
Multi Armed Bandit 알고리즘?
이 글의 주 소스 링크를 먼저 밝힙니다. 원작자에게 먼저 허락을 구하고 글을 작성했습니다.
https://www.kaggle.com/ruslankl/how-to-deal-with-multi-armed-bandit-problem
Multi Armed Bandit(MAB) 란?
마케팅이든 아니면 의학적인 실험에서든 사용자에게 어떤 게 가장 좋은 것 인지 확인하는 방법은 무엇일까요?
바로 Multi Armed Bandit Algorithm입니다. 특히 Thompson Sampling이라는 기법과 같이 사용된다면 굉장히 효과적으로 가장 좋은 선택이 무엇인지 알아낼 수 있습니다.(실제로 추천 알고리즘의 Cold Start 문제 등에 효과적으로 적용되고 있는 알고리즘 중 하나입니다.)
마케팅 캠페인을 한다고 합시다. 마케팅 캠페인에서는 보통 CTR(Click Through Rate)을 이용해서 광고가 효과적인지 판단하곤 합니다.(물론 마케팅 회사마다 케이스 바이 케이스이긴 합니다만, 일단 CTR이라고 가정하고 넘어가 봅시다)
- CTR 예시, 어떤 광고가 100번 노출되고 유저가 10번 클릭을 한다면, 이 광고의 CTR은 10/100으로 0.1입니다.
이야기가 나온김에 Regret도 같이 설명하자면, Regret은 가능한 CTR중 최고의 CTR과 지금 있는 CTR을 빼준 값입니다. 광고 A의 CTR이 0.1이고 B가 0.3이라고 할 때, A를 보여줬을 때 Regret은 $0.3 - 0.1 = 0.2$가 됩니다.
이제 광고에 대한 여러 안들이 있고, 어떤 광고가 가장 효과적인지 확인하려고 합니다. 하지만 광고에 대해서 어떤 사전 정보도 없다면 어떨까요?, 어떻게 여러 대안중에 효과적인 광고를 골라낼 수 있을까요? 이럴 때는 보통 사용하는 방법이 A/B test입니다. A/B 테스트는 말 그대로 A안과 B안을 노출시켜서(노출 비율은 정할 수 있다) 두 집단의 각각 다른 효과를 확인하기 위해서 사용되는 방법입니다. (wiki 설명 : A/B 테스트는 변수 A에 비해 대상이 변수 B에 대해 보이는 응답을 테스트하고, 두 변수 중 어떤 것이 더 효과적인지를 판단함으로써 단일 변수에 대한 두 가지 버전을 비교하는 방법이다, https://ko.wikipedia.org/wiki/A/B_%ED%85%8C%EC%8A%A4%ED%8A%B8)
‘아 그럼 A/B 테스트 하고 좋은 거 그냥 뽑으면 되겠네!’라고 생각할 수 있겠지만, 회사에서 이 테스팅을 진행한다고 생각해 봅시다. 주의할 점이 있습니다. A안을 기존에 하던 광고라고 하고 B를 실험하는 광고라고 해봅시다. A안 광고를 통해서는 꾸준히 매출을 기록하고 있고, B안은 아직 확실하지 않습니다. B가 아마 효과적이라고 하는데 아직 의심스럽습니다. 만약 테스팅을 하는데 B의 효과가 너무 떨어진다면 어떨까요?
- 기존 광고 효과의 목표치에 도달하지 못한다.
- 매출이 떨어진다.
- 고객이 실망하고 이탈한다.
이런 상황이 가능하지 않을까요? 그래서 MAB에서 중요한 것은, Exploration과 Exploitaion입니다. 한국어로 쉽게 말하면, 탐색하기와 뽑아먹기 입니다. 쉽게 탐색과 이용이라고 하겠습니다.
Exploration은 탐색하는 것입니다. 새로운 안에 대해서 계속 테스트하고 실험해 보는 것입니다.
Exploitation은 이용하는 것입니다. 즉, 기존에 효과적이었던 광고를 계속 하는 것입니다.
결국 A/B테스트이든, MAB이든 중요한 것은, 이 비율을 적절하게 맞춰서 탐색을 간결하게 하고 최대한 효과적으로 이용할 수 있는 대안을 선정하는 것입니다.
MAB, 즉 Multi Armed Bandit 알고리즘은 여러 대안들(슬롯머신의 Arm에서 이름을 따왔습니다)을 자동으로 실험하고 최적의 광고를 탐색과 이용사이에서 균형을 잡으면서 빠르게 찾는데 좋은 알고리즘입니다. Multi Armed Bandit 알고리즘들은 몇 가지 종류가 있습니다만 거의 모든 알고리즘은 위에서 소개한 Regret을 줄이는 것을 목표로 하고 있습니다.
주요 알고리즘들은 다음과 같습니다.
- Random Selection
- Epsilon Greedy
- Thompson Sampling
- Upper Confidence Bound (UCB1)
이 알고리즘들을 가지고 실험을 하기 전에 CTR을 사전에 설정해 둘 필요가 있습니다. 설정해둔 CTR로 광고가 주어졌을 때 클릭에 대한 시뮬레이션을 진행할 수 있습니다.
먼저 CTR을 비현실적이지만 0.45와 0.65로 설정하겠습니다.
1 | ACTUAL_CTR = [.45, .65] |
1. Random Selection
Random Selection은 말그대로 탐색을 하지 않고 동전 튕기기를 이용해서 앞면이면 광고0, 뒷면이면 광고1을 보여주는 알고리즘입니다. 정말 간단합니다!
1 | n=1000 |
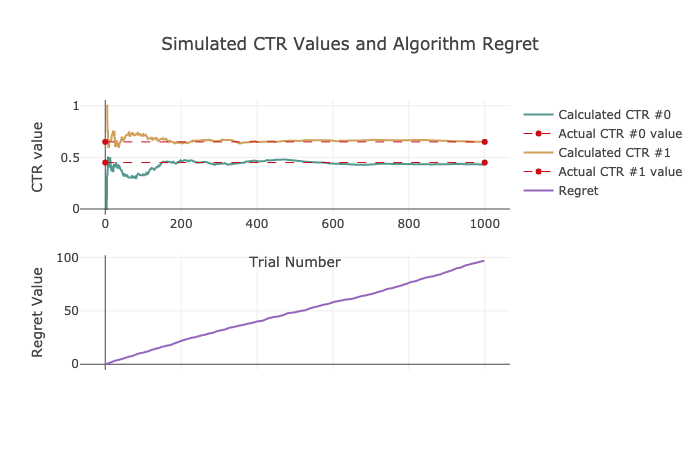
1 | Ad #0 has been shown 48.4 % of the time. |
CTR이야 0.65, 0.45를 잘 찾아간다지만, 중요한 것은 Regret입니다. Regret함수를 보면 함수값이 거의 100대에 육박하는 것을 볼 수 있습니다. 좀 더 좋은 알고리즘을 통해서 Regret을 낮출 필요가 있겠습니다. 마케팅 예산이 무한대라면 그냥 마구잡이로 보여주고 CTR을 측정해서, 높은 CTR을 보이는 광고안을 선정하면 그만입니다. 하지만 일개 사원인 우리들은 예산을 최대한 아껴서 좋은 효율적인 광고를 통해 매출을 극대화 해야하는 사람들입니다. 그렇다면 좀 더 좋은 알고리즘을 살펴보겠습니다.
2. Epsilon Greedy
Epsilon Greedy 알고리즘은 Random Selection에서 한 단계 업그레이드 된 모델입니다.
이 알고리즘은 탐색과 이용의 비율을 어느정도 조정한다는 것이 큰 특징입니다.
- ~15%까지는 Exploration
- ~85%까지 Exploitation
로직은 다음과 같습니다.
- 초기 몇번 까지는 Exploration(초기 값이 중요!)
- 각 Exploration마다 최고 점수를 받는 variant 고르기
- Epsilon 설정
- (1-E)%의 winning variant를 고르고 다른 옵션에는 E%를 설정한다.
1 | e = 0.05 |
1 | regret = 0 |
.png)
1 | Ad #0 has been shown 6.2 % of the time. |
Random Selection model보다는 훨씬 괜찮은 결과가 나왔습니다. 간단한데 결과는 훨씬 좋아지네요. 하지만 탐색시의 winning variant는 최적의 variant가 아닐 수 있습니다. 사실 suboptimal variant로 탐색 한 것입니다. 이것은 regret을 올리고 보상을 감소시킬 수 밖에 없습니다. 큰 수의 법칙에 따르면, 초기 시도를 많이 할수록, winning variant를 찾을 가능성이 커집니다. 하지만 마케팅에서는 큰 수의 법칙에 결코 따를 수가 없을 겁니다. 우리는 일개 사원…
이 알고리즘의 좋은 점은 어떤 비율을 설정할 수 있다는 것입니다. 각기 다른 epsilon값을 선택함으로써 얼마나 자주 winning ad를 보여줄 수 있는지 조정할 수 있는 것입니다.
좀 더 좋은 알고리즘을 살펴볼까요?
3. Thompson Samling
50% Exploration
50% Exploitation
Thompson Sampling의 탐색 부분은 Epsilon-greedy알고리즘보다 복잡합니다. 이 알고리즘은 단순히 epsilon을 정하는 것이 아니라, Beta distribution을 이용하기 때문입니다. 왜냐하면 광고를 클릭하는 것은 베르누의 과정에 속하기 때문입니다.(클릭했다, 안했다는 1,0으로 표현 가능합니다) 하지만 톰슨 샘플링은 일반적으로 어떤 분포, 어떤 파라미터에서든지 샘플링이 가능하다. 이게 가장 큰 장점 중 하나라고 생각합니다.참고로 Beta 분포는 alpha와 beta 파라미터로 분포의 모양을 조절한다.(prior 조정 가능)
로직은 다음과 같습니다.
- alpha와 beta를 고른다.
- $\alpha=prior+hits$, $\beta=prior+misses$로 계산한다. 우리의 경우는 hits는 클릭 수를 말하고, misses는 클릭없이 impression된 경우를 말합니다(클릭 없는 노출). prior는 CTR에 대한 prior정보가 있으면 유용합니다. 우리는 갖고 있지 않으므로 1.0을 사용할 것 입니다..
- CTR을 추정합니다. 실제 CTR을 베타 분포에서 샘플링하고 $B(\alpha_i,\beta_i)$에서, 추정 CTR이 가장 높은 것을 선택한다.
- 2-3을 반복한다.
1 | regret = 0 |
1 | x = np.arange (0, 1, 0.01) |
.png)
.png)
1 | Ad #0 has been shown 4.2 % of the time. |
지금까지 본 regret중 가장 낮은 regret을 확인할 수 있습니다.
이 알고리즘은 지속적으로 탐색합니다. 자연스럽게 Beta distribution을 이용해 가장 가치가 높은 샘플을 가져와서 이용할 수 있습니다. Beta distribution Ad#1은 더 높고 좁은 분포를 갖고 있습니다. 이것은 샘플된 값들이 항상 Ad#0보다 높을 것이라는 것을 의미합니다. 결국 Ad#1이 우리가 원하는 광고임을 빠르게 파악할 수 있습니다.
UCB (Upper Confidence Bound)
- 50% Exploration
- 50% Exploitation
Thompson Sampling과 달리 UCB는 불확실성에 더 초점을 맞춥니다. 한 variant에 대해 더 불확실 할 수록, 더 탐색을 해야만 하는 알고리즘입니다.
알고리즘은 가장 높은 UCB가 나오는 variant를 선택합니다. UCB를 통해 가장 높은 보상이 나올 것이라고 생각되는 variant를 고르는 것입니다.
$$UCB = \bar x_i + \sqrt{\frac{2 \cdot \log{t}}{n}}$$
이 수식을 따르며 뒤에 term에 따라 UCB의 파생 알고리즘들이 등장하게 됩니다.
$\bar x_i$ CTR이 i번째 단계일 때,
$t$ - 모든 variant에 대해 impression을 다 더한 숫자이다.
$n$ - 선택된 variant에 대해 impression을 다 더한 숫자이다.
로직은 직관적입니다.
- UCB를 모든 변량들에 대해 구합니다.
- 가장 높은 UCB를 가진 변량을 선택합니다.
- 1번으로 다시 돌아갑니다.
1 | regret = 0 |
.png)
1 | Ad #0 has been shown 19.2 % of the time. |
결과는 다음과 같습니다. Regret이 생각보다 높네요, UCB알고리즘도 현업에서 자주 사용하는 알고리즘입니다만, 이 알고리즘은 가장 기본적인 알고리즘이기 때문에 그런 것 같습니다.
결론 및 성능 비교
이제 살펴봤던 모든 알고리즘의 성능을 비교해 볼 시간입니다. 기대가 되네요, 나온 결과를 시각화를 해서 살펴 보겠습니다.
.png) 1000번의 시도에 어떤 광고를 얼마나 노출시켰는 지에 대한 막대그래프입니다.
Random Selection은 CTR이 낮은 광고를 너무 많이 노출 시켰네요, 그 다음은 UCB1, Epsilon Greedy, Thompson Sampling 순 입니다. Thompson Sampling이 가장 좋네요! 하지만 놀라운 것은 Epsilon Greedy입니다. 정말 간단한 알고리즘인데 성능이 좋군요.
1000번의 시도에 어떤 광고를 얼마나 노출시켰는 지에 대한 막대그래프입니다.
Random Selection은 CTR이 낮은 광고를 너무 많이 노출 시켰네요, 그 다음은 UCB1, Epsilon Greedy, Thompson Sampling 순 입니다. Thompson Sampling이 가장 좋네요! 하지만 놀라운 것은 Epsilon Greedy입니다. 정말 간단한 알고리즘인데 성능이 좋군요.
.png) 다음 자료는 Regret에 대한 것입니다. 시도가 늘어날 수록, Random Selection이나 UCB는 쭉 쭉 증가하는 것이 보입니다. 하지만 Thomspon Sampling은 굉장히 안정적으로 Regret이 유지되네요.
다음 자료는 Regret에 대한 것입니다. 시도가 늘어날 수록, Random Selection이나 UCB는 쭉 쭉 증가하는 것이 보입니다. 하지만 Thomspon Sampling은 굉장히 안정적으로 Regret이 유지되네요.
.png) 마지막은 1000번의 시도에서 총 몇번의 클릭을 받았는가에 대한 시각화 자료입니다. 클릭이 많다면 더 효과적으로 실험을 하면서 광고를 했다고 할 수 있겠네요. 역시 Thompson Sampling이 가장 많은 클릭 수를 얻었습니다. 그 다음은 Epsilon Greedy, UCB1, Random Selection 순 입니다.
마지막은 1000번의 시도에서 총 몇번의 클릭을 받았는가에 대한 시각화 자료입니다. 클릭이 많다면 더 효과적으로 실험을 하면서 광고를 했다고 할 수 있겠네요. 역시 Thompson Sampling이 가장 많은 클릭 수를 얻었습니다. 그 다음은 Epsilon Greedy, UCB1, Random Selection 순 입니다.
물론 Regret이 낮다고 가장 높은 보상이 있는 것은 아닙니다. 이 실험에서는 우연히 Thompson Sampling이 Regret도 낮고, 높은 보상을 얻었습니다. 알고리즘은 적절한 광고를(right ads) 보여줄 뿐 이고, 유저가 클릭하는 것은 보장하지 않습니다.
일반적으로 Thompson Sampling이 좋은 결과를 보여줍니다. 하지만 다른 알고리즘을 보면서 어떻게, 그리고 언제 그 알고리즘이 유용할지 생각해봐야 합니다. 어떤 문제를 풀 지는 각 개인 마다 다르기 때문에, 여러 알고리즘들 중에서 문제에 적합한 것을 선택할 수 있어야 합니다. 어떤 사전 정보를 갖고 있고, 알고리즘 적용 후에 어떤 정보를 알고싶은지를 명확하게 설정하는 것이 더 중요하다고 할 수 있겠습니다.
Multi Armed Bandit 알고리즘?