
AWS_Immersion_DAY, 추천 파이프라인
AWS Immersion Day를 참석했다… 추천 파이프라인 다시 생각해보기
AWS Immersion Day
(AWS 광고아님 주의, 회사 지원 세션)
평화로운 오후를 보내던 어느날 Analytics for E-Commerce Immersion Day 행사 안내 메일이 왔습니다. 분석 시스템에 대해 AWS에 문의한 적이 있었는데, 관련된 웨비나 행사 메일을 척척 보내주시니 아주 감사했습니다. 더군다나 Kinesis나 Kafka에 관심이 있었던지라 학습을 어떻게 해볼까 고민했었는데, 이런 행사가 잡히니 고민이 해결될 수 있겠다는 기대감이 있었습니다.

행사는 다음과 같이 진행된다고 했습니다. 저는 다 필요없고 Hands On Lab이 아주 기대가 되었습니다.
행사의 시작!
15일 13시 부터 시작이 되었습니다. 물론 점심시간을 최대로 활용하는 바람에 늦어버려서 여유롭게 커피한잔과 함께 13시 20분에 접속을 했습니다. AWS의 분석 파트에 있는 제품들을 소개시켜 주셨는데 흥미로운 내용이었지만 제품의 소개같아서 13시부터 16시까지 진행했던 내용을 요약해서 작성을 할 것 입니다. 오늘의 주제는 Hands On Lab이고 이 실습을 하면서 얻은 교훈(?)을 정리할 것이거든요.
AWS Analytics
데이터 분석에 대한 전반적인 내용이 주로 이뤘습니다. 데이터 분석의 목적에 대해서 간략하게 설명해주시면서, 분석을 통해 의사결정을 도와주거나, 어떤 서비스로 이루어져야 한다는 내용이었습니다. 그 중에 눈에 들어왔던 것은 데이터 분석의 속도에 대한 것과 추천 시스템이었습니다. 데이터 분석이 빠르게 이루어질 수록 그 가치가 커진다는 것인데, 이는 회사생활을 하면서 어느정도 느끼고 있던 부분이었습니다.
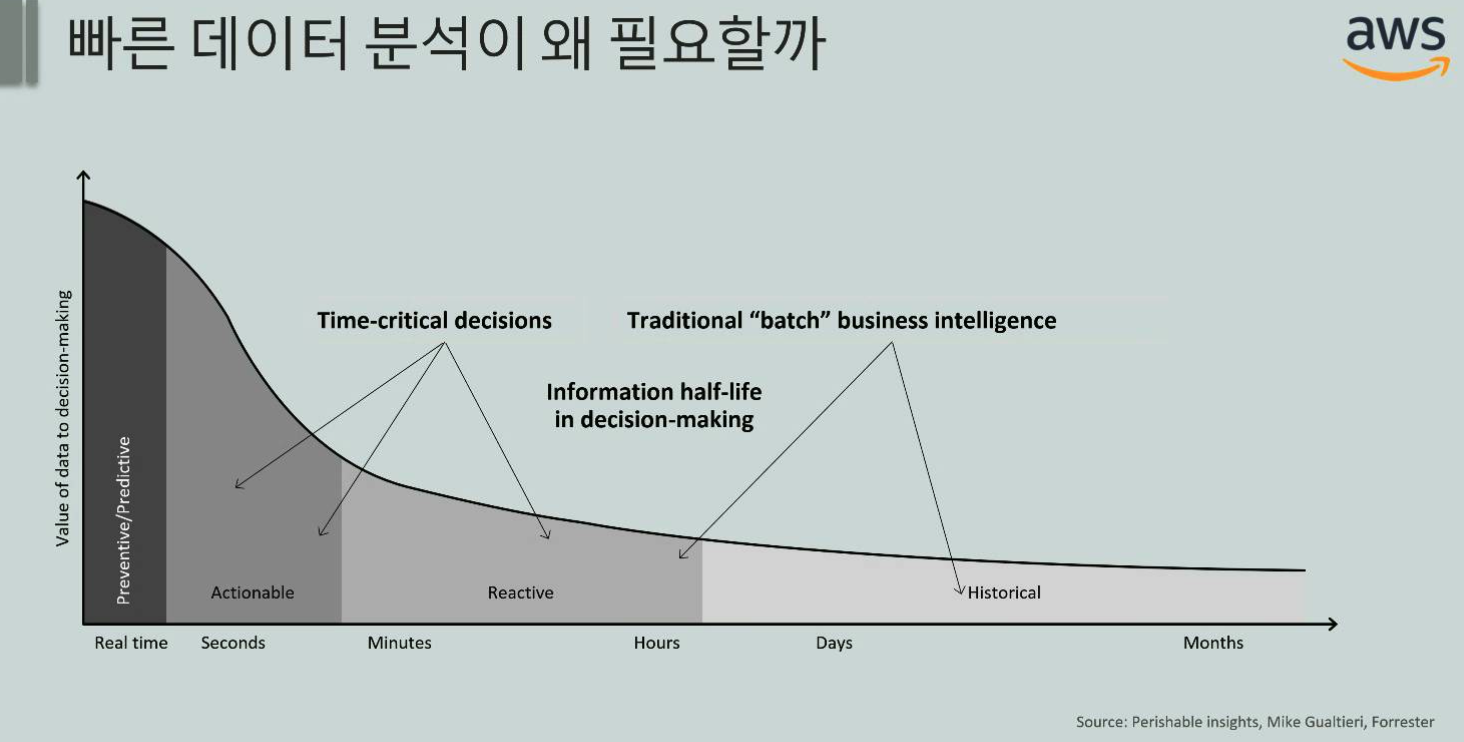
빠른 데이터 분석을 위해서는 당연하게도 파이프라인이 잘 구축되어 있어야 하겠습니다. 내용이 이어지면서 Kinesis제품을 소개해주셨습니다. Kinesis는 세 종류의 제품이 있는데 Kinesis Data Firehose, Kinesis Data Streams, Kinesis Data Analytics 입니다. Firehose는 데이터를 DW나 S3등의 데이터 스토어로 쉽게 넣을 수 있는 시스템이고, Streams는 실시간 데이터 스트리밍 서비스로 이를 통해 이상탐지에 적용하거나 실시간 대시보드로 활용할 수 있습니다. 마지막으로 Data Analytics는 말 그대로 스트리밍 데이터를 변환 및 분석해주는 시스템입니다.
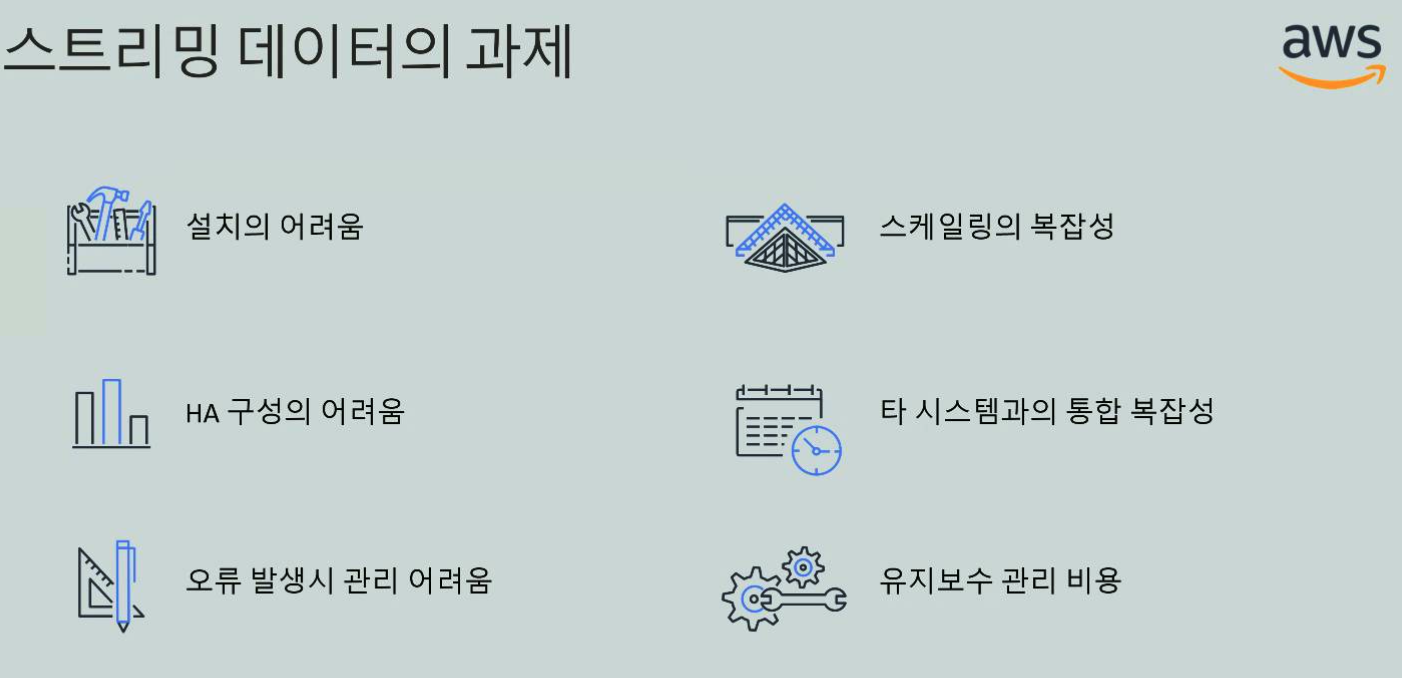
이커머스 영역에서는 속도가 매우 중요하기 때문에 스트리밍 데이터가 필수적이라고 할 수 있습니다. 하지만 스트리밍 데이터 처리를 위한 시스템 구축은 생각보다 힘이 많이 듭니다. 그래서 이 세션에서는 극복해야할 과제로 설명해주셨습니다. Kafka를 예로 들어 설명을 많이 해주셨는데, Kafka는 쉽다고는 하지만 설치가 어렵고 유지보수도 어렵고 신경쓸게 참 많습니다. 그래서! 이 포인트에서 Kinesis를 적극 권장하고 있었습니다. 사용하면 물론 좋겠지만 Kinesis는 비싼 편이라 고려를 좀 해봐야겠습니다.
Hands On Lab
드디어 기다렸던 Hands On Lab시간입니다. 아까 말씀드렸다시피, 데이터 분석을 이용해서 어떤 서비스로 이루어질수 있고 그 중 대표적인 것은 추천시스템입니다. 핸즈온 시간에는 Analytics에서 설명한 제품들을 갖고 추천시스템 파이프라인을 구성하고 캠페인까지 만들어 보는 시간을 가졌습니다.
가상 시나리오를 주고 실습하는 부분이 아주 맘에 쏙 들었습니다.
여러분들은 반려동물 용품을 판매하는 가상의 E-commerce 회사인 ‘몽스토어’ 회사를 운영하고 있습니다. 지금까지 비즈니스는 꾸준히 성장해왔지만 반년전부터 매출이 크게 성장하지 못하고 멈춰 있는 상태입니다. 이에 따라 데이터 분석에 대한 니즈가 발생하였으며, 데이터 분석을 통해 개인별 추천서비스를 도입하여 매출의 성장을 도모할 때라는 결론에 이르렀습니다.
투잡 뛰는 느낌이랄까? 아주 설레는 마음으로 실습을 진행했습니다.
실습내용의 전체 아키텍쳐는 다음과 같습니다.
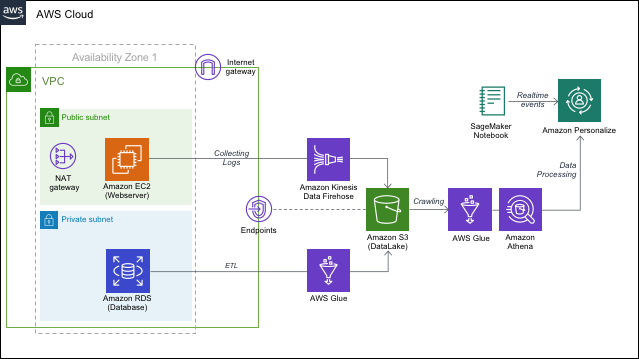
AWS 시스템 내에서 AWS 제품을 갖고 AWS를 이용한 추천 제품인 AWS Personalize를 사용해서, 추천 캠페인을 진행해보자는 것입니다. 주제가 뭐라구요? AWS냐구요? 맞긴한데 거기에 ‘추천 파이프라인을 만들어봅시다!’ 까지가 주제입니다.
본격 실습
실습 내용은 최대한 간결하게 요약해서 정리할 것입니다. 이걸 일일이 쓰는 것보다 들어가서 확인하면 되거든요. 워크샵 링크
정말 궁금하신 분들은 링크로 들어가서 쭉 따라가보시면 됩니다. 물론 실습 엔진은 제공되지 않고 Cloud Formation도 제공되지 않습니다.
실습 순서는 다음과 같았습니다.
- Cloud Formation으로 환경(스택) 구성하기
- S3 생성하기
- Glue를 이용한 RDS DataBase 크롤링
- 크롤링한 데이터 S3로 ETL 전송하기
- Web 로그 데이터 Kinesis Firehose활용하여 수집
- 수집 데이터 S3로 ETL
- S3 데이터 Glue활용하여 ETL
- Athena를 사용해서 데이터 살펴보기
- Personalize를 사용해 추천 데이터 생성하기
Cloud Formation을 활용해서 위 그림과 같은 환경을 만들어 주게 됩니다. 일일이 세팅해서 환경 구성을 하려면 시간이 너무 들게 되니까 빠르게 환경을 구축해줍니다.
Cloud Formation을 활용해 구성한 항목은 위 그림에서 S3기준 왼쪽 부분이라고 할 수 있겠습니다. 망 설정과 webserver, 그리고 RDS입니다.
S3를 만들어 줄 것인데 S3는 여기서 Data Lake로 활용됩니다. Data Lake는 대규모 데이터를 기본 형식으로 저장하고 있는 Storage로 그럴싸해보이지만 제가 보기에는 데이터를 다 때려넣는 곳이라는 생각이 듭니다. 다른 의견이 있으신 분은 댓글 남겨주세요. 아무튼 S3를 만들어 주고 Glue를 사용해보겠습니다.
Glue
Glue는 데이터 처리에 사용됩니다. 데이터는 여기서 두 종류로 나뉘는데, RDS에 갖고 있는 구매이력 데이터와, 수집되고 있는 행동 데이터, 즉, 로그데이터 입니다.
구매이력 데이터 처리
- Glue
- RDS에서 크롤링, 데이터 베이스의 데이터 구조, 스키마를 바로 알 수 없음
- 스키마, 파티션 구조 추론 뒤 데이터 카탈로그 생성
- 크롤링 → RDS에 있는 데이터 테이블 확인 가능
- 2차 크롤링
- 데이터 카탈로그를 생성한 뒤 데이터를 S3로 보내기(ETL)
- Transform할때는 스크립트를 입력, pyspark 코드를 활용함
- Transform한 뒤 S3에 적재[Load]
- RDS에서 크롤링, 데이터 베이스의 데이터 구조, 스키마를 바로 알 수 없음
행동 데이터, 로그 데이터 처리
- Webserver에서 생성되는 데이터를 Kinesis Data Firehose를 사용해 수집
- 수집한 데이터는 S3에 적재
자 이제 Glue를 통해서 S3에 사용할 데이터를 모두 적재해 놓았습니다. 이제 추천데이터를 생성해보겠습니다. AWS Personalize를 사용해 볼 것인데, Personalize는 사용할 데이터 형식이 따로 존재합니다. 그렇기 때문에 원하는 형식에 맞게 전처리를 해주어야 합니다. 또 다시 Glue를 사용해서 전처리하고 Personalize에 전달해보도록 하겠습니다.
추천 데이터 생성
전처리, Glue
Glue를 통해 ETL처리를 해줌, 과정은 위와 유사함 [구매이력]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
##create dynamic frame
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='product').toDF()
digital_df.createGlobalTempView("productview")
##sql query
client_df = spark.sql("SELECT productcode as ITEM_ID, productname as PRODUCTNAME, category1||'|'||category2||'|'||category3 as CATEGORY FROM global_temp.productview")
##write output to S3
client_df.repartition(1).write.format('csv').option('header', 'true').save('s3://demogo-mongstore-[사용자이름]/personalize-items')
job.commit()spark sql을 사용해서 Transformation 뒤 S3에 적재하는 구조
AS-IS, 이 데이터를

TO-BE, 이렇게 바꿀 것

로그데이터 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import datetime
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
##create dynamic frame
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='purchase').toDF()
digital_df.createGlobalTempView("purchaseview")
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='accesslog2021').toDF()
digital_df.createGlobalTempView("accesslog2021view")
##sql query
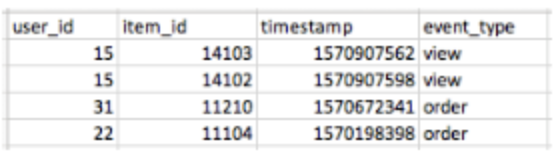
client_df = spark.sql("SELECT userid as USER_ID, REGEXP_REPLACE(pageurl, '[^0-9]+','') as ITEM_ID, to_unix_timestamp(CAST(time AS timestamp)) as TIMESTAMP, 'view' as EVENT_TYPE FROM global_temp.accesslog2021view UNION ALL SELECT userid as USER_ID, productcode as ITEM_ID, to_unix_timestamp(ordertime) as TIMESTAMP, 'order' as EVENT_TYPE FROM global_temp.purchaseview")
##write output to S3
client_df.repartition(1).write.format('csv').option('header', 'true').option('header', 'true').save('s3://demogo-mongstore-[사용자이름]/personalize-interactions')
job.commit()AS-IS, 이 데이터를
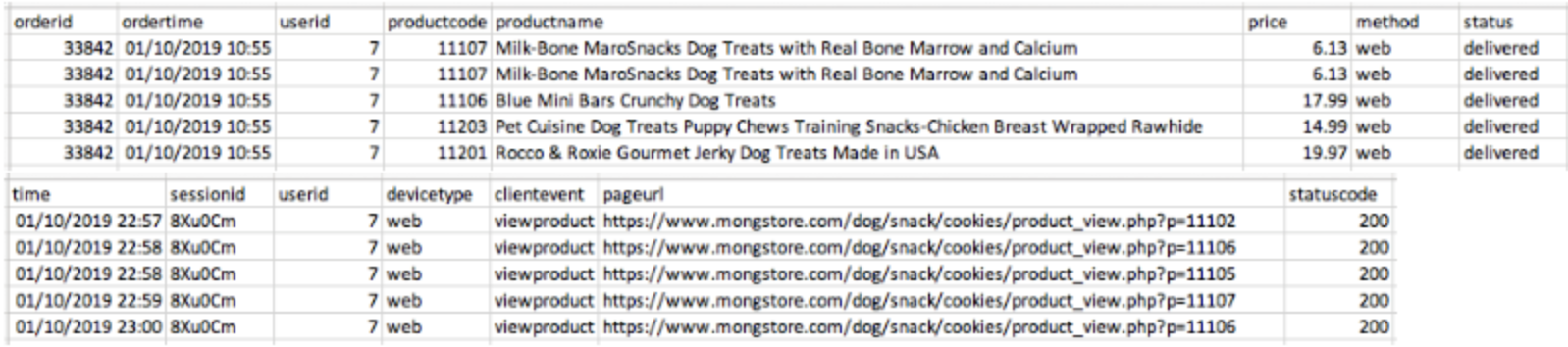
TO-BE, 이렇게 처리
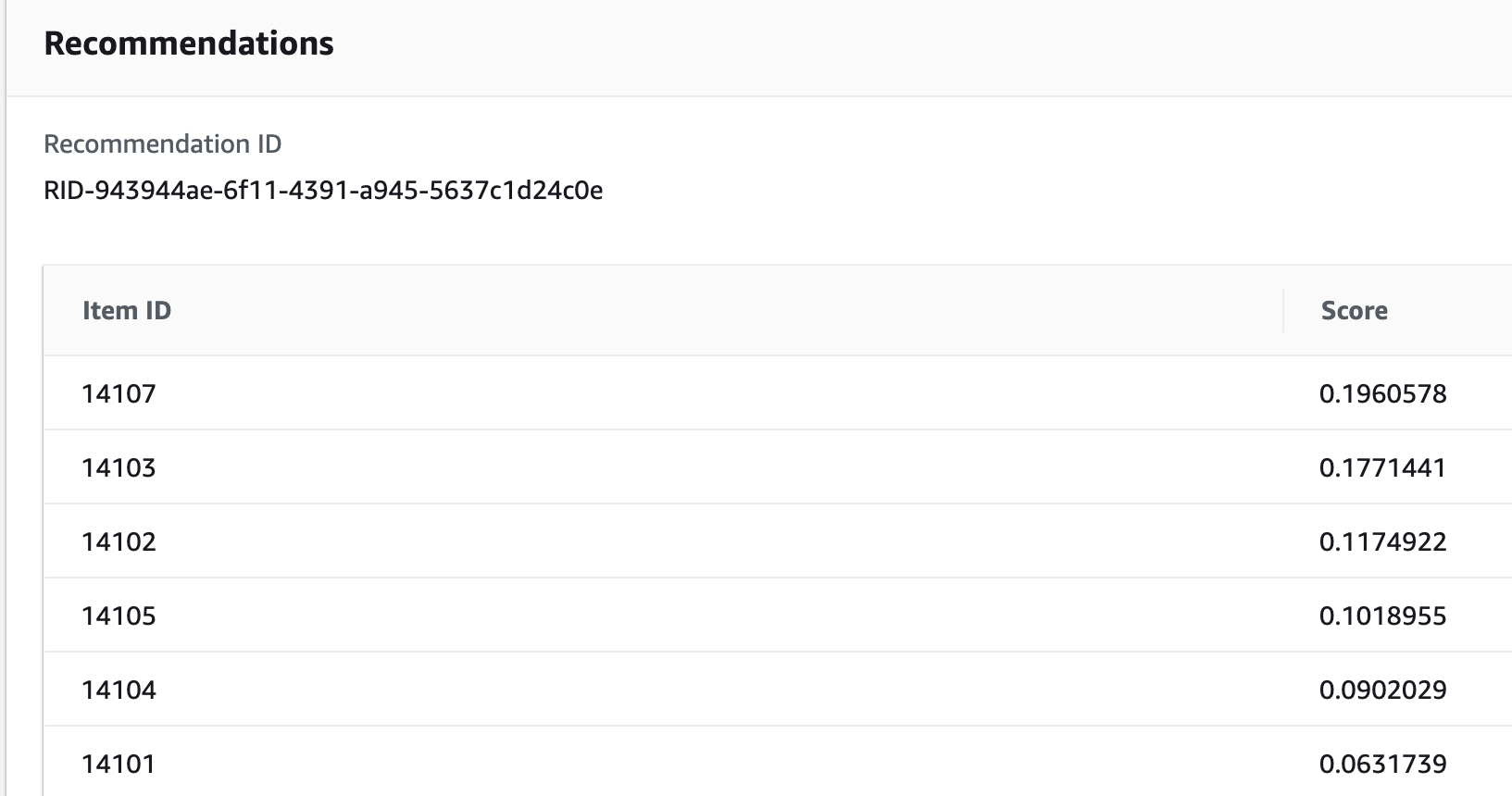
추천 데이터 생성은 데이터 스키마 매핑 후 데이터 임포트를 해주면 됩니다. 이제 솔루션 생성을 해주면 되는데 여기에는 1시간 이상이 소요되네요. 캠페인을 생성해서 데이터를 보면. 유사도 별 랭킹이 매겨진 추천 데이터를 확인할 수 있습니다.
실습 종료, 무엇을 얻었나
이 실습을 통해 현재 서비스하고 있는 추천 시스템의 구조에 대해서 다시 생각해보게 되었습니다. 현재 서비스하고 있는 추천 시스템은 자세하게 밝히지는 못하지만, 간략하게 구조를 말씀드리면, 로그 데이터를 NoSQL DB로 받아 넣고 이것을 추천용 DB에 일부 전처리 하여 넣어주는 형태입니다. 이 추천용 DB에 데이터를 끌어와서 한 고객사의 추천 데이터를 AWS EMR을 이용해서 배치 스케쥴마다 생성하고 EMR을 종료하고 있습니다. 실습에서 제시된 구조와는 많은 차이가 존재합니다. 물론 실습은 B2C 서비스로 제시되었고 현재 회사는 B2B 서비스기 때문에 차이는 있습니다만, 차이점을 정리하자면 다음과 같습니다.
- Data Lake
- ETL 파이프라인의 부재
- Transform한 데이터의 적재
먼저 Data Lake가 없습니다.
Data Lake가 꼭 필요하다고는 할 수 없고, 목적에 따라 구성항목에 넣기도 합니다. 물론 회사에서도 전체 데이터가 다 들어있는 DB는 있습니다만, S3제품만큼 고가용성이 보장된다고는 할 수 없을 것 같습니다. S3에도 connection pool size가 있습니다, 그렇지만 현재 사용하고 있는 DB보다야 훨씬 size가 크고 관리하기도 편하다고 생각합니다. 그리고 이렇게 고가용성이 보장되는 Data Lake가 있으면 새로운 서비스를 구상하더라도 connection pool이나 메모리 때문에 장애나는 상황이 거의 없기 때문에 안정적으로 새 서비스를 생각해보고 토이 프로젝트를 해볼 수 있습니다. 현재 운영과 개발DB가 있긴 하지만 개발DB에 문제가 좀…
ETL 파이프라인이 제대로 구성되지 않은 것 같습니다.
이 실습에서는 E, T, L이 명확하게 나뉘어져 있다는 것이 느껴지는데, 이 실습을 하고 회사 서비스를 돌아보니 어디부터 어디까지가 ETL인지 구분이 잘 되지 않았습니다. Transform을 하긴 하는데 Load를 안하는 것 같고… Transform이 제대로 되고 있는 건지… 뭐 이런 생각을 하게 되었습니다. 하지만 Glue를 사용한다고 생각하고 구성을 생각해봤을 때, 크게 어려울 것 같지 않았습니다. Glue를 간단히 살펴보긴 했지만, ETL프로세스이고 Transform은 거의 Pyspark로 돌아가고 있었습니다. Pyspark로 이미 추천 데이터를 생성하고 있기에 파이프라인을 정리해주면 금방 적용할 수 있지 않을까 생각해봤습니다. 어디서 끌어오고, 적재할지를 잘 정하는 게 중요할 것입니다. 그렇다면 DB를 잘 알아야 하는데, 이렇게 공부 포인트가 늘어났습니다! 하하
Transform한 데이터는 어디?
큰 문제점 중에 하나라고 생각하는데, 현재 비용 효율적인 아키텍쳐를 지향하고 있기 때문에 EMR을 상시 구동하고 있지 않습니다. 생성한 추천 데이터는 DB에 넣고 있지만, 전처리한 데이터는 여지없이 삭제되고 맙니다. 실습을 진행하고 생각해보니 이 데이터가 너무 아깝다는 생각을 하게 되었습니다. 만약 전처리한 데이터가 남아있다면 다른 서비스에 적용을 해볼 수 있지 않을까 생각이 들었습니다. 추천에 사용되는 데이터가 어떻게 보면 구매나, 클릭, View에 대한 패턴 분석된 데이터인데, 이것을 고객사 레포팅이나 기타 분석 시스템에 활용할 여지가 많을 것 같았습니다.
Kaizen!
그러면 어떻게 개선할 수 있을까요? TA님이나 팀장님과 의논을 같이 하면서 구체화해야겠지만 우선 생각나는 개선점은 다음과 같습니다.
- Extract하는 데이터 포인트를 변경
- Data Warehouse
- 상시 구동 EMR서버 구성
이게 명확한 답이 될지 모르겠습니다. 하지만 우선 이렇게 글로 만들어놓고 다른 사람들의 의견을 받아서 두들겨 맞으며 고쳐나가는 게 맞다고 생각합니다. 일단 저질러야 변화가 생기니까요.
데이터 포인트를 변경한다는 것은 Extract하는 데이터 베이스가 혹사당하고 있기 때문입니다. 너무 자주 데이터를 끌어오고 나가고 있는 상황이기 때문에, 사용하는 데이터를 따로 저장하는 DB를 만들면 어떨까 생각합니다. 그리고 이는 2번과 이어지는데, 이것을 Data Warehouse로 사용하는 것입니다. 이 DW는 Big Query를 검토하고 있습니다. Big Query에 일단 적재를 하고 전처리 스케쥴을 걸어서 추천에 사용할 데이터를 아주 예쁘게 구성해 놓을 예정입니다. 마치 Personalize에 Glue를 사용해서 데이터를 전처리하고 넣는 것 처럼요. 동시에 EMR 서버를 상시 구성해놔서 추천 생성할 때 발생하는 일부 데이터를 DW에 저장해놓으려고 합니다. 물론 중간에 데이터를 확인해보고 이게 사용할만한 가치가 있을지 분석가분들과 고민해봐야겠지만, 구상은 이렇게 해놓고 있습니다. 어떻게 보면 DW에 스케쥴을 걸어서 작업을 돌려놓으면 중간에 EMR로 작업하면서 나오는 데이터는 굳이 필요가 없을 수도 있겠습니다.
헛된 구상일 수 있겠지만, 발전할 수 있는 포인트를 어느정도 찾은 것 같아서 얻은게 있는 세션이었다고 생각합니다. 이제 해야할 것은 TA님과 팀장님과의 미팅, 그리고 부족한 부분을 채워넣는 학습 시간이겠습니다.
AWS_Immersion_DAY, 추천 파이프라인