
karpenter에 대한 설명, eks에 적용하기
Kubernetes 노드 관리를 편리하게. Karpenter
(Thumbnail image is generated from Dall-e(https://labs.openai.com/))
Karpenter
🪚 Intro.
AWS에서 만들고 운영중인 프로젝트로 빠르게 버전이 올라가고 있습니다. 글을 작성하는 와중에도 0.14에서 0.15버전이 업데이트 되었습니다.
AWS re:Invent 2021 행사에서 Karpenter v0.5이 드디어 정식으로 오픈되었고 GA(Generally Available)로 릴리스 되었습니다. 정식으로 오픈되었다 보니, 이것을 가져다가 운영환경에서도 사용을 하는 것도 가능합니다.
Karpenter는 간단히 말하면, Kubernetes의 worker node 자동 확장 기능을 담당하는 오픈소스 프로젝트라고 할 수 있는데, 기존의 Node Auto Scaling과 비교해서 어떤 장점이 있는지를 알아보도록 하겠습니다.
Kubernetes의 장점, Node Auto Scaling
먼저 쿠버네티스에 대해서 간략하게 알아보도록 하겠습니다. 쿠버네티스는 컨테이너 관리 플랫폼으로 빠른 배포와 뛰어난 확장성을 가졌습니다. 쿠버네티스를 활용해서 배포 관리를 하면 정말정말 편한 부분이 많지만, 운영 부담은 줄여야 하는게 중요합니다. 리소스가 모자라서 파드가 안 뜬다던가 하면 곤란해지거든요. 그래서 AWS를 사용하는 회사에서는 Managed Kubernetes 서비스인 EKS를 통해서 노드 관리의 부담을 줄이려고 하고 있습니다.
결국 EKS 통해서 Control Plane 운영 부담을 줄여야 하는 게 중요한데, 특히 컨테이너 사용량에 따라 지속적으로 Computing Node를 빠르게 추가하고 줄일 수 있는 Elasticity가 필요하게 됩니다. 이 개념에 딱 맞는게 AWS에 이미 존재하는데 바로 EC2 인스턴스입니다. 추가적인 노드가 필요할 때 Elastic한 성질을 지닌 AWS 컴퓨팅의 기본 단위인 EC2(Amazon Elastic Compute Cloud)를 불러와서 이것을 노드로 붙이는 것입니다. 그리고 여기에 Auto Scaling을 적극적으로 활용하면서 Worker node의 운영 부담을 줄일 수 있게 되는 것입니다.
EKS에서는 Auto Scaling이 있는데 왜 그럼 Karpenter를 굳이 사용하려고 하는 건가요? 이제 그 이유를 차근차근 알아보겠습니다.
Karpenter에 대한 짧막한 소개.
Karpenter는 신규 배포될 pod를 지속적으로 체크하고 Worker Node가 부족하면 자동으로 Worker node를 추가배포하고 확장하는 역할을 담당합니다. 추가적인 노드를 확장하는 것 뿐만 아니라, 불필요한 Worker node도 정리하기도 합니다. 따라서, 노드의 비용 효율화와 운영 부담을 최소화 하기 위한 자동화 도구로 Karpenter를 사용할 수 있게 되는 것입니다. 자세한 설명은 아래에서 계속 하도록 하고 이제 기존의 Auto Scaling 방식은 어떤 것이 있는지, 어떻게 이루어지는 지에 대해서 알아보겠습니다.
기존의 Node Auto Scaling
기존의 노드 오토스케일링 방법은 CA(Cluster Auto Scaler)가 대표적입니다.
CA는 Cloud Provider(AWS, GCP)마다 각자 다른 방법으로 지원합니다. AWS의 경우에는 EC2 Auto Scaling Group을 사용하여 CA를 구현하는데, EKS에서 제공되는 Node Group기능은 다음과 같습니다.
Node Group
- Worker Node를 그룹핑하여 관리하는 기능 제공
- Auto Scaling Group과 Launch Template으로 구현됨
- Launch Template에 어떤 스펙의 Instance, AMI를 사용할 것인지 작성되어 있음.
- Worker Node들은 ASG를 통해 확장하는 구조
- ASG를 Cluster Autoscaler가 컨트롤
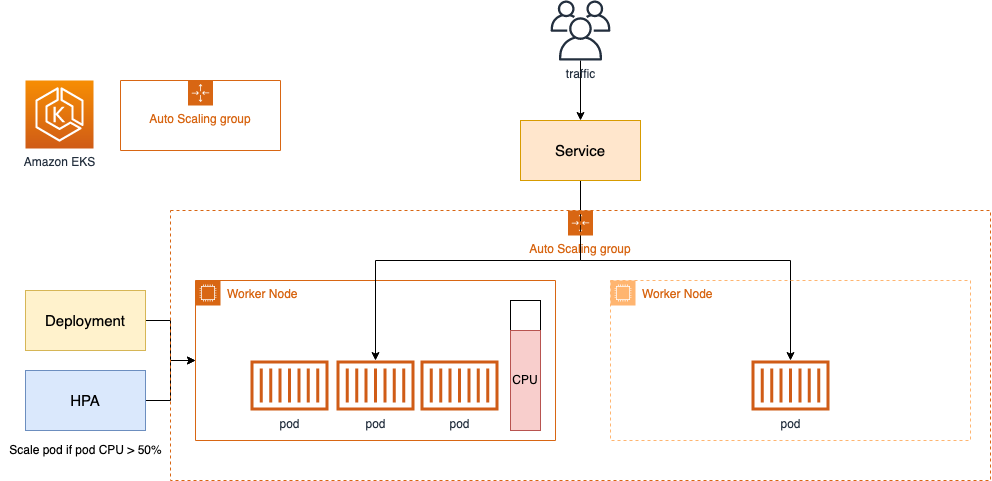
Node Group의 자동 확장 시나리오
그렇다면 이 Node Groupb이 어떻게 Node를 자동으로 확장하는 것인지 알아보겠습니다. 가상의 상황을 가정해보겠습니다. pod가 가득 찼고 더 이상 pod를 배포할 수 없는 상태입니다. 이런 상태에서 신규 pod 생성 요청이 왔습니다. 대략 Airflow에서 KubernetesPodOperator를 통해서 새 파드를 통해 작업을 하려는 것으로 상상해보겠습니다(이 Operator는 Airflow를 통해 작업을 하려고 할때, 작업을 워커에서 수행하지 않고 새 파드를 띄워서 해당 파드에서 작업하도록 합니다). Kube-Scheduler는 신규 Pod를 배치할 적절한 Node를 선정하려고 합니다.
이제 다양한 Label 정보, 가용량 등을 통해서 pod가 배치될 대상 노드를 필터링 하고 최종으로 자리잡을 노드를 선정하려고 합니다. 이 노드 선정 전까지는 pod는 Pending상태로 나오게 됩니다(Unschedulable pod). 이 상태에서 머물다가 적당한 노드가 없다면 pod의 프로비저닝은 실패하게 됩니다. pod의 상태를 확인하고 노드 선정에 실패하게 된다면 Node Group의 ASG값 중 Desired Capacity 값을 수정하면서 워커 노드의 개수를 증가시도록 설정합니다.
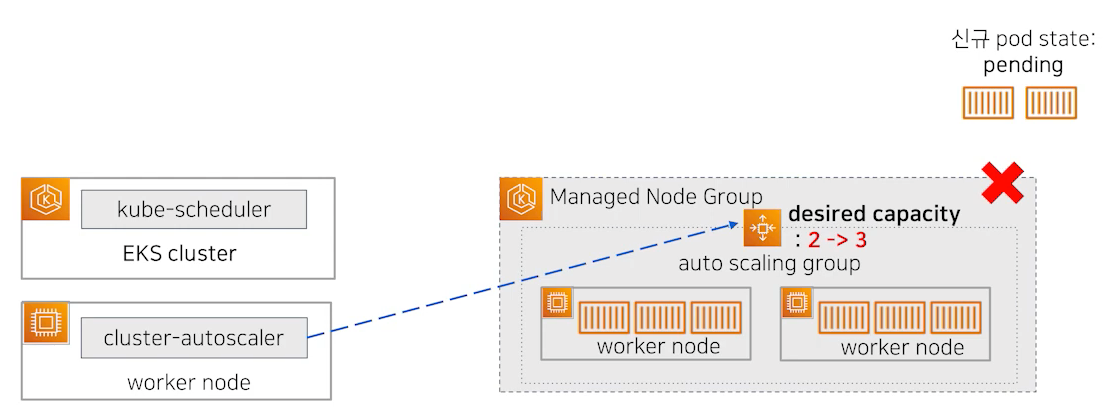
ASG는 수정된 Desired Capacity값을 읽고 EC2 워커 노드를 추가로 배포하게 됩니다. 이것은 Kubernetes와는 무관하고, AWS의 ASG에 의해 실행된 작업입니다. EC2 AMI, Instance Type은 AWS에 정의된 Launch Template에 있는 내용을 따르게 됩니다. 배포가 완료되어 노드가 Ready 상태가 되면 kube-scheduler는 배포되고 있지 못하던 pod를 새로운 워커 노드로 할당시킵니다. kube-apiserver에 해당 정보를 전달하고 kube-apiserver는 워커 노드에서 실행중인 kubelet에게 pod 배포 명령을 보내게 되고 파드가 해당노드에 프로비저닝 됩니다.
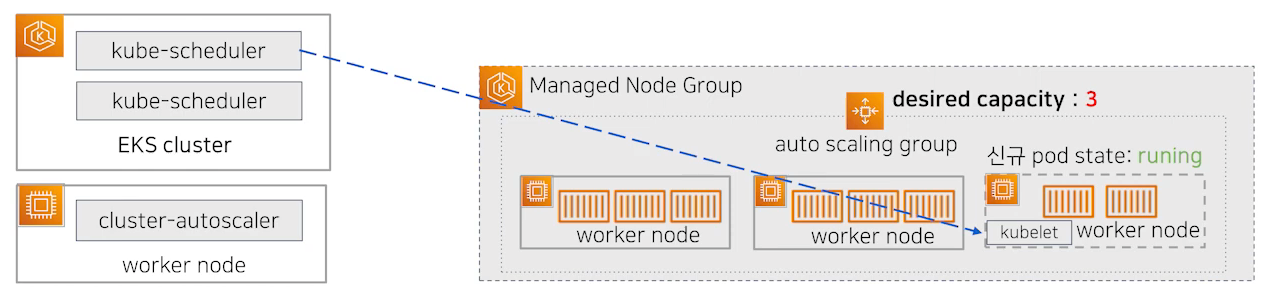
Karpenter의 동작방식
Karpenter는 ASG와는 조금 다른 구조로 동작하게 됩니다. Karpenter는 AWS에서 개발은 했지만 Cloud Provider와 무관하게 동작 가능한 구조로 설계되었습니다. Karpenter는 지속적으로 신규 pod의 상태를 확인하고 필요하다면 워커노드의 배포와 삭제도 직접 수행하고 kube-scheduler를 대신해서 pod를 특정 워커 노드쪽으로 바인딩 되도록 하는 요청도 수행합니다.
Karpenter의 자동 확장 시나리오
위에서 살펴본 상황과 같이 가용공간이 없는 상태에서 신규 pod생성 요청이 왔습니다. kube-scheduler가 신규 pod 배치할 적정 노드를 선정하는 것과 필터링 하는 과정은 같습니다. Unschedulabel 한 pod를 프로비저닝 해주려고 하는 상황인 것입니다.
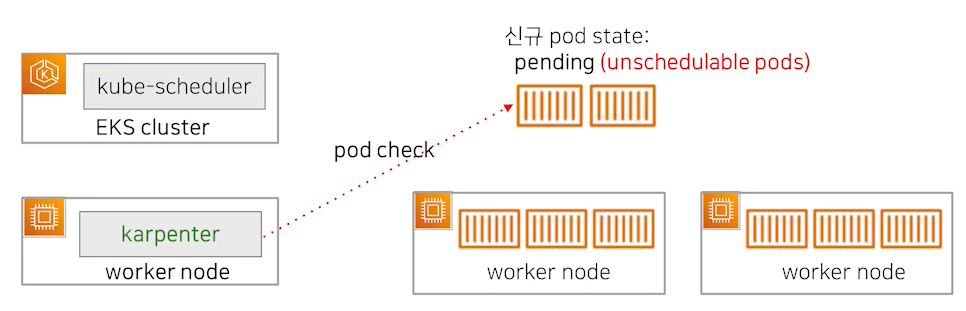
워커 노드를 생성할 때 어떤 인스턴스 타입을 선택해서 배포할 것인지를 정하는 과정에서 Node Group을 사용하는 Auto Scaling과 차이점이 있습니다. Karpenter는 자체 Custom Resource인 Provisioner를 등록하고 이것에 의해서 새 노드가 어떤 스펙일지를 결정합니다.
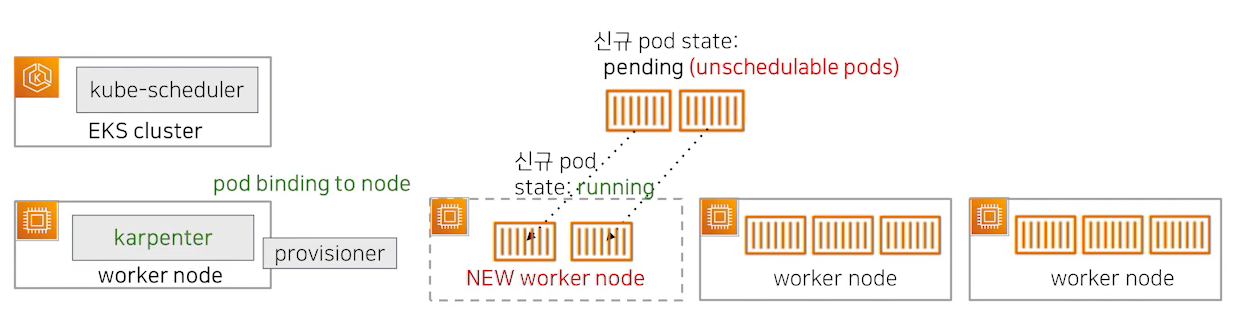
Karpenter는 결국 이 Provisioner를 통해 모든 워커 노드의 lifecycle을 결정할 수 있게 됩니다. Karpenter 역시 노드가 배포된 이후에 Ready상태가 되면 직접 pod를 새로운 워커 노드에 배포될 수 있도록 바인딩 요청을 하게 됩니다.
둘의 차이점?
둘의 차이점을 본다면, CA는 ASG와 같이 노드확장 같은 작업을 할때 Cloud Provider가 제공하는 기능들과 연계할 수 밖에 없습니다. 그렇기 때문에 훨씬 더 많은 단계를 거쳐야 하게 되고, 이 과정 때문에 노드의 배포과정이 느리고 번거롭게 됩니다.
Karpenter는 Auto Scaling 할때 일어나는 많은 부분을 Karpenter가 직접처리 합니다. 기존 ASG대비 훨씬 심플한 구조로 빠르게 처리가 가능해지는 것입니다.
🪚 Karpenter의 주요 개념
이제 이유를 알았고 둘의 차이를 대충 파악했으니, Karpenter의 주요 개념을 살펴보도록 하겠습니다. Karpenter는 크게 4가지 특성을 갖고 설명할 수 있습니다.
- Watching : unschedulable한 pod를 계속 보고 있습니다.(파드 자체를 계속 체크)
- Evaluating : 스케쥴링 하는데 제약이 없는지를 확인합니다.
- Provisioning : 요구사항에 맞는 노드에 파드를 배포합니다.
- Removing : 더 이상 노드가 필요없다면 삭제합니다.
그렇다면 무엇에 의해 노드가 생성되고 어떤 종류의 인스턴스일 것인지, 언제 노드를 삭제할 것인지 등등을 결정할 무엇인가가 필요합니다. 그 설정이 바로 Provisioner입니다.
Provisioner
Provisioner는 Custom Resource에 대해 작성한 것으로서, 노드 프로비저닝에 대한 제약사항이나 노드가 필요없다고 판단할 설정들, 예를 들어 timeout과 같은 것들을 설정합니다. 여러 설정들이 많지만 주요 설정들을 살펴보겠습니다.
- taints : 프로비저닝 된 노드들에 테인트를 정합니다. 파드가 taint에 대한 toleration이 맞지 않다면 taint에 설정된 대로 이벤트가 발생합니다.
- NoSchedule, PreferNoSchedule, or NoExecute
- labels : 파드에 매칭될 수 있는, 임의의 key-value를 노드에 붙입니다.
- requirements : Acceptable한 것에 In, Unacceptable한 것에 Out을 설정합니다.
- limits : 클러스터에서 사용할 전체 CPU와 메모리의 제한을 설정합니다.
- 이 설정을 통해 노드 프로비저닝을 효과적으로 중지할 수 있습니다.
Karpenter Demo 시나리오
이제 Karpenter가 얼마나 효과적이고 빠른지를 살펴보기 위해 Karpenter를 직접 세팅해 보겠습니다. 설치 과정은 공식 문서를 참조하시는 게 가장 깔끔합니다. 꼭 최신 버전인지를 한 번 더 확인하시기 바랍니다. 설치가 완료되었다면 샘플 Provisioner를 넣어보겠습니다.
1 | apiVersion: karpenter.sh/v1alpha5 |
이제 테스트를 할 새로운 namespace를 만들어주겠습니다(kubectl create namespace test). 그리고 해당 네임스페이스에 파드를 생성할 deployment를 만들고 파드를 10개로 늘려보겠습니다. (kubectl scale deployment inflate --replicas 10 -n test)
1 | apiVersion: apps/v1 |
이 설정에서 cpu를 굉장히 작게 요청했기 때문에 pod를 갑자기 늘렸을 때, 파드는 제대로 생성되지 못하고 Pending이 되어 있을 것입니다.
kubectl get po -n test를 통해 확인해보면 다음과 같습니다.
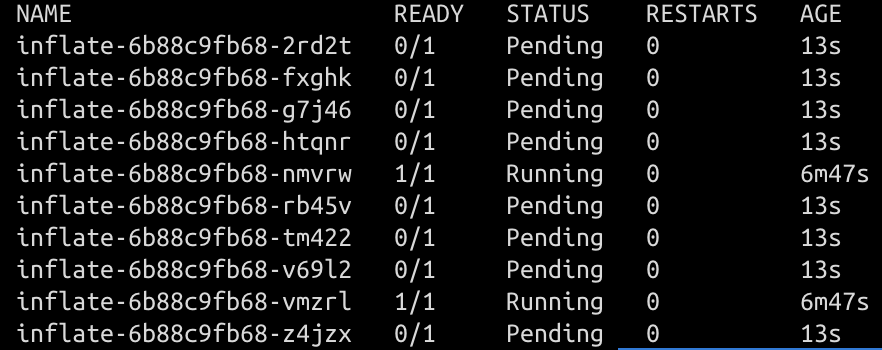
Provisioner에서는 어떤일이 일어나고 있을까요?(kubectl logs -f deployment/karpenter -c controller -n karpenter) Provisioner에서는 어떤 리소스가 부족한지를 파악하고 어떤 클러스터의 어떤 서브넷에 어떤 스펙의 노드를 추가할 지를 정하고 있습니다. 노드를 올리게 되고 Ready상태와 함께 pod들은 프로비저닝이 완료됩니다.

🤯 Trouble Shooting
karpenter v0.14.0를 사용하면서 provisioner의 requirement에 topology.kubernetes.io/zone 를 설정하고 파드를 프로비저닝 할 때 다음과 같은 에러를 만날 수 있습니다.
2022-08-15T21:16:31.881Z ERROR controller.provisioning Could not schedule pod, incompatible with provisioner "default", incompatible requirements, key topology.kubernetes.io/region does not have known values; incompatible with provisioner "labeltest", incompatible requirements, key topology.kubernetes.io/region does not have known values {"commit": "5edcce3", "pod": "monitoring/prometheus-helm-kube-prometheus-stack-prometheus-1"} (From Kuberentes Slack, karpenter channel. visokoo’s thread)
그래서 열심히 구글 검색도 해보고 하다가 슬랙방에 들어가서 비슷한 사례가 없는지 봤는데, 8월 16일에 비슷한 문제를 겪는 사람이 있었습니다. 결국 이유는 버그였습니다. 프로비저닝이 안되어서 2-3일 정도를 허비했는데 조금 허무 했습니다. 하지만 빠르게 버그 픽스가 되었고 v0.15.0이 올라오면서 이 문제는 해결 되었습니다. 꼭 최신 버전을 사용하시기 바랍니다!
Reference
karpenter에 대한 설명, eks에 적용하기