
SISG를 활용한 Fasttext에 대해서 알아보자
자연어 처리 모델에 자주 사용되는 FastText를 뽀개보고 skipgram 모델과의 차이를 알아보자.
Fasttext
출처 : Wikipedia
fastText는 Facebook의 AI Research lab에서 만든 단어 임베딩 및 텍스트 분류 학습을 위한 라이브러리입니다. 이 모델을 사용하면 단어에 대한 벡터 표현을 얻기 위해 비지도 학습 또는 지도 학습 알고리즘을 만들 수 있습니다.
Fasttext는 위키피디아 설명에서 보듯이 Facebook에서 만들었고 그에 걸맞게 임베딩도 잘되고 성능도 우수한 편인 모델입니다. 실제로 지금 있는 회사에서도 자연어 처리를 할 때 Word2Vec이나 Fasttext의 도움을 받고 있습니다.
오늘 살펴볼 내용은 Fasttext가 어떻게 학습을 하는지, 그리고 Skip gram 모델과 어떤 차이점이 있는지 입니다.
자연어 모델이나 Sequential 딥러닝 모델을 한번 쭉 살펴보신 분들은 이해가 빠를 수 있습니다. 하지만 글은 어렵지 않으니 천천히 따라오면 잘 이해할 수 있을 것입니다. 있을 것이라고 믿습니다.
Introduction
기존의 embedding model은 unique word를 하나의 vector에 할당할 수 있었습니다. 그러나 이와 같은 방식은 vocabulary의 크기가 커지거나 rare word(못 봤었던 단어)가 많을수록 한계점을 내포하게 됩니다. 한계점이란 이러한 word들은 good word representation을 얻기 힘들다는 점입니다. 특히 현재까지의 word representation 기법들은 문자의 internal structure를 고려하지 않고 있기 때문에 학습이 더욱 힘들었습니다. 더 나아가 스페인어나 프랑스어의 경우 대부분의 동사가 40개 이상의 변형된 형태를 지니고 있는 복잡한 언어이기 때문에, 이러한 언어에서는 rare word 문제가 더욱 부각 됩니다. 이런 이유로 이처럼 형태학적인 특징이 풍부한 언어의 경우에는 subword 정보를 활용하여 rare word에 대한 한계점을 극복하고자 합니다. subword를 이용해서 vector representation을 개선시키고자 하는 것입니다.
General Model, Skip-gram
먼저 일반적인 모델인 skip-gram의 프로세스를 알아야 fasttext에 대해 잘 알 수 있습니다.
스킵 그램은 그림에서처럼 window size의 단어들을 슬라이딩 해 가면서 타겟 단어에 대해서 주변 단어들이 올 확률을 구해 나갑니다. 파란색으로 표시된 것이 타겟 단어이며 주위 단어들이 context word, 즉 주변 단어입니다. $w_t$와 $w_c$로 표현됩니다. 여기에 가정이 하나 추가되는데, context word는 조건부 독립(conditionally independent)이라는 가정입니다.

위의 그림은 아까 살펴봤었던 과정을 모델의 관점에서 자세히 살펴보겠습니다. 레이어의 구성은 인풋 레이어, 히든 레이어, 아웃풋 레이어로 되어있습니다. 인풋 레이어에는 단어들이 들어가고 히든 레이어에는 타겟 단어에 대한 벡터값이 남습니다. 아웃풋 레이어 까지 거치게 되면 가중치 벡터들과 예측한 값이 나오게 되고 가중치 벡터에는 타겟단어와 주변단어들에 대한 가중치들이 저장되어 있습니다. 예측된 결과를 실제 값과 비교해서 각 단어들에 대한 loss값을 뽑아내게 되고 이것을 더하면 전체 loss값이 됩니다.
숫자를 통해서 이를 더 구체화 해보면 다음과 같습니다.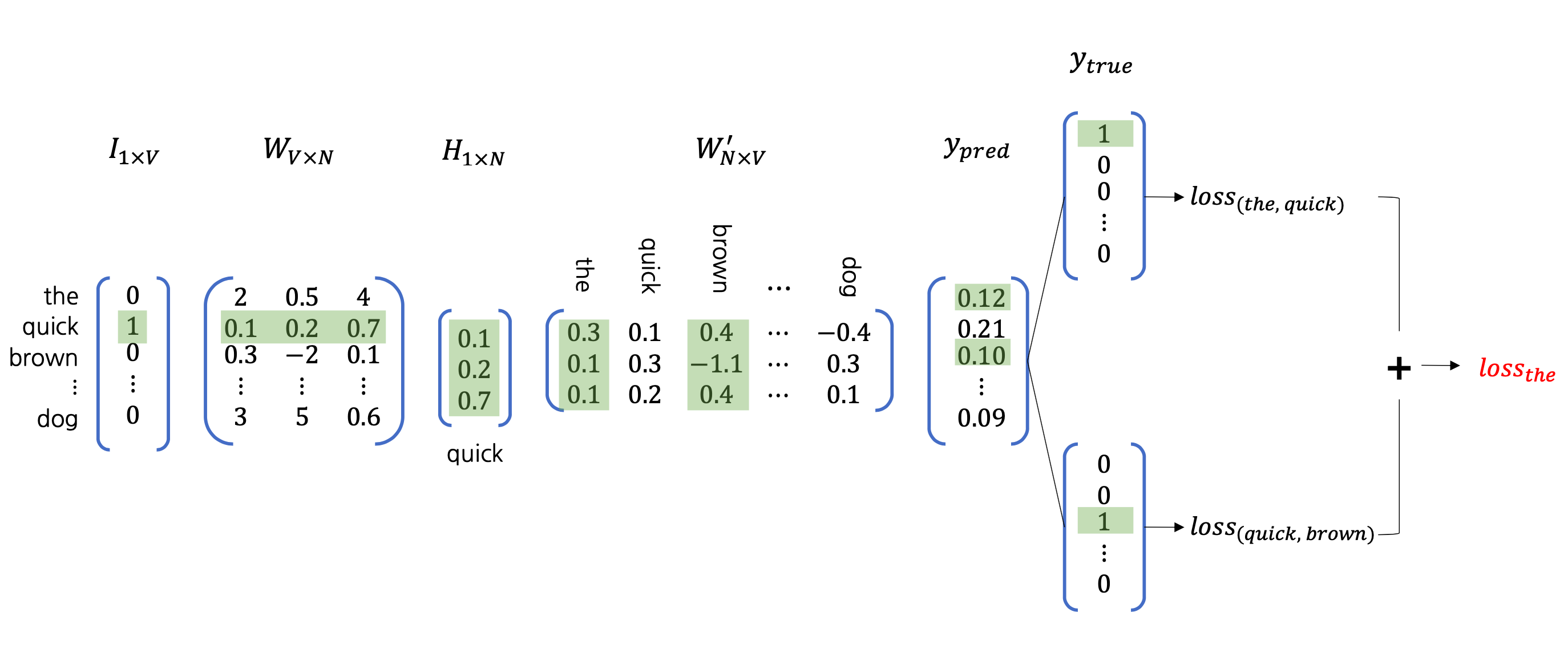
이렇게 계산되는 과정을 살펴보다 보면, 비효율적인 부분들이 발견됩니다. 어디일까요? 문제점을 발견하고 개선시켜나가 보겠습니다.
Improvement
1. Row Indexing
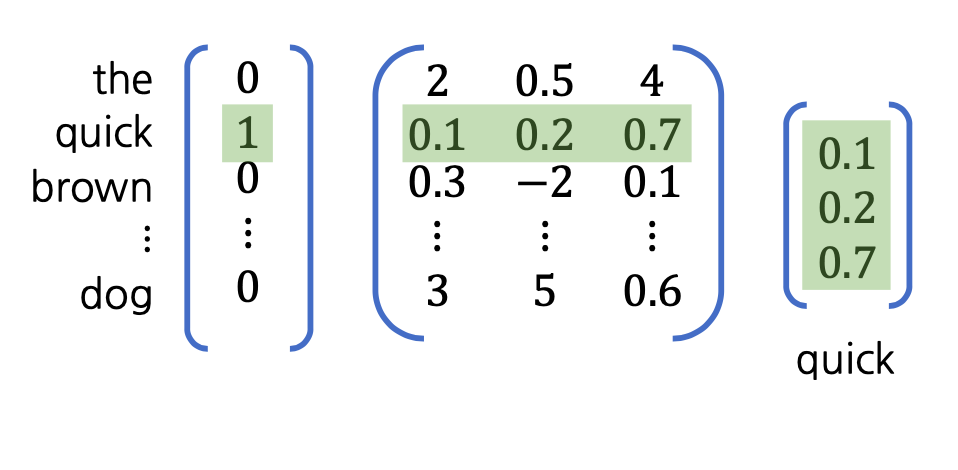
맨 처음 인풋이 들어간 부분과 $W_{input}$을 통해서 타겟에 대한 벡터값을 얻게 됩니다. 만약 들어가는 인풋 단어가 엄청나게 많다면 어떻게 될까요? 수 많은 계산을 일일이 해주어야 합니다. 하지만, 생각을 한번 바꿔보면 어떨까요? 인풋 단어들은 one-hot index로 되어 있습니다. 따라서 $W_{inpit}$의 row index를 그냥 가져오기만 하면 되지 않을까요?
이렇게 row index를 가져오면 계산을 효과적으로 줄일 수 있습니다. 결과적으로는 같지만 처리해야할 연산이 획기적으로 줄게 되는 것입니다.
2. Negative Sampling

이번엔 다음부분으로 넘어가 봅시다. 어떤 부분이 비효율적일까요?
히든 레이어인 $h$와 $W_{output}$의 곱하는 부분과 softmax 계층의 병목이 보입니다. 생각해봅시다. latent vector $h$와 $W_{output}$도 역시 단어들이 많아지면 연산을 많이 처리해야 합니다. softmax 계층도 마찬가지입니다. 그러나 하나의 target word와 관련된 context word들은 window size내의 작은 word 정도밖에 안됩니다. 전체 단어를 굳이 다 처리해야 할 필요가 없는 것입니다. 즉, $h$와 $W_{output}$의 행렬 곱 연산은 인풋과 관련되어 있기 때문에 업데이트 되어야 할 단어는 몇 개 안되는데도 불구하고, vocabulary에 있는 모든 단어들과의 관계를 비교해야합니다. 여기서 비효율성이 발생하게 됩니다.
이를 해결하기 위해 Negative Sampling이 제안됩니다. Negative Sampling의 핵심은 지금의 multi-clas classification 문제를 간단한 binary classification 문제로 바꾸는 것입니다. 어떻게 바꿀까요?
How to Negative Sampling
먼저 알아야할 개념이 있습니다.
- positive example: target word의 context word
- negative example: target word의 context word가 아닌 word
우리는 context word를 1로 처리할 것이고, 아닌 단어들은 0으로 처리할 것입니다. 연산을 줄이기 위함입니다.
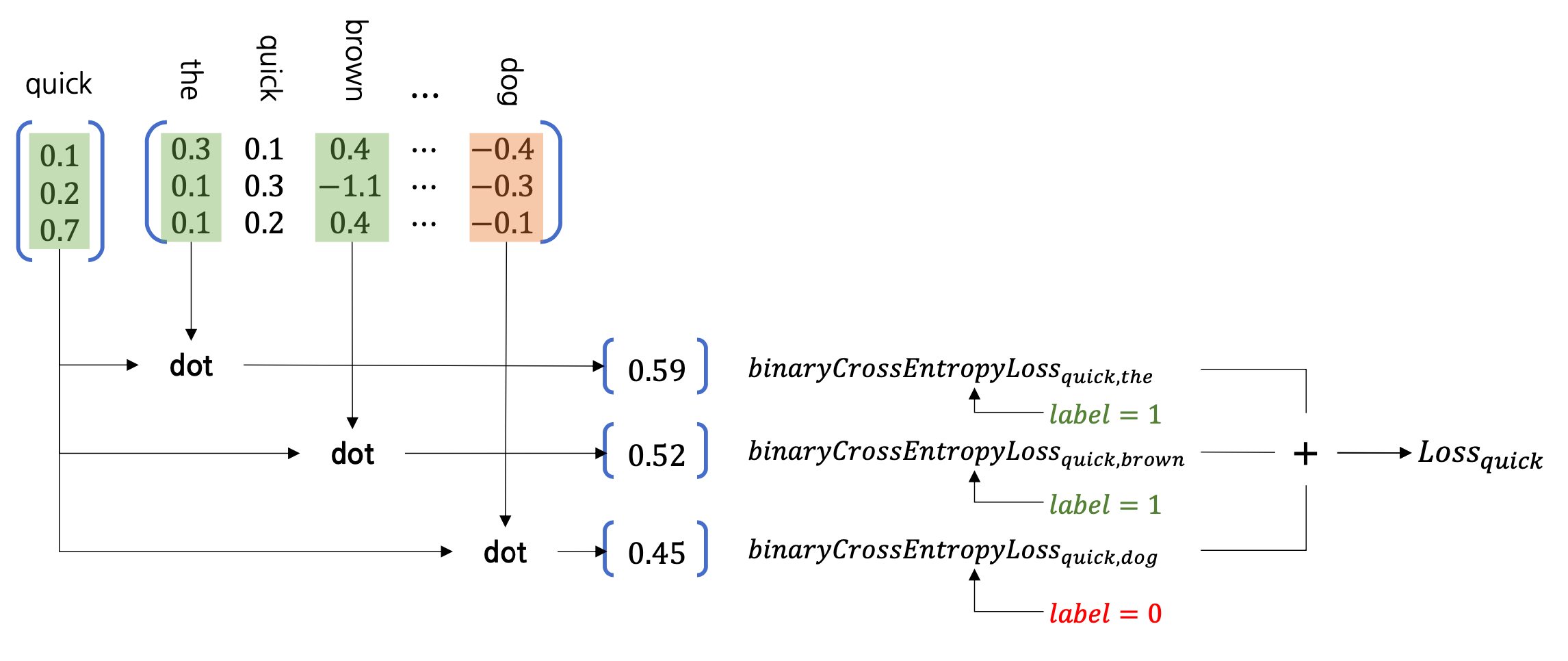
예를 들어보겠습니다. 위의 그림에서 dot product된 결과가 나오고 있습니다. (숫자는 임의로 입력한 값입니다) positive example들은 초록색으로 표시되어 label을 1로 처리하고, negative example들은 주황색으로 표시되어 label을 0으로 처리합니다. 이렇게 연산을 줄여서 처리한 뒤에 로스를 계산합니다. 단어가 많으면 많아질수록 줄어드는 연산의 양이 커질 것입니다. 그렇다면 의문점이 또 생깁니다. negative sampling을 하는 단어를 어떻게 정할까요?
Negative Sampling은 Corpus 내에서 자주 등장하는 단어를 더 많이 추출하고 드물게 등장하는 단어는 적게 추출하고자 합니다. 이 목적을 달성하기 위해서 Probability distribution을 이용하는데 수식은 다음과 같습니다.
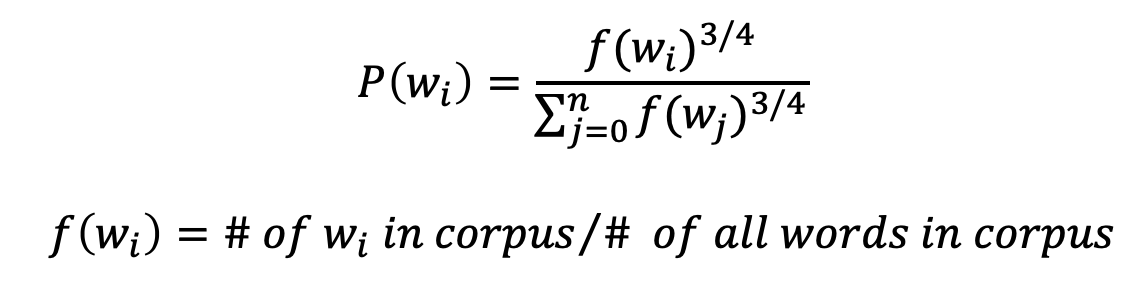
$f(w_i)$는 모든 corpus의 단어 중에서 특정 단어 $w_i$가 얼마나 들어있는지를 의미합니다. 따라서 위의 식에서 $P(w_i$은 전체 코퍼스에서 특정단어 $w_i$가 얼마나 있는지를 나타내는 식입니다. 빈도 수와 관계가 있다고 할 수 있겠습니다. 그러면 왜 $3\over4$ 라는 숫자를 사용할까요? 증명된 것은 없습니다. 논문에서 이 숫자를 사용했을 때 잘 되었던 것입니다. 이 파라미터는 수정이 가능하니 데이터에 맞게 조정하면 됩니다.

우리가 지금까지 했었던 것을 간단하게 정리해 보겠습니다.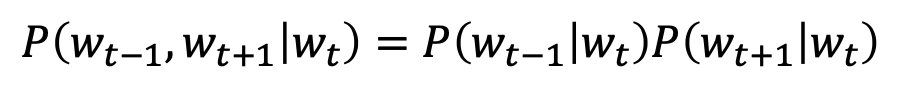
우리는 이 가정에서 출발했습니다. 가정을 이용해서 skip-gram 모델을 만들었습니다. 효율적으로 처리하기 위해 skip그램에 Row indexing을 사용했고 Negative sampling을 사용했습니다. 이를 통해서 우리가 얻고자 한 것은 다음의 수식입니다.
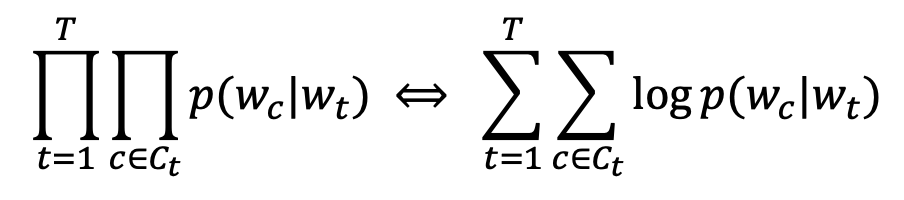
원래는 왼쪽의 수식의 값을 최대화 하는 것이었지만, 단어의 수가 많아지면 오른쪽의 수식으로 변경해 log-likielihood를 최대화 합니다.
context word가 올 확률에 대해서는 다양한 선택이 있겠지만 연산 후의 softmax 결과 값을 사용합니다.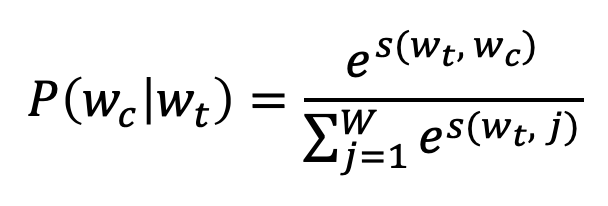
하지만 우리는 negative sampling을 통해 Multiclass Classification 문제를 Binary Classification로 변경했습니다. 결국 위의 softmax는 context 단어들의 존재 여부를 독립적으로 얘측에 대한 확률이 됩니다.
negative sampling에 의해서 골라진 contex word에 대한 포지션은 $c$로 표현됩니다. Binary Logistic loss에 의해서, 우리는 다음과 같은 negative log likelihood 값을 얻을 수 있습니다.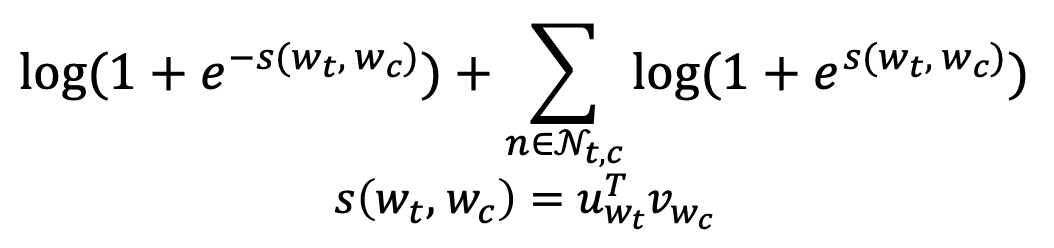
밑 부분의 score값인 $s(w_t,w_c)$를 주의해서 봐주시기 바랍니다.
이제 모든 타겟 단어에 대해서 다음과 같은 수식으로 정리가 되면, skip gram model에 대한 설명은 끝납니다.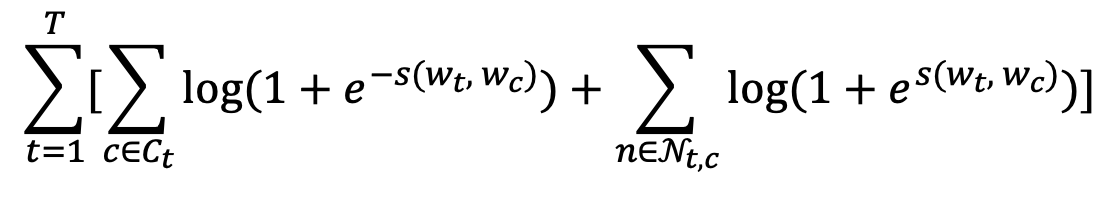
Fasttext, SISG
Fasttext는 skip gram모델을 개선한 모델입니다. SISG(Subword Information Skip Gram)를 이용해 Skip gram모델의 성능을 개선합니다. SISG란 무엇일까요?
SISG(Subword Information Skip Gram)
SISG는 간단한 개념입니다. 각 단어 $w$는 n-gram의 bag을 담고 있다고 해봅시다. 이제 여기에 <와 >를 이용해서 단어의 시작과 끝을 알려줄 것입니다. 한 가지 더 단어 그 자체를 넣어 줄 것입니다. 각 단어 자체의 표현을 학습시키기 위함입니다. where이라는 단어의 처리에 관한 예를 들어봅시다.
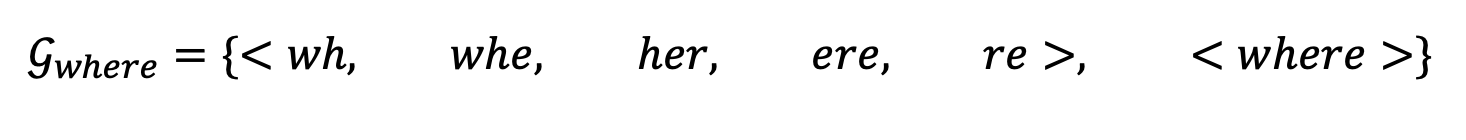
n=3일 때의 예시입니다. 위의 예시처럼 <,>를 한 글자씩 처리해서 나누면 re>로 끝나게 됩니다. 그런데 여기에 <where>도 같이 넣어주는 것이 핵심입니다. 이유를 생각해봅시다. 중간에 her이란 단어가 눈에 띄었을 겁니다. her는 단어로 처리되어야 할까요? 아닙니다. her은 그냥 단어의 조각일 뿐이며 subword에 해당됩니다. 진짜 단어였다면 <her>로 표현이 되어야 할 것입니다.
이렇게 만든 후에 n-gram의 벡터표현을 모두 더한 score 값을 구하면, 그것이 바로 SISG의 목적 함수가 됩니다. 아까 봤던 score함수가 바뀌었습니다. score함수만 바꿔주면 fasttext의 목적합수 입니다.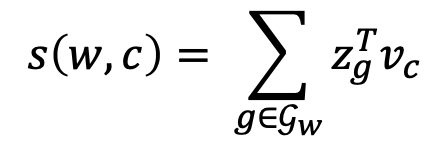
이를 pseudo code로 나타내면.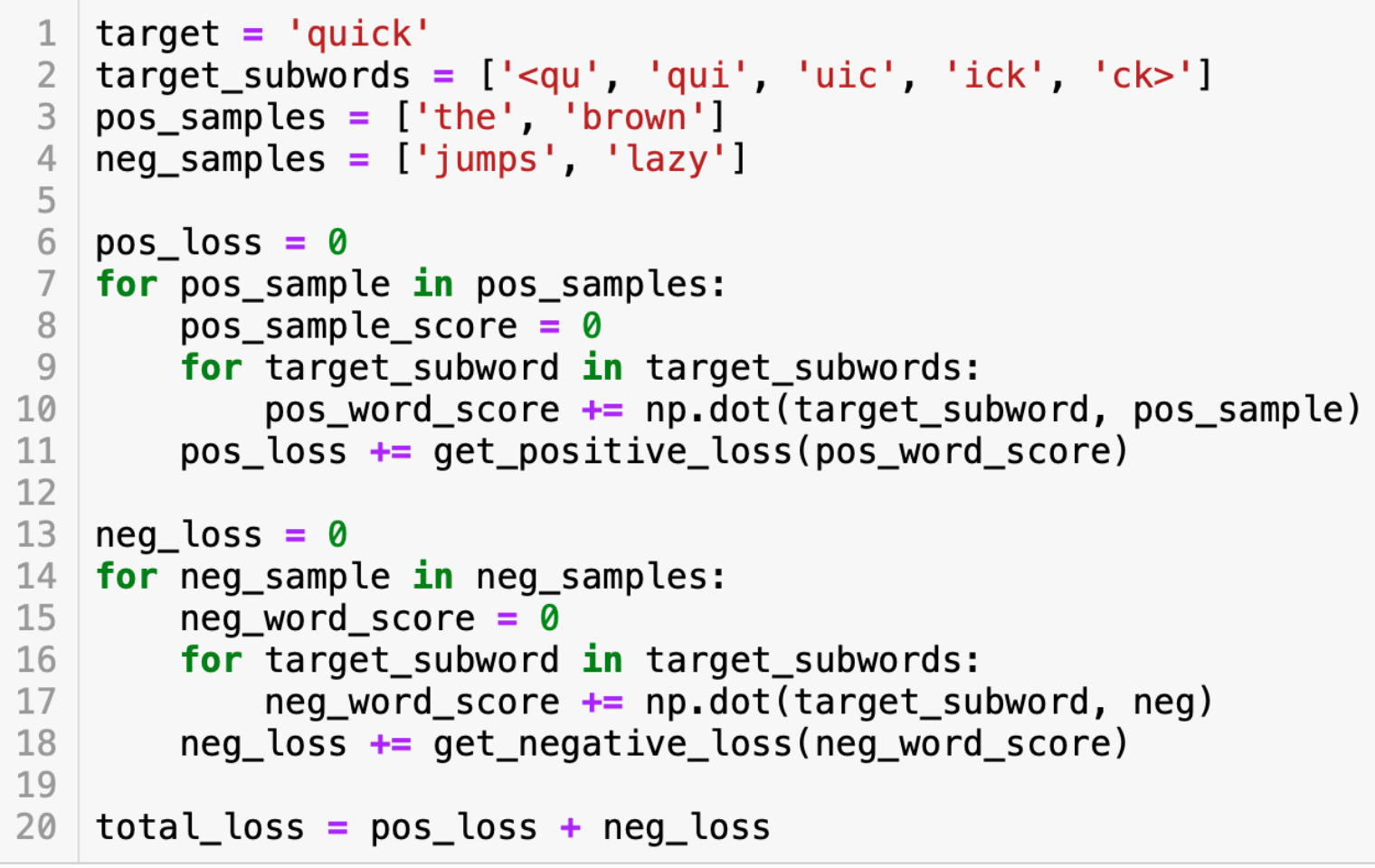
(뒷부분에 neg가 아니라 neg_sample인데 오타가 있습니다.) 참고바랍니다.
마지막으로 평가에 대해서 입니다. 임베딩의 각 버전에 대해, 임베딩만을 기반으로 주어진 account 셋의 topic을 예측하도록 분류기를 훈련합니다. hold out set의 account에 대해 예측 된 주제를 사람이 라벨링 한 topic과 비교하여 임베딩이 topic의 유사성을 얼마나 잘 파악하는지 평가할 수 있습니다.
Fasttext는 Skip Gram 모델을 subword를 활용하자는 간단한 아이디어로 만들어진 모델입니다. 모델에서 활용되는 이런 센스들을 잘 익혀두면 다른 모델에 적용하거나, 다른 논문들을 읽을 때 큰 도움이 될 것 같습니다.
SISG를 활용한 Fasttext에 대해서 알아보자