
분산시스템의 문제점, zookeeper & etcd
코디네이션 시스템, 왜 이런 도구들을 사용해야 하는 걸일까요?
분산시스템의 문제점, zookeeper & etcd
데이터 엔지니어링 관련 애플리케이션을 다루다보면 심심치 않게 등장하는 것이 Zookeper입니다. Kafka를 다룰때도 등장하고, 하둡-스파크를 다룰 때도 역시 등장합니다. 쿠버네티스를 다룰때도 비슷하게 등장하는 것이 etcd입니다. 가끔 개발 세션을 볼 때나 블로그 글을 살펴볼때에도 etcd가 나오는데 정확히 어떤 역할을 하는지 이해가 가지 않았습니다. 둘의 공통점이라고 하면 분산 환경에서 사용되는 코디네이션 시스템인데, 왜 이런 도구들을 사용해야 하는 걸일까요?
분산 시스템에서 코디네이션의 필요성
요즘의 대부분의 데이터 엔지니어링 시스템은 분산 시스템을 사용하고 있습니다. 아파치 카프카, 하둡, 스파크 등등 많은 애플리케이션들이 고가용성과 내결함성, 짧은 지연 등의 이유로 이를 활용하고 있습니다. 하지만 이러한 분산 시스템을 잘 유지하기 위해서는 몇가지 조건들이 필요합니다. 분산 시스템이 가진 문제점들이 있기 때문입니다. 여러 노드들로 나누어진 스토리지가 있다고 해봅시다. 이 노드들이 데이터를 write하고 클라이언트는 이 데이터를 읽을 것입니다. 노드들 중 한 대가 리더 노드로 write를 담당할 것이고 이 노드를 통해 모든 클라이언트의 write명령을 받을 것입니다. 명령은 리더가 아닌 다른 팔로워 노드들이 차차 처리하겠죠. 시스템이 완벽해 보이나요? 리더 노드가 죽으면 어떻게 될까요? 데이터를 한 노드에 write하는 동안 클라이언트가 다른 노드에서 데이터를 읽으려고 하면 어떻게 될까요?
분산시스템은 멀리서 보면 안정적이고 성능도 굉장히 뛰어나보이지만, 가까이에서 보면 처리해야될 문제들이 이처럼 상당합니다. 이러한 문제들을 잘 다루기 위해 사용하는 것이 코디네이션 시스템이고 대표적인 것이 바로 zookeeper와 etcd인 것입니다.
분산 시스템의 대표적인 문제 몇 가지를 살펴보고 Zookeeper와 etcd가 왜 필요한지, 어떻게 이런 문제들을 관리하는지 살펴보겠습니다.

분산 시스템의 문제점
우리가 잘 사용하고 있는 분산시스템은 사실 고장날 것을 가정하고 설계하고 있습니다. 여러 노드를 통해 시스템을 구축하고 있기 때문에, 고장날 가능성이 단일 노드보다 훨씬 큰 것이죠. 그래서 장애가 났을 때는 잘못된 결과를 반환하는 것보다 아예 동작하지 않기를 바랍니다. 장애에는 여러 종류가 있는데 부분 장애는 시스템의 어떤 부분은 잘 동작하지만 다른 부분은 예측할 수 없는 방식으로 실패 하는 것을 말합니다. 이러한 비결정성과 부분 장애 가능성이 분산 시스템을 어렵게 만드는 것입니다.
1. 신뢰성 없는 네트워크
분산 시스템은 어떻게 연결되어있을까요? 분산 시스템은 비공유 시스템, 네트워크로 다수의 장비를 연결합니다. 네트워크는 장비들이 통신하는 유일한 수단이기에 굉장히 주의깊게 봐야합니다. 장비들간의 네트워크는 비동기 패킷 네트워크를 주로 사용합니다. 왜냐면 순간 몰리는 데이터 전송에 특화되어야 하기 때문입니다. 패킷 전송 지연시간 최대치가 고정되어 있고 유실되는 데이터가 없는 극단적인 신뢰성을 지닌 네트워크를 구성하면 안될까요? 이렇게 하기 위해서는 고정된 대역폭을 설정해야 합니다. 이렇게 되면 정확히 몇 초에 얼마의 데이터를 보낼 수 있는 것이 보장됩니다. 이런 방식을 회선 이라고 합니다. 회선은 데이터 전송량이 예상 가능한 경우에 적절하겠습니다. 우리가 사용하는 일반적인 상황에서는 데이터 전송량이 예상이 가능할까요? 아마 불가능할 것입니다. 또한 우리가 원하는 시스템의 목적은 가능한 빨리 완료되는 것입니다. 그러니까 순간적으로 몰리는 트래픽에 최적화된 방식이 필요한 것입니다. 그래서 데이터센터 네트워크와 인터넷은 패킷 교환 방식을 사용하는 것입니다. 결국 이 방식을 사용하다보니 어쩔 수 없이 네트워크에 신뢰성이 떨어질 수 밖에 없습니다. 타임아웃등의 방식을 사용할 수 있지만, 완벽하지는 않습니다.
2. 신뢰성 없는 시계
분산 시스템에서는 통신이 즉각적이지 않아, 시간은 다루기 까다로운 개념 중 하나입니다. 시간은 절대적인 것이라고 생각할 수 있지만, 유감스럽게도 시계가 정확한 시간을 알려주게 하는 방법은 기대만큼 신뢰성이 있거나 정확하지 않습니다. 각 장비는 사실 자신만의 시계를 갖고 있지만 완벽하게 정확하지 않습니다. 이를 위한 동기화 매커니즘 중 하나는 서버 그룹에서 보고한 시간에 따라 컴퓨터 시계를 조정할 수 있게 합니다.
이렇게 동기화된 시계에 의종할 수 있습니다. 보통 대부분의 시간에 잘 동작하지만, 견고하게 소프트웨어를 설계하고자 한다면, 잘못된 시계에 대비할 필요가 있습니다. 하루는 정확히 86,400초가 아닐 수도 있고, 일 기준 시계가 시간이 거꾸로 갈 수도 있으며, 노드의 시간이 다른 노드의 시간과 차이가 많이 날 수도 있습니다. 문제는 시계가 잘못된다는 것을 눈치채기 쉽지 않다는 것입니다. 천천히 조금씩 실제 시간으로부터 차이가 나기 시작하지만, 대부분 잘 동작하는 것처럼 보입니다. 이렇게 되면 극적인 고장보다는 조용하고 미묘한 데이터 손실이 발생할 가능성이 높을 것입니다.
그 외
이외에도 네트워크에 비대칭적인 결함이 있어 노드가 메세지는 받지만 밖으로 보내지 못한다면, 노드에 타임아웃을 통해 죽었다고 잘못 선언해버리는 일이 발생할 수도 있고, 죽은 상태인 줄 알았던 노드가 갑자기 되돌아와서 리더처럼 역할을 수행하기도 합니다.
결국 위와 같은 문제들로 인해서 분산시스템의 균형이 무너져버립니다. 리더와 팔로워의 구조를 통해서 명령을 리더로 부터 내려받고 실행된 내용을 리더에게 보고해서 완료처리를 해야하지만, 갑자기 리더가 사라진다던가 리더가 둘 이상이 되어 버린다던가, 결국 쓰기가 충돌되고 파일이 오염되기 시작합니다. 더 자세하게는 리더와 락의 문제를 더 설명해야하지만, 너무 길어질 것 같아서 생략하겠습니다. 결론은 네트워크나 시계등의 문제로 신뢰성이 깨지면서 분산시스템이 제대로 동작하지 않는다는 것입니다.
하지만 엔지니어로서의 우리의 임무는 모든 게 잘못되더라도 제 역할을 해내도록 만드는 것입니다. 그래서 부분 장애 가능성을 받아들이고 소프트웨어에 내결함성 메커니즘을 넣어서 신뢰성 있는 시스템을 만들려고 하고 있습니다. 이런 상황에서 모든 노드가 어떤 것에 동의하도록 만드는 것이 중요한데, 이런 합의 에 신뢰성있게 도달하는 것은 또 다른 까다로운 문제입니다. 다만, Zookeeper라던가 etcd 등의 코디네이션 도구들을 도움을 통해 좀 더 쉽게 합의에 도달할 수 있습니다.
Part1. Zookeeper
Zookeeper는 분산 애플리케이션을 위한 코디네이션 시스템입니다. 분산 애플리케이션이 안정적인 서비스를 할 수 있도록 분산되어 있는 각 애플리케이션의 정보를 중앙에 집중하고 구성 관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공합니다.
분산시스템에 여러 문제들이 있기 때문에, 시스템에서 정보를 어떻게 공유할 것이고 상태를 어떻게 체크할 것이며, 분산 서버들간의 잠금을 처리하는 방법에 대한 해결방법이 필요해졌고 여기서 주키퍼는 해결책을 일부 제시해주고 있습니다.
분산 시스템의 코디네이션에서도 마찬가지로, 코디네이션 시스템에 장애가 발생하면 전체 시스템에 장애가 발생해 버리게 됩니다. 따라서 코디네이션 시스템 역시 이중화 등 고가용성을 위한 시스템을 갖고 있습니다.
엄청나게 대단한 일을 하는 것처럼 보이긴 하는데, 기능은 단순한 편입니다. Znode 라는 Key-value로 이루어진 데이터 저장 객체를 제공하고, 여기에 데이터를 넣고 빼는 기능만을 제공하는 것입니다. 아키텍쳐를 살펴보면서 Znode까지 살펴보겠습니다.
Zookeeper 아키텍쳐
고가용성을 위해 zookeeper는 클러스터링화 해서 최대한 정상 동작을 보장하려고 합니다. 이 클러스터를 앙상블이라고 부릅니다. 앙상블로 묶인 서버 중 한대가 쓰기 명령을 담당하는 리더 역할을 맡고, 나머지는 팔로어가 되는 구조입니다. 클라이언트가 쓰기 명령을 내리면 앙상블 중 리더 역할을 맡는 zookeeper서버로 바로 전달되고, 리더는 팔로어들에게 쓰기를 수행할 수 있는지 확인합니다. 만약 팔로어 중 과반 수의 팔로우로부터 쓸 수 있다는 응답이 오면 리더는 팔로어에게 Write하도록 지시합니다.
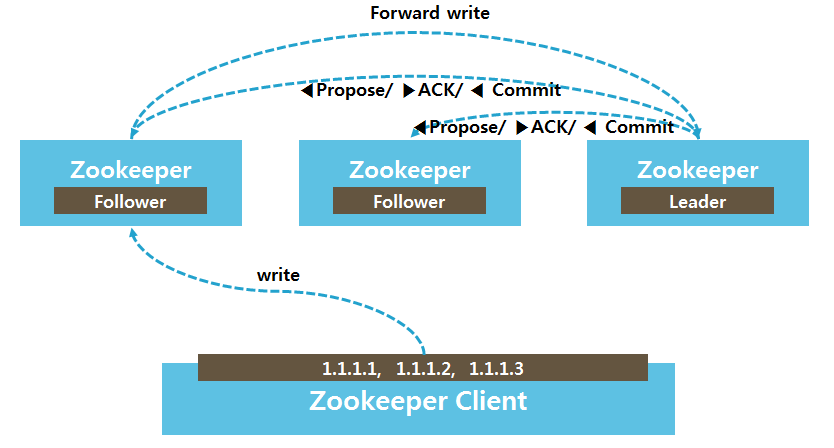
이런 이유로 앙상블을 이루기 위해서는 최소 3대의 서버가 필요합니다. 만약 5대의 서버가 있다면 3대의 서버가 살아있어야겠습니다.
리더는 업데이트 명령을 받으면 트랜잭션의 순서를 반영하는 번호로 업데이트를 스탬프 처리합니다(번호 붙이기). 그리고 리더는 이 번호와 함께 업데이트 요청을 브로드캐스트하고 다음서버의 다수가 메세지에 응답할 때까지 기다립니다. 다음 서버는 업데이트 요청을 받으면 스탬핑된 번호를 확인하고 이 숫자가 자신의 로그에 기록된 트랜잭션보다 크면 리더에게 동의한다고 응답합니다. 리더는 앙상블의 서버로부터 응답을 받고 앙상블에 있는 팔로워들이 승인을 한 경우에만 리더는 요청된 트랜잭션을 자체 로그에 입력하고 앙상블을 통해 복제합니다. 이제 쿼리의 업데이트 실행이 발생하고 응답이 클라이언트 쪽으로 다시 전송됩니다. 이를 통해 합의가 유지되는 것입니다.
Zookeeper의 데이터 모델
Zookeeper는 Znode라는 노드의 계층구조를 유지합니다. 네임스페이스의 각 znode에는 연관된 데이터가 있습니다.
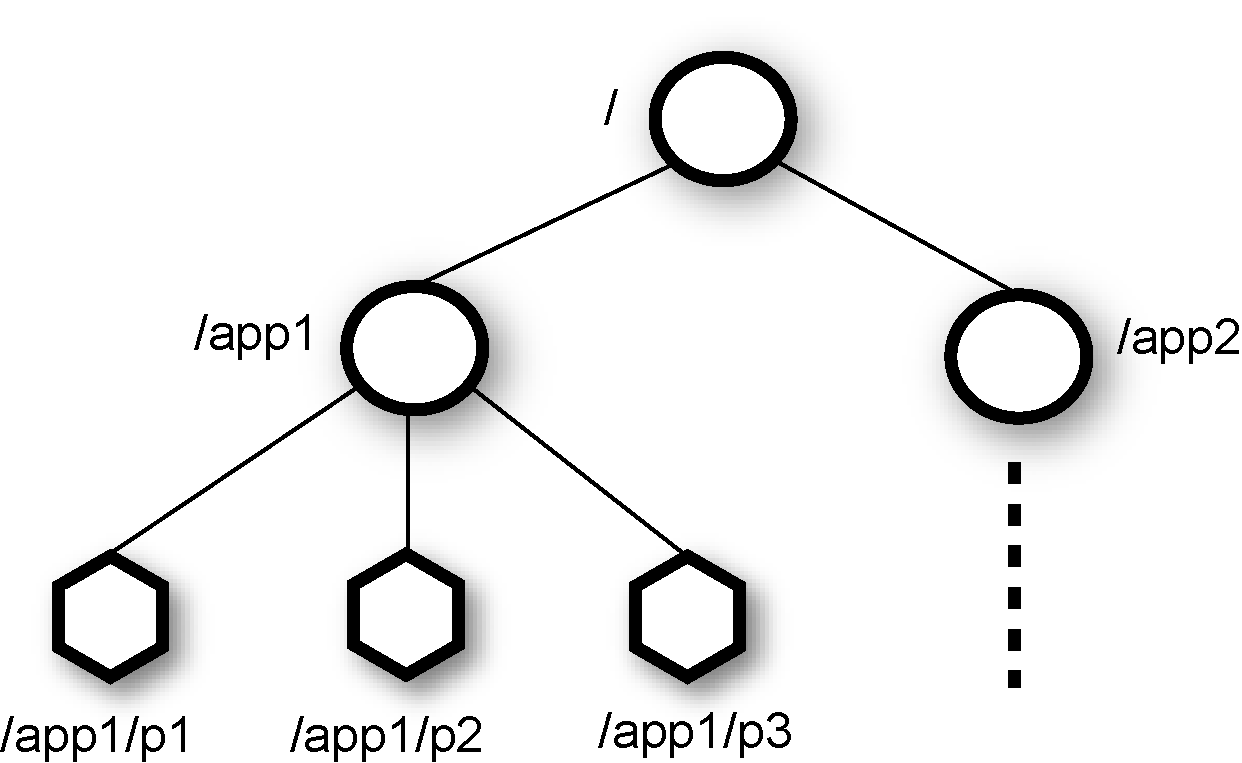
Znode의 이름은 슬래시로 구분되어있는 경로의 집합이고, 모든 znode는 경로로 식별됩니다. znode에는 두 유형이 있습니다.
- Persistent znode: 이 znode는 znode를 생성한 세션이 살아있지 않는 경우에도 디스크에 유지됩니다.
- Ephermeral znode: znode를 생성한 세션이 종료될 때 까지 존재합니다. 세션이 끝나면 삭제됩니다.
Quorum(정족수)
리더가 새 트랜잭션을 수행하기 위해서는 자신을 포함해 과반수 이상의 서버의 합의를 얻어야 한다. 과반수의 합의를 위해 필요한 서버들이 바로 Quorum이다. 앙상블을 구성하는 서버 수가 5개라면 quorum은 3개로 구성된다. 앙상블로 구성되어 있는 주키퍼는 과반수 방식에 따라 살아 있는 노드 수가 과반 수 이상 유지되기만 하면 지속적인 서비스가 가능하다.
결론적으로 Zookeeper 서비스는 이런 방식들을 통해 클라이언트의 업데이트가 전송된 순서대로 적용되고 연결된 서버에 관계없이 클라이언트가 동일한 데이터를 읽을 수 있도록 보장합니다.
Part2. etcd
머신의 분산된 시스템 또는 클러스터의 설정 공유, 서비스 검색, 스케쥴러 조정을 위한 오픈소스 분산형 키-값 저장소입니다. 사실상 쿠버네티스의 기본 데이터 저장소로 사용되는데(컨트롤 플레인 컴포넌트로 채택됨), 클라우드 네이티브 애플리케이션은 etcd 사용을 통해 일관성 있는 가동시간을 유지하고 개별 서버에 장애가 발생하더라도 작동 상태를 유지할 수 있게 되었습니다. 애플리케이션은 이 etcd에서 데이터를 읽고 쓸 수 있고, 이를 통해 설정 데이터를 배포해 노드 설정에 대한 이중화 및 복구 능력을 제공할 수 있습니다. 이 etcd는 쿠버네티스에서 마스터노드에 구성되어 있습니다.
만약 etcd에 문제가 발생해 데이터가 유실된다면, 컨테이너 뿐 아니라 클러스터가 사용하는 모든 리소스가 길을 읽게 되어버립니다. 따라서 etcd에는 높은 신뢰성이 꼭 필요합니다.
RSM(Replicated State Machine)
분산 환경에서 서버가 몇 개 죽더라도 잘 동작하는 시스템을 만들 수 있는 방법 중 하나입니다. 똑같은 데이터를 여러서버에 복제하는 것인데, 이 역할을 수행하는 머신을 RSM이라고 부릅니다. 데이터를 여러 서버에 복제하면 모든게 해결될까요? 오히려 이 상황때문에 문제가 발생하기도 합니다. 데이터 복제과정에서는 합의가 꼭 필요한데, 합의란 RSM이 4가지 속성을 만족한다는 의미입니다. etcd는 이 조건을 만족하기 위해 Raft를 사용합니다.
- Safety : 항상 올바른, 의도하는 결과를 리턴해야 합니다.
- Available : 서버가 몇 대 다운되더라도 항상 응답해야 합니다.
- Independent from Timing : 네트워크 지연이 발생해도 로그의 일관성이 깨져서는 안됩니다.
- Reactivity : 모든 서버에 복제되지 않았더라도 조건을 만족하면 빠르게 요청에 응답해야 합니다.
Raft
Raft는 분산 시스템에서 특히 etcd에서 합의를 도출하는 프로토콜입니다. Follower, Candidate, Leader로 State가 나눠져있습니다.
Leader Election
Follower가 리더로부터 정보를 받지 못하고 있으면 후보자가 됩니다. 그러니까 시작상태에도 적용이 됩니다. 이 후보자들은 다른 노드들에 투표를합니다. 그러면 다른 노드들은 투표에 대한 응답을 보내게 되고, 과반수에 따라 한 노드가 리더로 승격됩니다.
Log Replication.
이렇게 리더가 선정되면 시스템의 모든 변화들은 리더에게 전달되고 각 변화는 노드의 로그 항목에 추가됩니다. 하지만 커밋이 되지 않은 상태이기 때문에 노드의 value를 업데이트 하지는 않습니다. 항목을 커밋하기 위해 다른 팔로워 노드에 복제를 합니다. 이제 리더가 다른 과반수의 노드들에 항목이 쓰여질 때까지 기다립니다.
이제 항목이 커밋되었고 리더노드들과 다른 노드들의 상태가 업데이트 되었습니다. 리더는 팔로워들에게 항목이 커밋되었다고 공지하는데, 이 때 클러스터는 합의가 되었다고 말할 수 있습니다.
간단하게는 이렇게 설명할 수 있는데 알고리즘의 자세한 동작을 알아보고 싶다면, 아래 링크 애니메이션을 통해 확인할 수 있습니다. etcd가 이루는 합의에 대해서 제대로 이해할 수 있을 것입니다.
http://thesecretlivesofdata.com/raft/
참고, Consul
서비스 디스커버리 측면에서 Consul도 여기에 낄 수 있습니다. Consul는 서비스 디스커버리(Service discovery)와 설정을 관리하는 툴입니다. Consule는 분산&클라우드 환경에 적응하기 위한 고가용성, 유연한 스케일링, 분산시스템의 특징을 가집니다. 리더 선출을 위해 서버는 역시 Raft 알고리즘을 사용합니다.
Consul의 핵심 기능은 아래와 같습니다.
- 서비스 디스커버리 : DNS 나 HTTP 인터페이스를 통해서 서비스를 찾을 수 있게 합니다. 외부의 SaaS 서비스업체도 등록할 수 있습니다.
- Health Checking : 클러스터의 건강 상태를 모니터링하며 문제가 생길 경우 신속하게 전파합니다. 헬스체크는 서비스 디스커버리와 함께 작동하며, 문제가 생긴 호스트로 서비스 요청이 흐르는 걸 막습니다. 이를 이용해서 서비스레벨에서의 서킷 브레이커(circuit breaker)를 구현 할 수 있습니다.
- KV(Key/Value) 저장소(Store) : Consul은 계층적으로 구성 할 수 있는 KV 저장소를 제공합니다. 애플리케이션은 설정, 플래그, 리더 선출 등 다양한 목적을 위해서 이 저장소를 사용 할 수 있습니다. 이 저장소는 HTTP API를 이용해서 간단하게 사용 할 수 있습니다.
- 멀티 데이터센터 대응 : 데이터센터 규모에서 사용 할 수 있으며, 복잡한 구성없이 여러 리전(region)을 지원 할 수 있습니다.
- Service Segmentation : Consul Connect는 TLS를 이용 서비스와 서비스사이에 안전한 통신이 가능하게 합니다.
Reference
Designing Data-Intensive Applications(데이터 중심 어플리케이션 설계)
https://www.bizety.com/2019/01/17/service-discovery-consul-vs-zookeeper-vs-etcd/
분산시스템의 문제점, zookeeper & etcd