
Airflow Basic. 두 번째
Airflow 구조 파악하기, 실수 줄이기
글에 들어가기 전에…
Airflow의 구조에 대해서 들어가기 전에, Airflow의 컨셉에 대해서 간략하게 설명한 글이 있습니다. 기본적인 개념에 대해서 먼저 알고 싶으신 분은 Airflow Basic을 읽어주시면 감사하겠습니다. 간단하게 컨셉을 이해한 뒤에 이 글을 읽으시면 더욱 좋습니다.
Airflow 구성요소
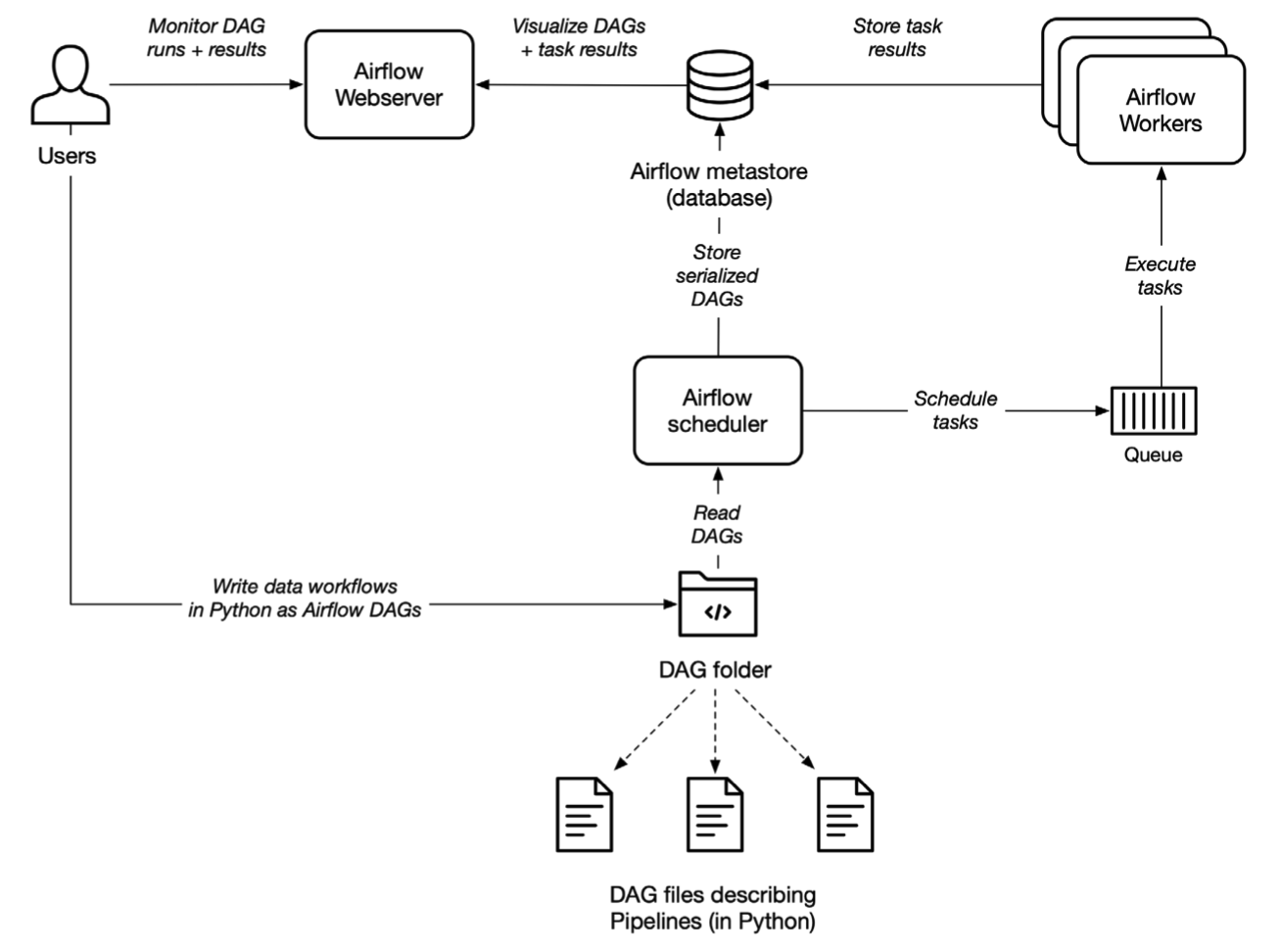
Airflow의 구성요소는 크게 3개입니다. Airflow Webserver, Scheduler 그리고 Worker 입니다. 실제로 Airflow를 설치하셨다면, airflow webserver, airflow scheduler, airflow worker 명령어를 입력하면 됩니다. 세 명령어를 다 입력했다면, airflow를 다 띄웠다고 할 수 있습니다. 운영하고 있는 Airflow 서버에서도 이상이 있으면 체크하는 것이 명령어를 입력한 세 개의 구성요소입니다. 먼저 Airflow의 구성요소에 대한 큰 그림을 보고 각 구성요소들에 대해서 설명해보도록 하겠습니다.
Airflow Scheduler
Airflow의 스케쥴러는 말 그대로 Airflow의 작업들을 스케쥴링 해줍니다. DAG들을 파싱해서 스케쥴된 작업들의 작업 간격을 확인하고 실제로 작업 명령을 워커에 전달합니다. 또한 DAG에 걸려있는 의존성을 확인하고 걸려있다면, 실행 큐에 더해줍니다. 이와같이 스케쥴러는 Airflow의 심장과 같은 역할을 수행하고 DAG와 직접적으로 붙어있습니다. 붙어야 하는 DAG의 위치는 airflow.cfg 파일에서 지정할 수 있습니다. airflow.cfg는 airflow에 대한 설정들이 모여져 있는 파일입니다.

하나의 서버에서 돌아가는 싱글구조의 Airflow라면 이 설정에서 딱히 조정할 것은 없습니다. 다만 mysql에 접속할때 사용하는 user명과 비밀번호를 넣어줘야 합니다. 싱글구조가 아니라면(워커와 스케쥴러가 분리되어 있다면) 스케쥴러의 ip주소도 넣어줍니다. configuration에서 result_backend와 sql_alchemy_conn을 찾아서 수정해줍니다. Airflow의 mysql 설정이 궁금하신 분들은 Airflow EC2에 구축하기를 참고하시면 좋습니다.


Airflow Worker
Airflow 워커는 스케쥴러에서 할당해놓은 작업들을 DB에서 갖고와서 실제로 실행합니다. 작업들은 DAG를 구성할때 queue를 이용해서 어떤 워커에서 수행할지 결정되고 워커는 큐를 설정해서 기동합니다. 워커는 airflow worker -q main 과 같이 큐를 설정할 수 있습니다. DAG에서 queue를 아래와 같이 지정해놓으면 스케쥴러는 해당 큐에 맞게 작업을 나눠놓고 워커는 자신의 큐에 맞는 작업을 찾아서 갖고옵니다. 찾은 큐를 워커에서 실행하고, 실행후 나온 로그들을 회수합니다. 이 로그들은 Metastore(Airflow DB)에 저장되고 저장된 로그들은 웹 서버를 통해 확인할 수 있습니다.
1 | t1 = BashOperator( |
워커가 큐를 찾아 가져오는 구조가 좀 특이합니다. 일반적으로 생각하기에는 스케쥴러가 워커에 작업을 보내줄 것 같은데, 그렇지 않습니다. 이 큐를 가져오는 구조 라는 특성 때문에 Airflow를 싱글구조에서 워커와 DB, 스케쥴러로 나누는 구조로 변경할때, 보안그룹 설정에서 스케쥴러의 인바운드 포트만 열어주게 됩니다. 스케쥴러의 인바운드 포트만 열어주고, 워커의 airflow.cfg로 들어가서 어떤 metastore에서 작업을 할당받을지 주소를 적어주면 끝입니다. 사실상 스케쥴러 인스턴스의 airflow.cfg만 가져와서 그대로 붙여주면 아주 쉽게 설정이 끝납니다.
Airflow Webserver
웹 서버는 Airflow의 Metastore 저장된 로그를 보여주거나 스케쥴러에 의해 파싱된 DAG들을 시각화해서 제공합니다. 이 UI를 통해 DAG들이 돌아가는 상황과 결과들을 확인할 수 있습니다.
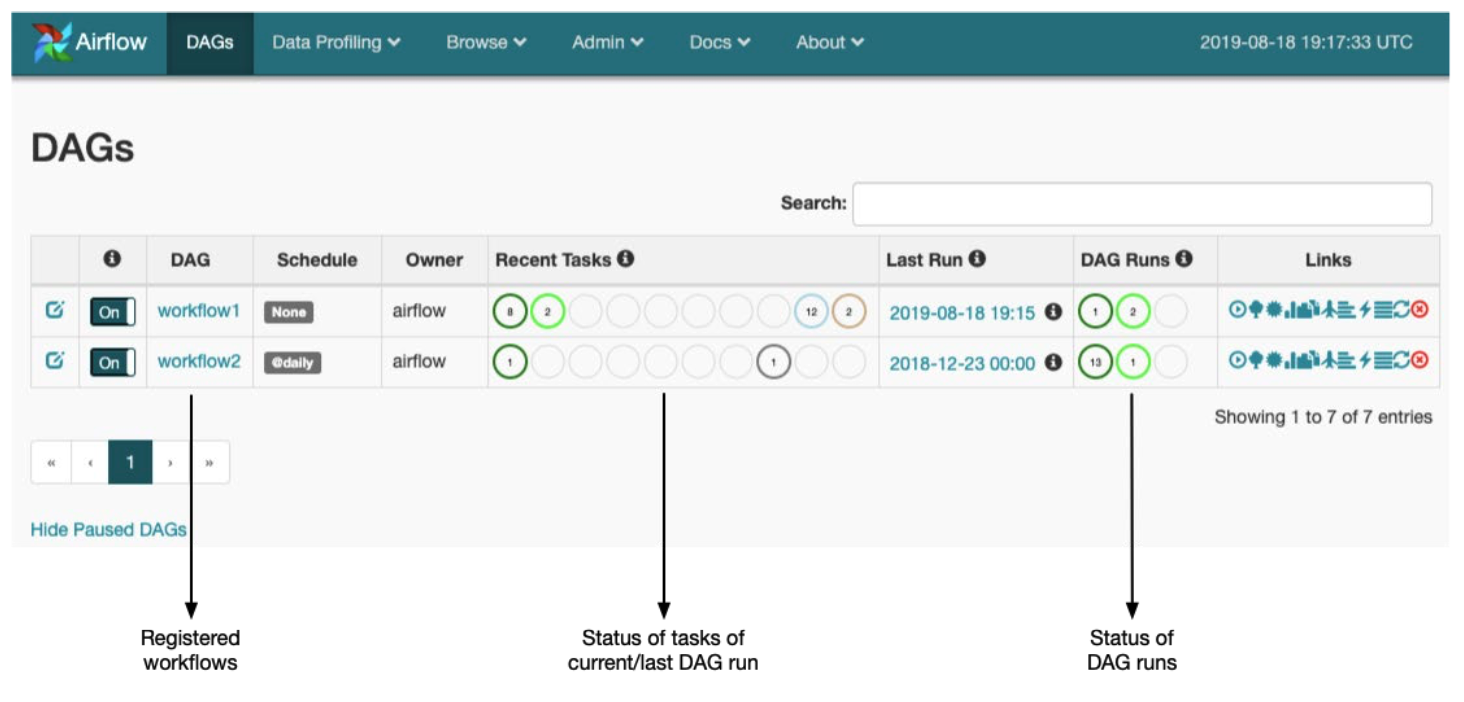
Dag를 만든 후에 스케쥴러가 Dag폴더의 위치를 찾으면 여기에 있는 Dag를 파싱해서 웹으로 보여줍니다. 가장 왼쪽에 On이라고 되어 있는 부분이 있는데, 맨 처음에는 Off로 되어 있습니다. 이것을 On으로 바꿔주고, 현재 시간이 Dag에 설정된 start_date 보다 나중 시간이라면 정상적으로 작업을 실행하고, 그렇지 않으면 작업을 수행하지 않습니다.
주의해야 할 점
Timezone, - UTC, KST
dag_name
병렬작업 설정
Airflow Basic에 있는 내용들을 종합하면 간단한 Dag는 작성해서 파이프라인을 만들 수 있을 것입니다. 여기서부터는 작업하면서 실수가 잦았던 부분에 대해서 다뤄보려고 합니다.
첫 번째는 시간대 설정입니다. 이 글을 보고 계시는 대부분의 분들은 KST시간대를 사용하시는 분들일 것입니다. 하지만 Airflow는 한국인이 만든 것이기 아니기 때문에, 모든 사람들이 다 사용할 수 있게 시간대를 UTC로 설정해두었습니다. 그래서, 작업하는 시간대와 Webserver에서 보여지는 시간대는 UTC를 사용합니다. 위 UI에서도 Last Run이 보이는데, 이것은 UTC시간대를 적용해서 나오는 시간입니다. 하지만, 만약에 Airflow를 AWS위에 올려서 사용하고 cron 스케쥴을 잡아서 실행한다면, 이 cron스케쥴은 KST를 적용받습니다.

위의 사진에서 보든이 schedule_interval에는 cron 스케쥴이 들어갑니다. 작성된 스케쥴을 그대로 읽으면 AM 01:30분에 돌아가게 됩니다. 지금은 글로 설명되어 있어서 ‘이게 왜 헷갈리지’ 라고 생각하실 수도 있겠지만, Last Run이나 Airflow의 Tree View를 보면서 작업 수행 시간을 확인하다 보면 스케쥴 인터벌에 UCT로 작성하는 큰 실수를 할 수 있습니다. 물론 이것은 개인의 경험에 의한 경고입니다. 시간을 잘 확인하는 습관을 들입시다.
Airflow 1.10.10 버전 부터는 UI에서 Timezone을 선택할 수 있다고 합니다.
두 번째는 dag_name입니다. Dag를 만들고 잘 돌아가면 보통 Dag를 새로 만들어서 구성하기 보다는, 복사해서 붙여넣고 자잘한 부분만을 수정하는 경우가 많습니다. 저도 그렇습니다. 이럴 경우에 다른 자잘한, 중요한 로직과 관련된 부분들은 수정을 잘 하는데, dag_name을 바꿔놓지 않는 경우가 많습니다. 이렇게 되면, Webserver에서 Graph view를 볼 때, Dag가 새로고침 할때마다 변경되는 기이한 현상을 목격할 수 있습니다. 분명히 변경이 된 것을 Code에서 확인을 했는데, 실제로 Graph View에 나오는 것은 이전 코드입니다. 새로 고침을 하면 또 수정된 코드로 보입니다. 이것은 만들어진 dag파일명은 다르지만 dag_name이 같아서 웹 서버가 같은 dag_name을 호출하기 때문입니다. 흔히 dag파일명으로 Airflow 웹 서버가 구분할 것이라고 생각하지만, 웹 서버는 dag_name을 읽어옵니다. 이 dag_name은 위 사진에서처럼, with DAG()안에 들어갑니다.
세 번째는 병렬작업 설정입니다.
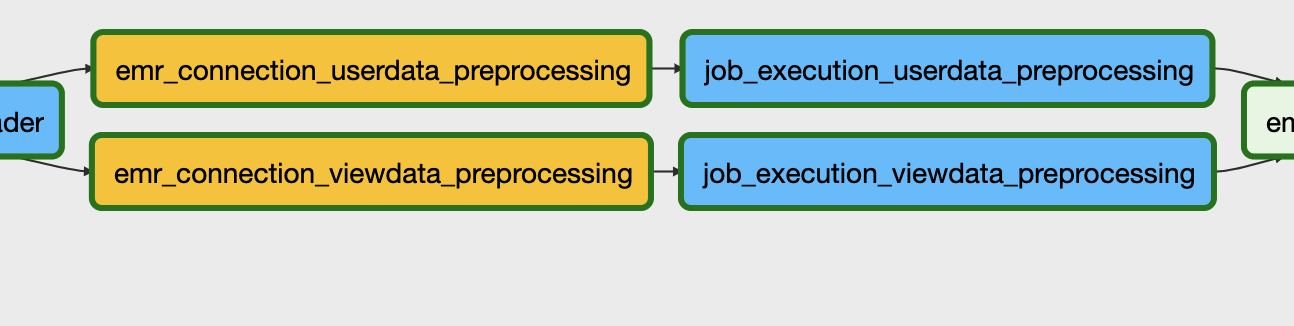
어떤 작업을 사진처럼 병렬로 예쁘게 실행시키고 싶을 때가 있습니다. 물론 이것은 그림으로만 병렬이고, 실제로는 작업이 하나씩 돌아가는 구조입니다. 그 이유는 코드를 확인해보면 됩니다.
1 | for file in files: |
병렬 구조로 돌리는 것은 사실 for문으로 묶여있습니다. 병렬처럼 묶는 방법은 다양하지만 여기서는 for문을 사용했습니다. 이렇게 for문으로 구성하고 작업 순서를 부등호를 이용해서 정해주면 끝이지만, 여기서 실수가 자주 발생합니다. indentation 을 집중해서 보셔야 합니다. 여기서 작업 순서가 적힌 dataloader~~ 부분을 부면 for문 안쪽으로 indentation이 잡혀있습니다. 보통 for문을 다 작성하면 ‘다 됐다!’라는 생각에 tab을 치지 않고 작업순서를 넣는데, 이렇게 되면 병렬로 잡힐거라고 생각했던 작업이 다 깨져버리게 됩니다. Tab을 꼭 한번 눌러주고 작업 순서를 작성해주시면 아주 좋습니다.
덧붙여,
Airflow를 이용하면 위 코드에서처럼 EMR을 연계해서 작업을 수행할 수 있습니다. Airflow의 장점중에 하나인데, 다양한 Hook과 Operator가 많다는 것입니다. Hook과 Operator를 조합하면 다양한 서비스 파이프라인을 개발할 수 있습니다. Airflow와 EMR을 연계해서 Spark job을 실행하고 값을 저장 부분은 다음 글로 작성해보도록 하겠습니다. 부족한 글 읽어주셔서 감사합니다.
Airflow Basic. 두 번째