디플로이먼트 대신 레플리케이션컨트롤러를 생성하기 때문에 사용했습니다. 레플리케이션 컨트롤러는 조금 이따 설명하겠습니다.
백그라운드에서 무슨 일이 일어나고 있는 것일까?
일단 지금 무슨 일이 일어난 것인지 설명해보겠습니다. 현재 도커 이미지를 푸시해서 도커 허브에 공유해놓았고 공유된 이미지를 가져와서 kubectl을 이용해 구동했습니다. kubectl 명령은 쿠버네티스의 API서버로 REST http요청을 전달하고 클러스터에 새 레플리케이션 컨트롤러 오브젝트를 생성합니다. 레플리케이션 컨트롤러는 새 파드를 만들고 스케쥴러에 의해 워커 노드 중 하나에 스케줄링을 완료합니다. kubelet은 파드가 할당된 것을 보고 이미지가 로컬에 없는 것을 확인합니다. 이미지를 받기 위해 도커에게 특정 이미지를 풀하도록 지시하고 luksa/kubia 이미지를 받은 후 도커는 컨테이너를 이미지를 이용해 생성하고 실행합니다.
과정을 살펴봤듯이, 우리가 직접 컨테이너를 직접 생성하거나 동작하지 않습니다. 파드만을 이용했습니다. 하지만 파드도 직접 만들지 않았고 쿠버네티스에서 알아서 잘 만들었습니다. kubectl run을 하면 레플리케이션 컨트롤러를 생성하고 이것이 실제 파드를 만들어 냅니다. 클러스터 외부에서 파드에 접근하기 위해 쿠버네티스에게 레플리케이션 컨트롤러에 의해 관리되는 모든 파드를 단일 서비스로 노출하도록 명령합니다. 결국 쿠버네티스의 시스템은 레플리케이션 컨트롤러, 파드, 서비스로 구성됩니다.
가장 중요한 구성요소는 파드입니다.
여기서 파드는 하나의 컨테이너를 갖고 있지만, 보통 파드는 원하는 갯수의 컨테이너를 가질 수 있습니다. 컨테이너 내부에는 현재 Node.js 프로세스가 있고 포트 8080에 바인딩 되어 http요청을 기다리고 있습니다. 파드는 자체의 고유한 private ip와 host name을 갖습니다.
레플리케이션 컨트롤러를 살펴보겠습니다.
레플리케이션 컨트롤러는 항상 정확히 하나의 파드 인스턴스를 실행하도록 지정합니다. 보통 파드를 복제하고 항상 실행 상태로 만듭니다. 여기서는 파드의 replicas를 지정하지 않았습니다. 따라서 파드를 하나만 생성했습니다. 어떤 장애 등의 이유로 파드가 죽어버리면 레플리케이션 컨트롤러는 지정된 파드 수를 채우기 위해 새로운 파드를 생성할 것입니다.
이제 서비스를 살펴보겠습니다.
kubia-http 서비스가 필요한 이유를 알기위해 파드의 주요 특성을 더 이해해 볼 필요가 있습니다. 파드는 영원하지 않습니다. ephemeral하기 때문에 사라질 수 있습니다. 파드가 죽어버릴 수 있고 누군가 파드를 kill할 수도 있으며, 비정상 노드에서 파드가 제거될 수 있습니다. 물론 사라지면 레플리케이션 컨트롤러에 의해서 다시 새 파드로 대체됩니다. 중요한 것은 새 파드는 다른 IP주소를 할당받는 다는 것입니다. 그렇기 때문에 서비스가 필요합니다. 서비스를 이용하면, 파드의 IP주소가 바뀌는 문제와 여러 개의 단일 파드를 단일 IP와 포트의 쌍으로 노출하는 문제를 해결할 수 있습니다.
서비스가 생성되면 정적 IP를 할당받습니다. 그리고 서비스가 있는동안 변경되지 않습니다. 파드에 직접 연결해야 하지만 클라이언트는 서비스의 IP 주소를 통해 연결해야 합니다. 서비스는 어떤 파드가 어떤 IP를 받는지 상관없이 파드 중 하나로 연결해 요청을 처리합니다.
서비스는 동일한 서비스를 제공하는 하나 이상의 파드 그룹의 정적인 위치를 나타냅니다. 서비스의 IP와 포트로 요청이 들어오면 그 순간 서비스에 속해 있는 파드 중 하나로 요청을 전달하게 됩니다.
Pod
쿠버네티스에 대해서 조금이라도 본 사람은 파드에 대해서도 들어본 적이 있을 것입니다. 파드는 노드 안에 구성된 여러개의 컨테이너를 가질 수 있는 컨테이너의 그룹입니다. 쿠버네티스는 개별 컨테이너를 직접 다루지 않고 파드를 다룹니다. 이 파드들은 kubectl로 조회할 수 있습니다.
1 | $ kubectl get pods |
혹시 파드의 상태가 Pending상태라면 파드의 단일 컨테이너가 준비가 되지 않은 것이다. 할당된 워커 노드가 컨테이너를 실행하기 전에 컨테이너 이미지를 다운로드하는 중이기 때문일 수도 있고, 리소스 부족일 수도 있다. 조금 기다려본 후 계속 pending으로 나온다면 리소스를 늘려주면 된다. 다운로드가 완료되고 파드의 컨테이너가 생성되면 Running으로 나온다. 파드에 대해서는 간단히 설명하고 나중에 따로 깊게 다뤄 보도록 하겠습니다.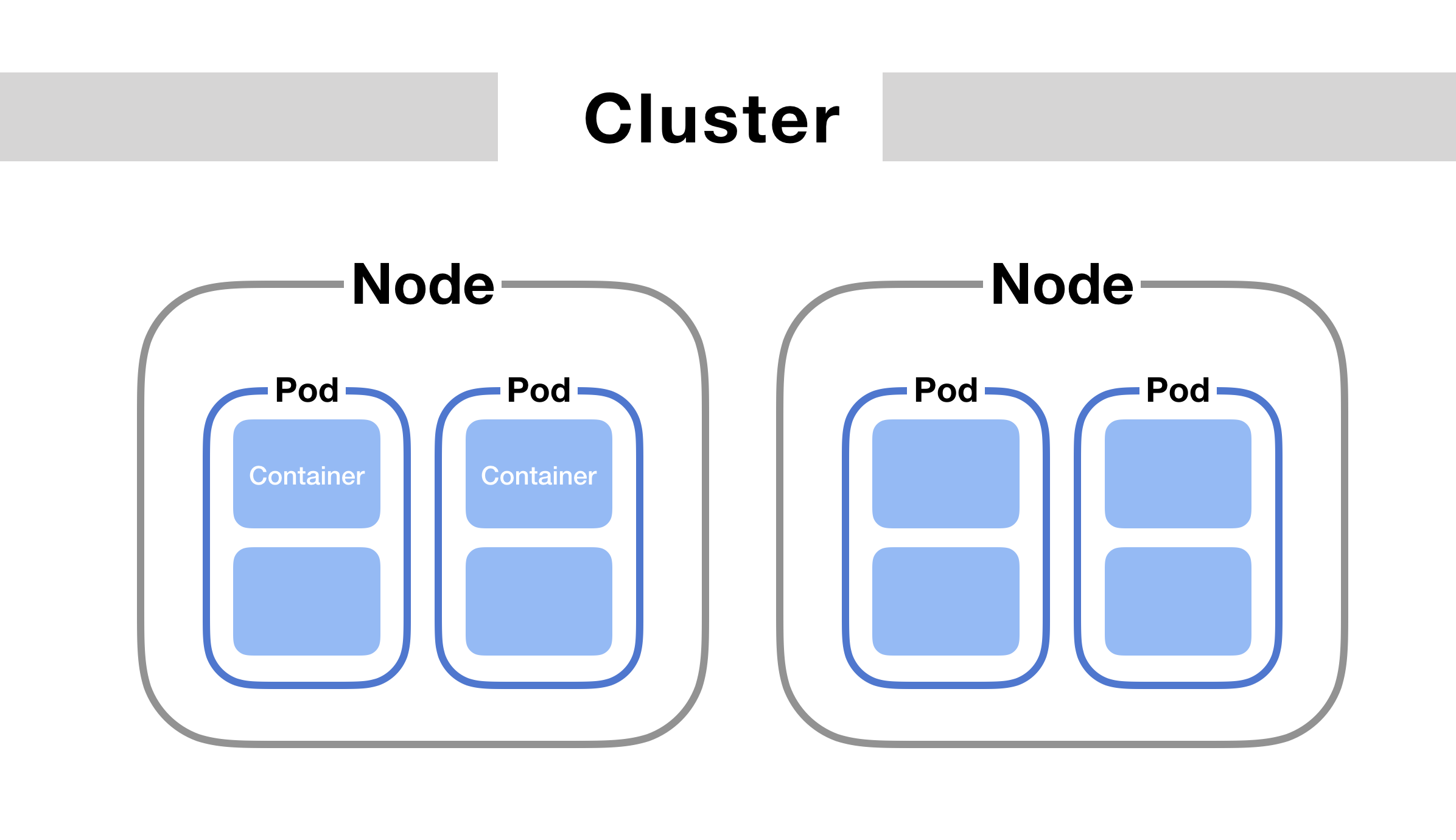
Summary.
쿠버네티스에 대해서 공부한 내용을 간단하게 요약해 보겠습니다.
- 모놀리스 어플리케이션은 처음에 구축하기 쉽지만 가면 갈수록 유지 관리하기가 힘들고 확장이 불가능해 집니다.
- 마이크로서비스 기반 어플리케이션 아키텍쳐는 각 구성 요소의 개발을 요이하게 하지만 하나의 시스템으로 작동하도록 배포하고 구성하기 어렵습니다.
- 쿠버네티스는 전체 데이터 센터를 어플리케이션 실행을 위한 컴퓨팅 리소스로 제공하게 합니다.
- 쿠버네티스를 통해서 개발자는 시스템 관리자의 도움 없이도 어플리케이션을 배포할 수 있게 됩니다.
- 쿠버네티스를 통해서 시스템 관리자는 쿠버네티스가 고장 난 노드가 자동으로 처리되게 함으로써 더 편하게 잠을 잘 수 있게 됩니다.
- 쿠버네티스는 마스터 노드와 워커 노드로 이루어져있습니다.
- 어플리케이션을 컨테이너 이미지로 패키징하고 원격에 푸시해 누구나 사용하게 할 수 있습니다.
- 쿠버네티스는 파드를 이용해 어플리케이션을 배포합니다.
여러 내용을 전달하려고 하다보니 글이 장황해진 것 같습니다. 다음 글에서는 파드에 대해서 더 깊게 알아보고 네임스페이스로 파드를 겹치지 않는 그룹으로 나누는 방법을 살펴보겠습니다.
Kubernetes Beginning