
Apriori와 FP-Growth. 추천 시스템 시리즈
추천 시스템에 대해서, Apriori와 FP-Growth
추천시스템은?
추천시스템은 사용자에게 상품을 제안하는 소프트웨어 도구 이자 기술입니다. 추천 시스템은 사용자 입장에서 수십 만개의 상품 풀에서 원하는 것을 빠르게 찾을 수 있다는 점에서 큰 의의가 있습니다. 제가 가장 많이 접하는 Youtube 추천 영상을 생각해보면 이해가 빠릅니다. 영상은 하루에도 수억개가 올라올테지만, 제가 원하는 것이 아주 잘 올라오는 것을 확인할 수 있습니다. 추천 시스템이 없다면 영상을 찾는데 시간이 너무 오래 걸릴 것입니다. 기업 입장에서도 추천은 매우 중요합니다. 사용자가 영상을 찾는데 너무 많은 시간을 소비한다면, 짜증을 느낄 것이고 이 플랫폼에 대한 이용율이 떨어질 것입니다. 또한 커머스라면 적절한 상품을 추천을 함으로써 매출을 극대화 시킬 수 있겠습니다.
그렇다면 추천 시스템에서는 사용자가 누구인지 타겟팅 하는 것이 중요해집니다. 하지만, 사용자를 타겟팅하는 것은 사업부나 마케팅 입장에서 아주 상이한 점이 있습니다. 그리고 추천 목적도 도메인 마다 상이하므로 이 부분은 생략하고 넘어가도록 하겠습니다.
추천 시스템의 흐름
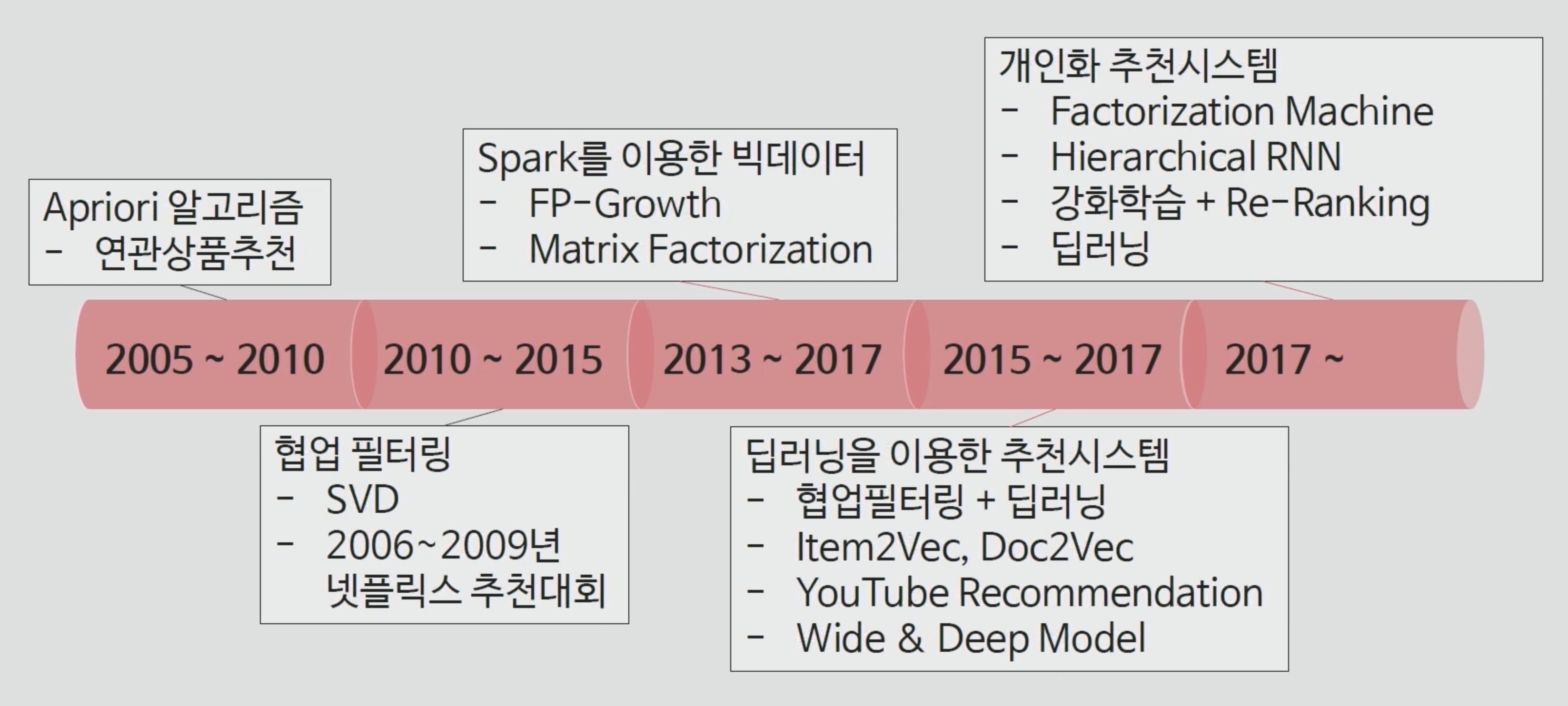
추천 시스템이 어떻게 발전해 왔는지 살펴보겠습니다. 05년에 먼저 시작된 것은 연관 상품 추천, 장바구니 분석으로도 잘 알려진 Association Rule과 Apriori 알고리즘입니다. 이 알고리즘은 같이 구매하는 상품의 패턴을 잘 파악할 수 있는 알고리즘이였습니다. 이것이 발전하는 와중에 협업 필터링이 새롭게 등장했고 넷플릭스 추천대회를 통해 ALS등의 고급 테크닉이 나오게 되었습니다. 그러던 와중 Apriori의 한계를 극복하려는 시도로 만들어진 FP-Growth가 등장했습니다. 2010년대가 넘어가면서 많은 데이터를 쌓아두기 시작하는 빅데이터 시대가 열리게 되었고, 이 역사적 흐름에 맞춰 Spark와 Spark를 이용한 다양한 추천 알고리즘이 등장하기 시작했습니다. 이후에는 딥러닝을 이용한 다양한 추천시스템이 나왔고, 최근에는 개인화 추천시스템으로 넘어가고 있습니다. 이 흐름에서 오늘은 추천의 흐름 맨 앞단인, 연관상품 추천 부분을 다뤄보겠습니다.
Association Analysis
Association Analysis는 룰 기반의 분석입니다. 상품과 상품 사이에 어떤 연관이 있는지 알아보기 위해 시작한 분석입니다. 우리말로 해석하면 연관 분석이 되겠습니다.
여기서 연관에 대해서 정의해볼 필요가 있습니다. 연관은 무엇일까요?
연관은 얼마나 잦은 빈도로 구매를 하는지, A에서 B를 구매하는 패턴을 의미합니다. 이 연관 분석은 흔히 장바구니 분석이라고도 불리며, 가장 유명한 예시는 역시 맥주과 기저귀 분석일 것입니다. 하지만 이 맥주와 기저귀 예시에서 보더라도, 이 분석으로 나온 결과가 상관 관계가 그리 크지 않았습니다.
Association Analysis, Metric
이 규칙의 평가 지표에 대해서 알아보겠습니다. 어떤 분석에는 항상 지표가 있어야 평가를 할 수 있고, 이 평가를 통해서 분석 방법을 개선할수도 있겠습니다. 이 지표는 세 가지로 나뉩니다.
- support, 지지도
- A→B에 대해서 조건 A에 대한 확률을 보는 것.
- P(A) 또는 P(A,B)
- $P(A)$
- confidence, 신뢰도
- A상품을 구매했을 때, B상품의 구매까지 이어질 확률
- $confidence(A\rightarrow B)=\dfrac {P(A,B)}{P(A)}$
- lift, 향상도
- 사건이 동시에 얼마나 발생하는지 비율, 독립성을 측정
- $lift(A\rightarrow B)=\dfrac {P(A,B)}{P(A)\cdot P(B)}$
연관 분석 관련 알고리즘은 흔히 지지도를 베이스로 잡고 연관도를 측정하는데, 신뢰도와 향상도를 항상 고려하면서 추천 분석을 진행해야 좋은 결과가 나올 수 있습니다.
Association Analysis 적용하기
이제 본격적으로 연관 분석을 진행해 보겠습니다. 먼저 상품이 4개 있다고 가정하겠습니다. 이 연관 분석은 가능한 모든 경우의 수를 찾아내고 지지도와 신뢰도, 향상도가 높은 규칙들을 찾아내야 합니다. 그렇다면 모든 경우의 수는 몇 가지가 될까요? 고등학교 수학시간에 배운 개념을 한 번 떠올려 봅시다.
- 4개의 상품일 때 경우의 수
- ${}_4 \mathrm{C}_1+ {}_4 \mathrm{C}_2 +{}_4 \mathrm{C}_3 + {}_4 \mathrm{C}_4 = 15$
15개의 경우의 수가 나왔습니다. 이렇게 연관 분석은 모든 경우의 수를 계산해서 진행해야 합니다. 아이템 수가 많아진다면 어떻게 될까요? 결과가 예상되기 시작합니다.
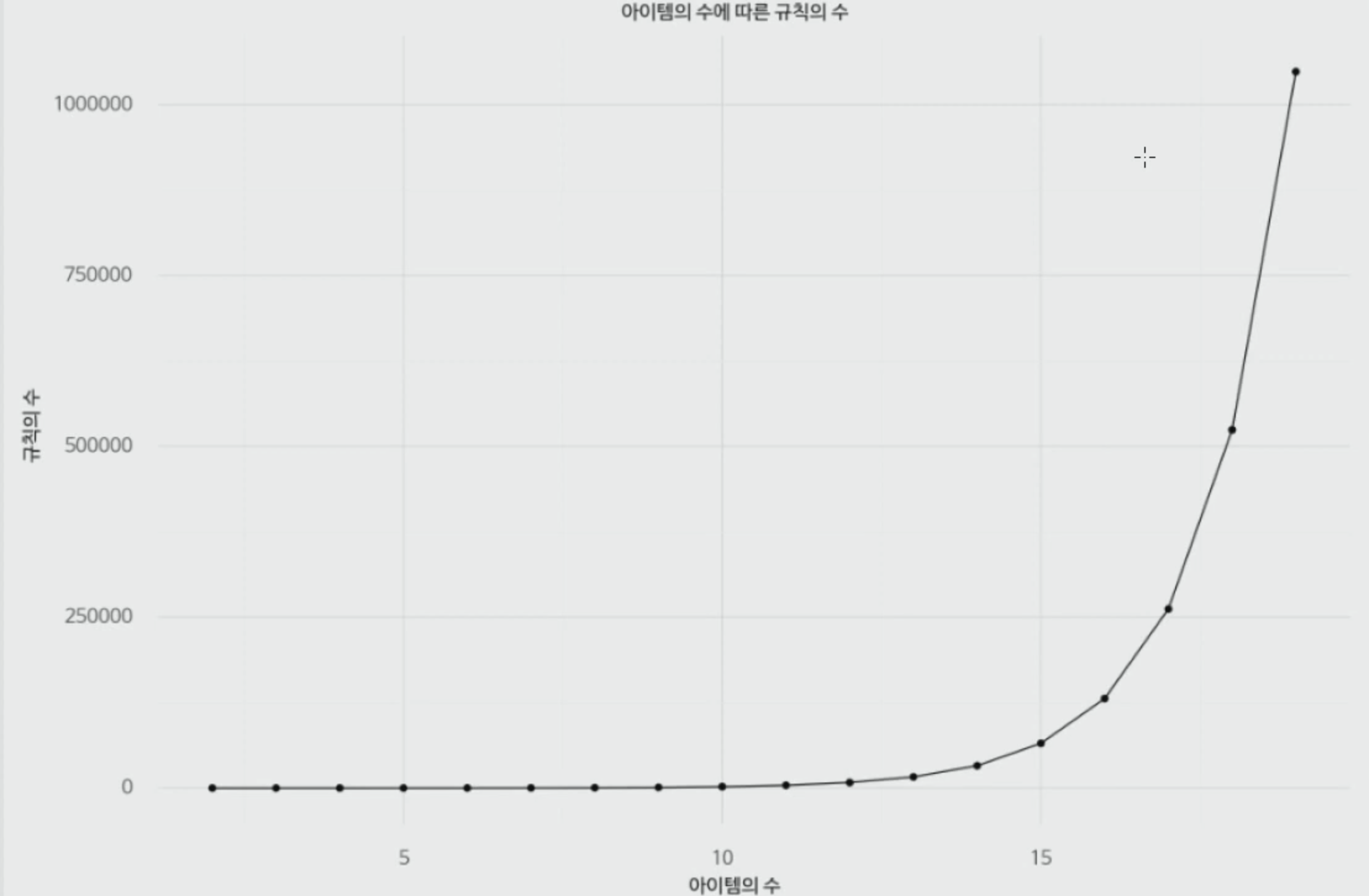
아이템이 100개라면 $1.26\times10^{30}$ 으로 엄청난 코스트가 발생합니다. 이를 극복하기 위해서, Aprirori가 등장했습니다.
Apriori
Apriori는 아이템 셋의 증가를 효과적으로 줄이기 위해 다음과 같은 가정을 사용합니다.
- 빈번한 아이템셋은 하위 아이템 셋 또한 빈번할 것
- 빈번하지 않은 아이템셋은 하위 아이템 셋도 빈번하지 않다. 고로 빼버리자!
글로는 이해가 잘 안되니 큰 그림을 갖고 이해를 한 번 해보도록 하겠습니다.
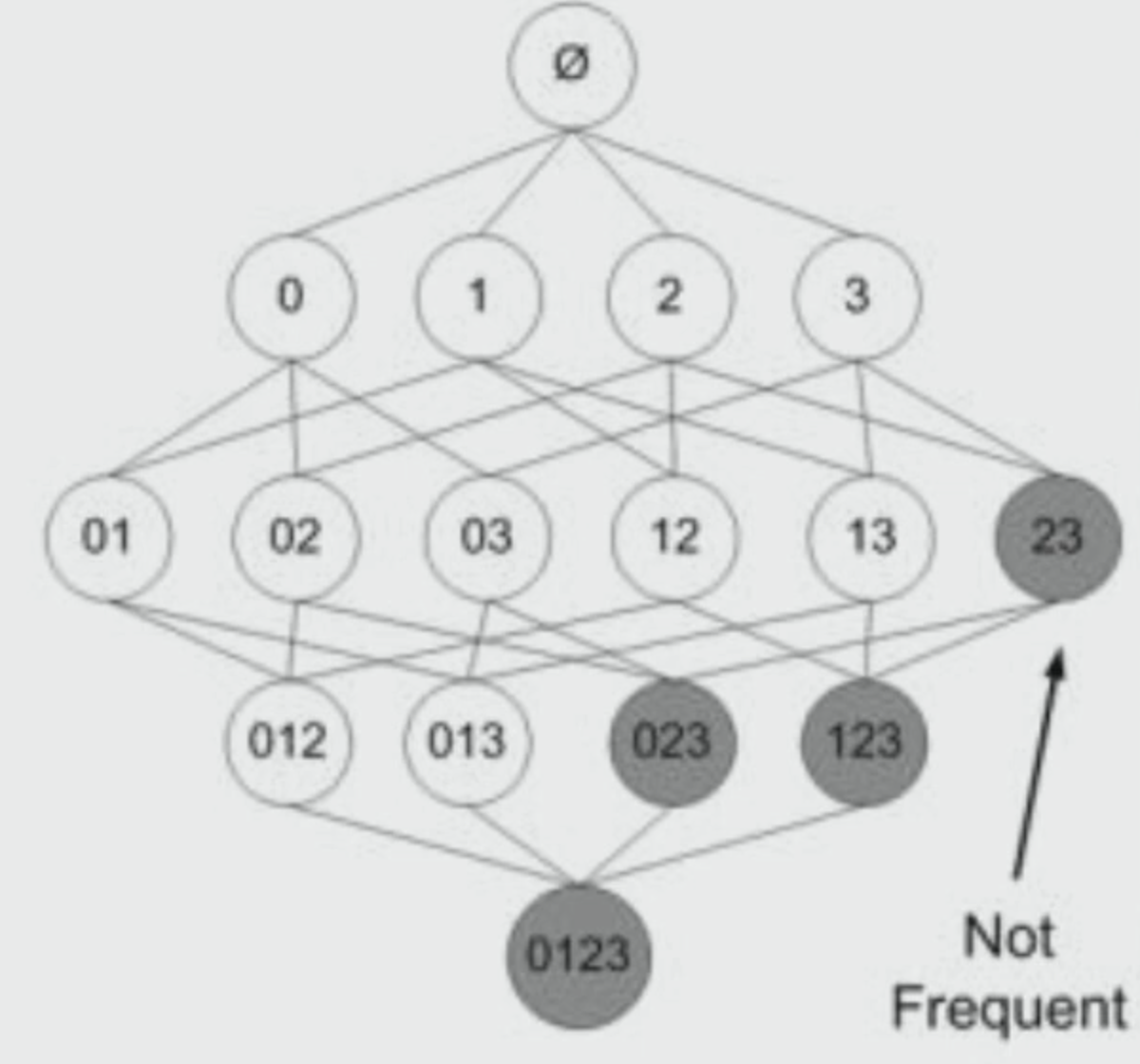
- 맨 처음에 4개의 아이템에 대해서 단일 항목집단을 만들어 냅니다.
- 2,3 아이템 셋이 빈번하지 않다고 한다면(서포트가 가장 낮다면), 가정에 따라 그 하위인 023, 123, 0123도 빈번하지 않을 것이다!
- $Support(2,3) > Support(0,2,3), (1,2,3)$
이런 식으로 진행이 됩니다. 이것을 정리하자면 다음과 같습니다.
- k개의 아이템을 가지고 단일항목집단 생성
- 단일항목집단에서 지지도 계산 후 최소 지지도 이상의 항목만 선택
- 2에서 선택된 항목 만을 대상으로 2개항목집단 생성
- 2개항목집단에서 최소 지지도 혹은 신뢰도 이상의 항목만 선택
- 위의 과정을 k개의 k-item frequent set을 생성할 때까지 반복
이제 본격적으로 예를 들어 진행해보도록 하겠습니다.
Apriori 적용하기
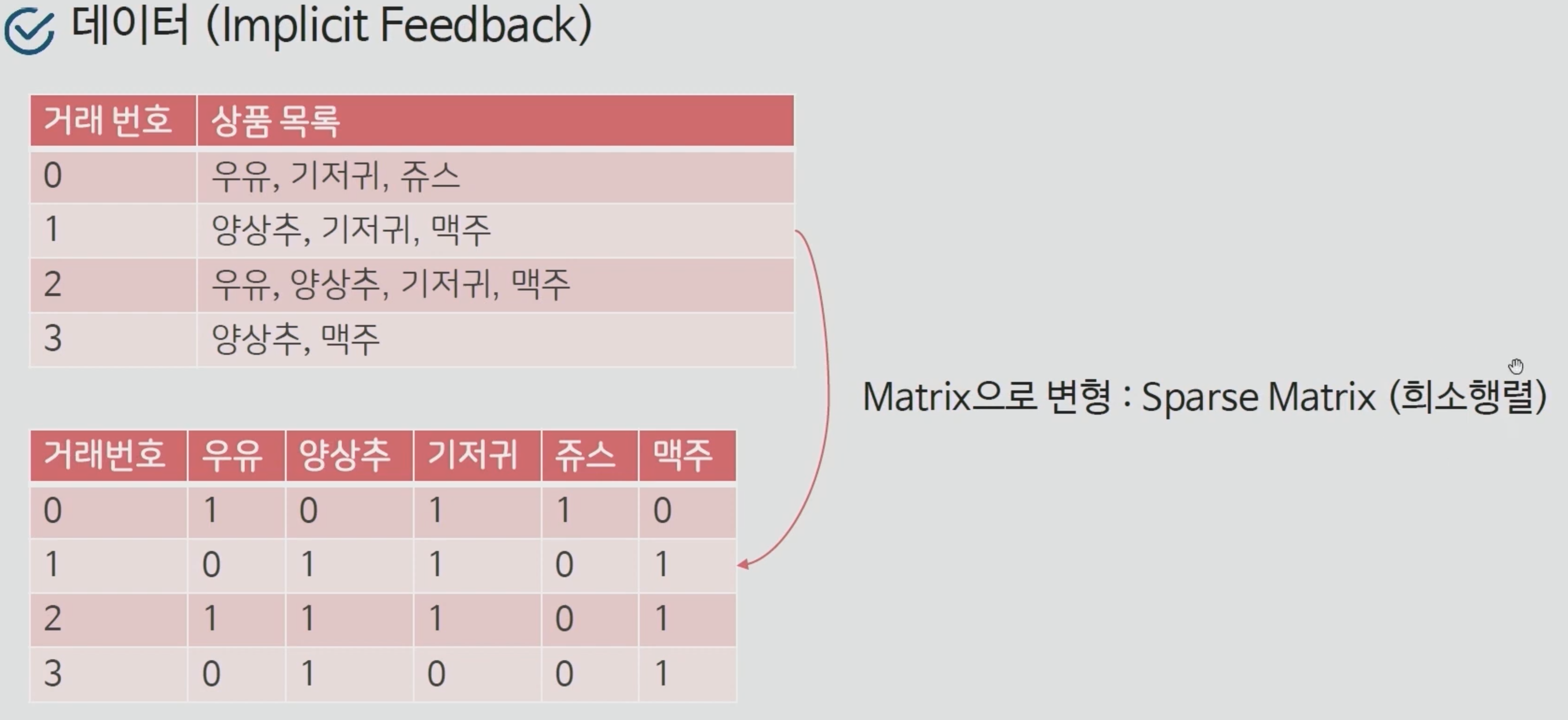
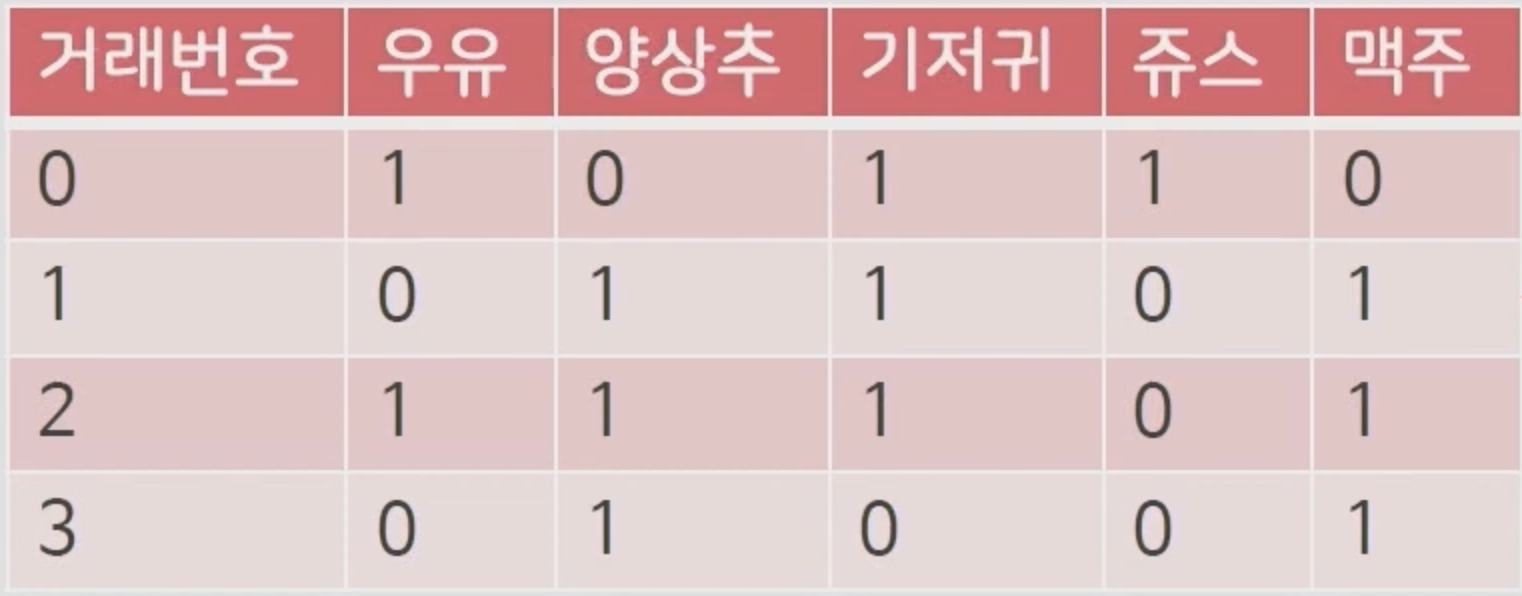
다음과 같이 위에 Transaction 데이터가 주어졌습니다. 이 데이터를 잘 분리해서 0과 1로 이루어지는 Sparse Matrix로 만들어줍니다. 재료가 준비되었다면, 아까와 같이 단일 항목집단을 생성해줍니다.
단일 항목집단 생성 및 최소 지지도 계산

위의 매트릭스를 갖고 각 항목에 대해 서포트를 계산해봅시다. 우유는 전체 4건의 거래번호에서 2개만 있으므로 0.5가 되고, 양상추를 4건에서 3개가 있으므로 0.75가 됩니다. 이렇게 보듯이 서포트는 확률에 대한 값을 의미합니다. 여기서 최소의 서포트를 가지는 쥬스를 과감하게 삭제해줍니다.
2개 항목집단 생성

위에서 선택한 항목을 기반으로 2개 항목 집단을 만듭니다. 4개의 항목을 가지고 2개씩 붙여주는 집합을 구성하면 됩니다. 조합을 이용하면 ${}_4 \mathrm{C}_2=6$ 6개의 집단이 만들어집니다. 이 역시 서포트를 계산해주고 최소 서포트를 가진 집단을 지워줍니다.

이것을 정리해주면 위와 같이 진행됩니다. 생각보다 많은 연산이 줄어든 것을 확인할 수 있습니다. 여기까지 Support를 바탕으로 알고리즘을 진행했습니다. confidence와 lift도 활용해서 진행할 수 있고, 다른 지표들도 잘 확인해야 한다는 점을 꼭 알아 두시면 좋습니다.
Apriori의 장 단점
이 알고리즘의 장 단점은 명확합니다. 장점은 일단 너무 쉽습니다. 원리가 간단해서 쉽게 이해할 수 있고 이 의미를 쉽게 파악할 수 있습니다. 또한 유의한 연관성을 갖는 구매패턴을 다양하게 찾아주는 장점을 가지고 있습니다.
다만, 단점은 데이터가 커질 때 발생합니다. 데이터가 크다면 속도가 느리고 연산량이 그래도 또 많아집니다. 그리고 실제 알고리즘을 사용하게 되면 너무 많은 연관상품들이 나타나는 문제가 발생합니다. 그리고 장점에서도 보이듯이 상품들의 유의한 연관성, 즉 연관 상품들이 상관관계는 의미하지만 그것이 인과를 의미하진 않습니다. 결과만을 본다면 어떤 것이 원인인지 파악하기 힘듭니다. 치킨과 치킨무를 예를 들어보면, 이 둘은 장바구니에 같이 담기는 패턴이 굉장히 많을 것입니다. 서포트가 높기 때문에 추천 셋으로 많이 등장할 것입니다. 하지만 결과만을 보고 치킨무를 샀기 때문에 치킨을 구매한 것인지, 치킨 때문에 치킨무를 산 것인지 알기는 힘듭니다. 우리의 경험에 의한 지식으로 당연히 치킨이 원인이라는 것을 단번에 알 수는 있지만, 복잡한 패턴이 나오면 판단하기 쉽지 않습니다.
FP-Growth(Frequent Pattern)
FP-Growth는 데이터가 점점 많이 쌓이기 시작하면서 Apriori의 연산 속도를 개선하기 위해 등장했습니다. 이 연관 규칙을 어떻게 효과적으로 빠르게 만들 수 있었을까요? 코딩 알고리즘을 배우면 많이 등장하는 개념이 있습니다. Tree 입니다.
핵심 아이디어 : 연관 규칙을 트리로 만들어 단점을 개선해보자!
FP-Growth도 기본적인 성질은 Apriori를 따라갑니다. 따라서 기본적인 설정은 Apriori와 거의 같습니다. Tree 구조를 활용했다는 점만 다르다고 볼 수 있습니다. 알고리즘을 적용하는 순서는 다음과 같습니다.
모든 거래를 확인해 각 아이템마다의 서포트를 계산하고 최소 지지도 이상의 아이템만 선택
모든 거래에서 빈도가 높은 아이템 순서대로 순서를 정렬(여기서 부터 달라짐)
부모 노드를 중심으로 거래를 자식노드로 추가해주면서 tree를 생성
새로운 아이템이 나올 경우에는 부모노드부터 시작하고, 그렇지 않으면 기존의 노드에서 확장
위의 과정을 모든 거래에 대해 반복하여 FP Tree를 만들고 최소 지지도 이상의 패턴만을 추출
자, 이제 아까의 데이터를 갖고 FP-Growth를 적용해봅시다.
FP-Growth 적용하기
데이터는 똑같이 준비해 놓았습니다.
주스는 똑같이 삭제
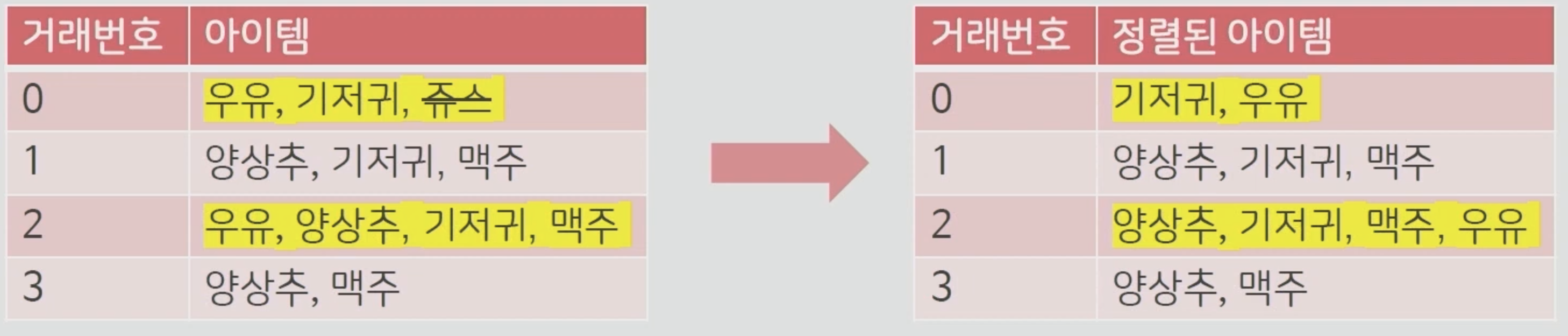
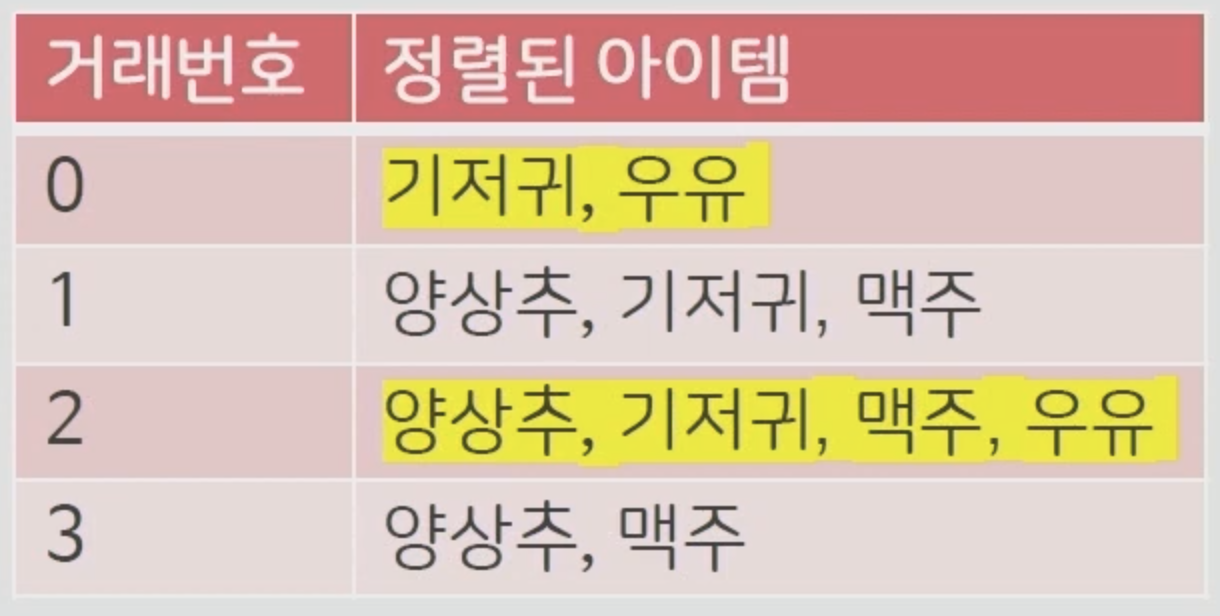
주스를 삭제하고 정리를 한번 해줍니다.
트리 형성
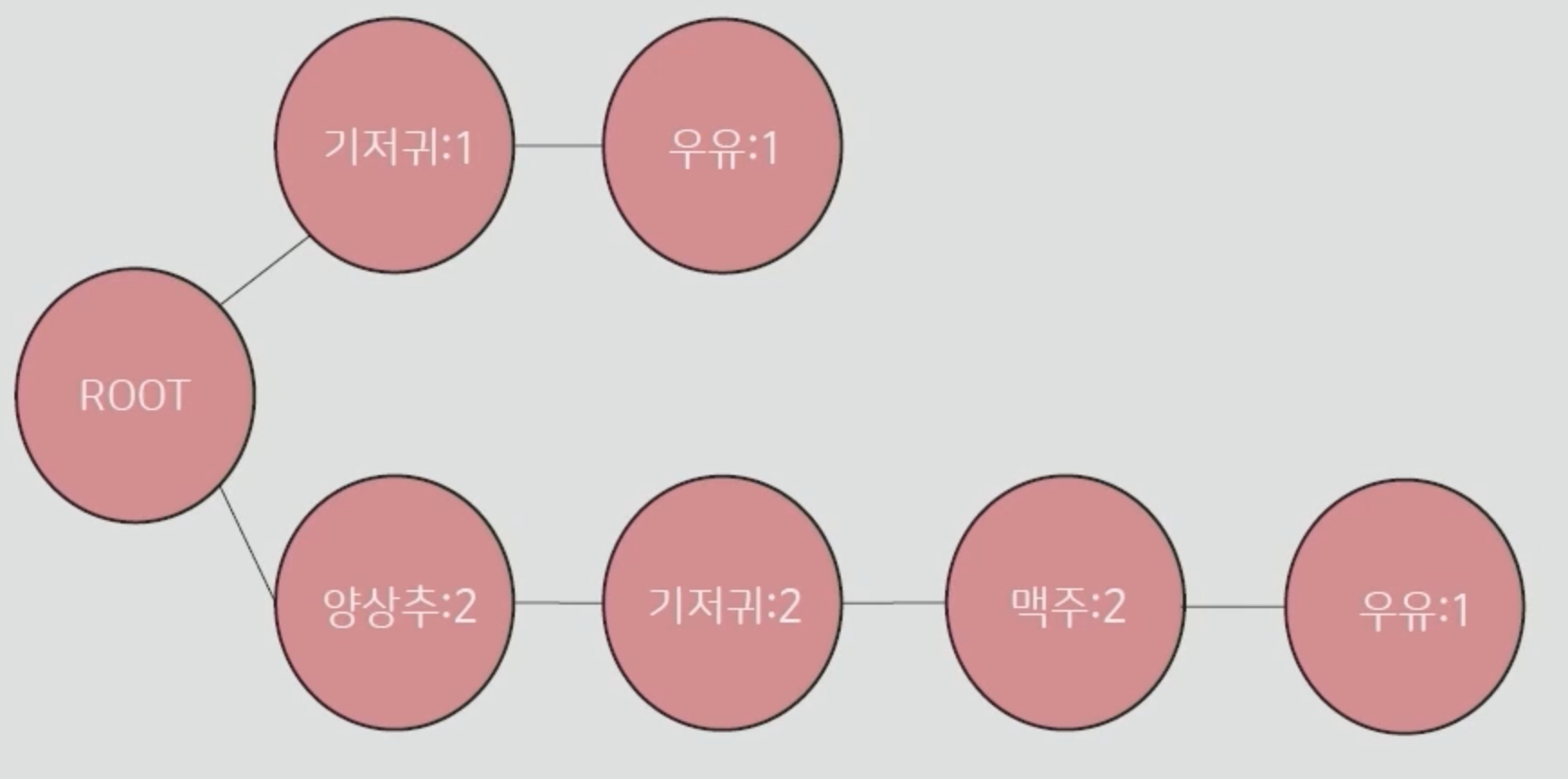
트리를 만드는 과정은 생각보다 간단합니다. 먼저 Root 노드를 만들어주고, 가장 빈도가 높은 순으로 노드 옆에 붙여줍니다. 여기에서는 기저귀와 양상추로 노드를 구성해보겠습니다. 거래번호 0의 아이템대로 기저귀 옆에 우유 노드를 붙여주고, 양상추에도 기저귀와 맥주, 우유를 붙여줍니다. 거래번호를 따라가면서 같은 아이템이 나온다면, 그림과 같이 아이템 옆에 숫자를 +1 시켜줍니다.
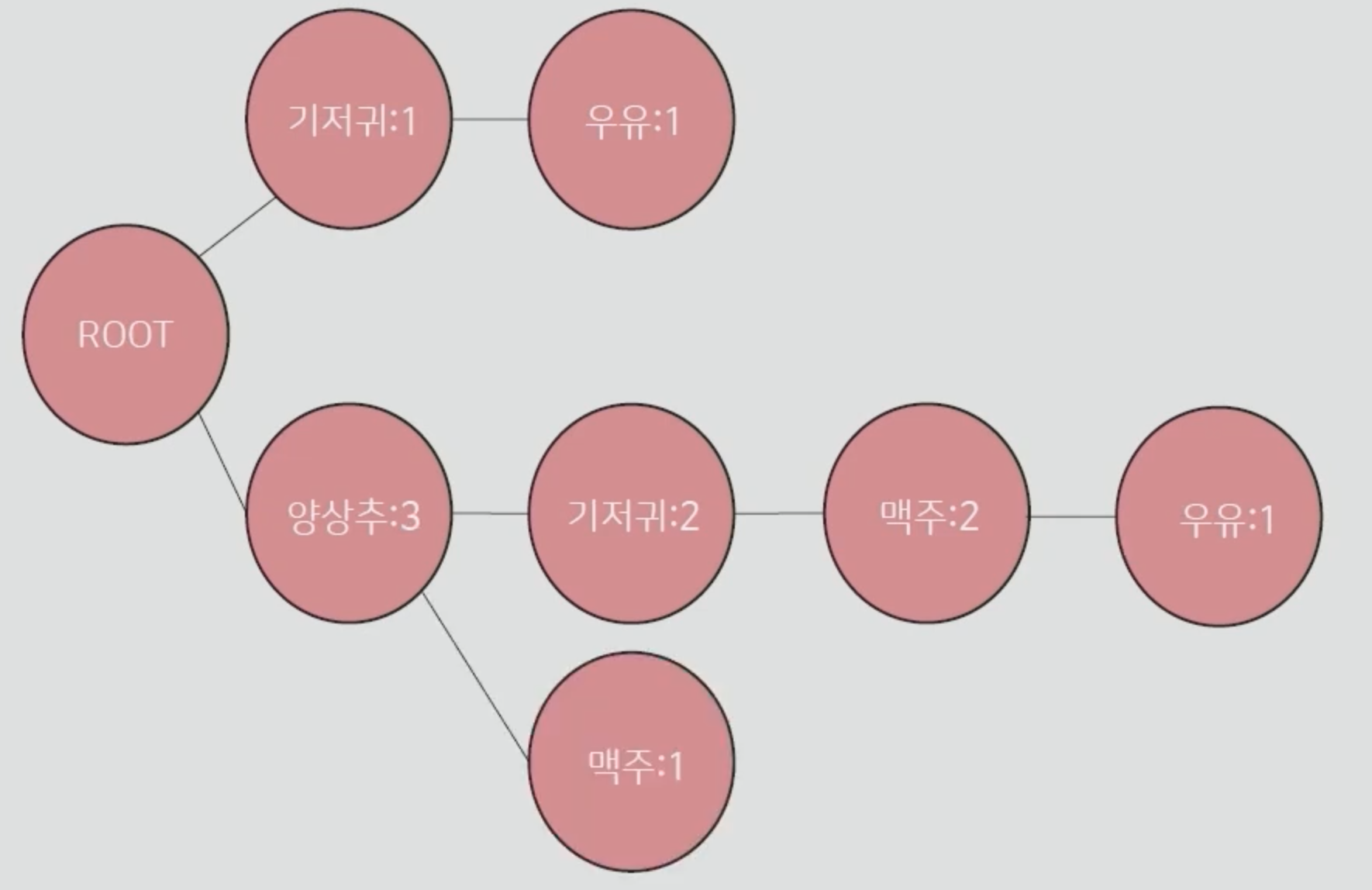
연관 규칙 찾기, 지지도 낮은 순서 부터 조건부 패턴을 생성 (우유부터 시작)
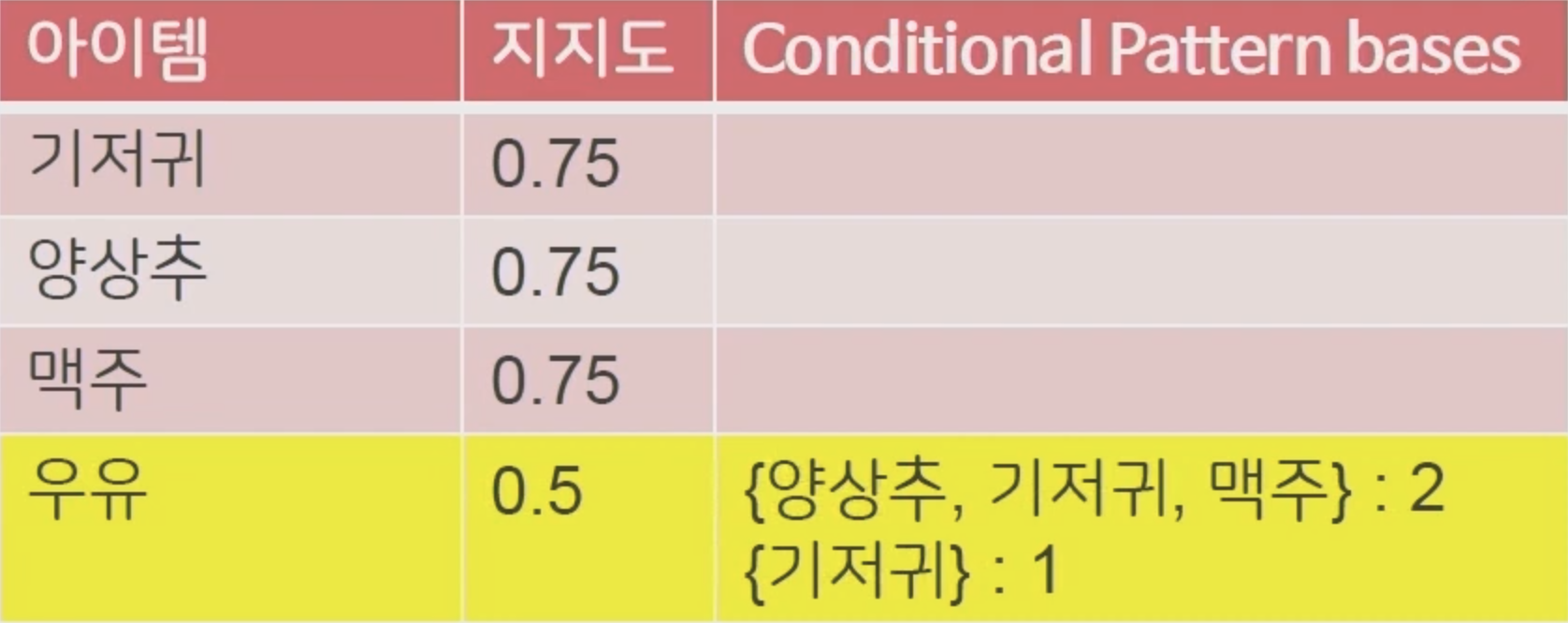
이제 서포트가 낮은 순서부터 조건부 패턴을 만들어줍니다. 우유의 서포트가 가장 낮으므로 우유가 붙어있는 노드를 따라가서 조건부 패턴을 파악해줍니다.
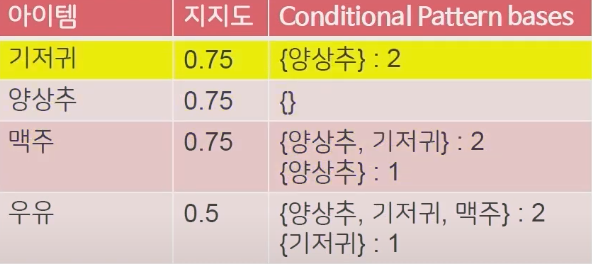
이런식으로 조건부 패턴을 다 파악했다면, 어떤 아이템이 들어왔을 때 트리를 통해서 추천 아이템을 전달할 수 있게됩니다. 위의 조건부 패턴 표를 보고, 맥주를 구매한 고객이 등장한 경우를 생각해보겠습니다. 맥주가 들어온 고객에게는 기저귀를 구매한 경우와 양상추를 구매한 경우로 나뉘게 됩니다. 양상추를 구매한 경우는 거기서 더 진행이 되지 않으므로 끝이나고, 기저귀를 구매했다면 더 깊게 들어가 양상추까지 구매한 패턴을 알 수 있게 됩니다. Tree를 타고 진행이 된다는 것이 느껴지시나요? Tree구조라는 점이 FP-Growth의 가장 큰 특징입니다.
FP-Growth 장 단점
장점은 역시 Tree구조이기 때문에 Apriori보다 훨씬 빠르며, DB에서 스캔하는 횟수도 줄어들게 됩니다. Apriori와 비교하면, Apriori는 최소 한 번의 DB스캔에서부터 가장 긴 트랜잭션의 아이템 셋을 뒤져야 할 가능성이 있는 반면, FP-Growth는 첫번째 스캔으로 단일 항목집단을 만들고, 두 번째 스캔으로 Tree구조를 완성합니다. 완성한 FP-Tree를 이용해서 분석하면 되니까, 딱 2번만 스캔하면 됩니다. 후보 Itemset을 생성할 필요없이, Tree만 구성하면 끝인 것입니다.
단점은 아직도 대용량 데이터 셋에서 메모리를 효율적으로 사용하지 않는다는 점입니다. 초기 알고리즘이라 그런 점이 있지만 이 한계 때문에 다양한 시도들이 제안되었습니다. 또한 Apriori에 비해 설계하기 어렵고, 서포트의 계산은 무조건 FP-Tree가 만들어져야 가능하다는 단점이 존재합니다.
연관 분석 알고리즘의 한계
마지막으로 이 알고리즘들의 한계에 대해서 지적해보면서 글을 마무리 해보려고 합니다. 글을 쭉 읽다보면, 최소 서포트에 대한 개념이 자주 등장합니다. 최소 서포트는 아이템이 많아지게 되면서 설계자가 직접 지정해야 합니다. 아이템 셋을 얼마나 뽑아낼지, 얼마나 상관관계가 괜찮은지에 따라 서포트 값을 설정해주어야 하는 것입니다. 하지만, 최소 지지도를 선정하는 정답은 존재하지 않습니다. 계산 공식은 없고 여러 지표들을 조합해서 분석하면서 최적의 값을 지정하곤 합니다. 가장 큰 한계점으로, 실제 서비스에서는 최적 서포트 값이 매번 바뀌므로 계산하는 공식이 필요한데, 사실상 만들기는 불가해서 서비스에 잘 사용하지 않고 있습니다. 다만 많은 패턴들을 보여주는 장점이 있기 때문에 베이스라인으로 사용해서 EDA하는 식으로 많이 활용하고 있습니다.
또한 인과를 알기 어렵다는 한계가 발견됩니다. 이렇게 원인과 결과를 확실하게 분석하고 싶다는 아이디어가 등장하면서 Casual Inference라는 연구분야가 자연스럽게 만들어졌습니다. 인과 추론에 관심있는 분들은 Causual Inference 키워드로 찾아보시면 좋습니다.
그리고 메모리와 시간을 너무 많이 소비하는 알고리즘이기 때문에, 즉, 가성비가 잘 나오지 않아 사용하기 힘듭니다. 최근이야 Spark를 통해서 대용량 처리도 가능해졌긴 하지만, 굳이 큰 비용을 들이면서까지 연관분석을 하려는 시도는 많이 보이지 않는 것 같습니다. 위에서 지적한대로 지표를 직접 지정해줘야하는 문제와 더불어 서비스에 잘 활용되지 않는 큰 이유 중에 하나입니다.
이런 한계들 때문에 Collaborative Filtering 계열 알고리즘이 부상하기 시작했고, 목적에 따라 user based추천, item based 추천을 생성하기 시작했습니다. CF의 한계와 더 좋은 성능을 위해서 딥러닝을 활용해 패턴을 인식시키고자 하였고, 최근에는 개인화 추천까지 발전해오고 있는 흐름입니다.
Reference
- T-Academy : https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=194
- ratsgo’s blog 연관규칙 : https://ratsgo.github.io/machine learning/2017/04/08/apriori/
- 시간여행자 블로그 : http://openuiz.blogspot.com/2018/11/fp-growth-algorithm-frequent-pattern.html
- 떡춘님 블로그 : https://blog.naver.com/sindong14/220661064114
Apriori와 FP-Growth. 추천 시스템 시리즈