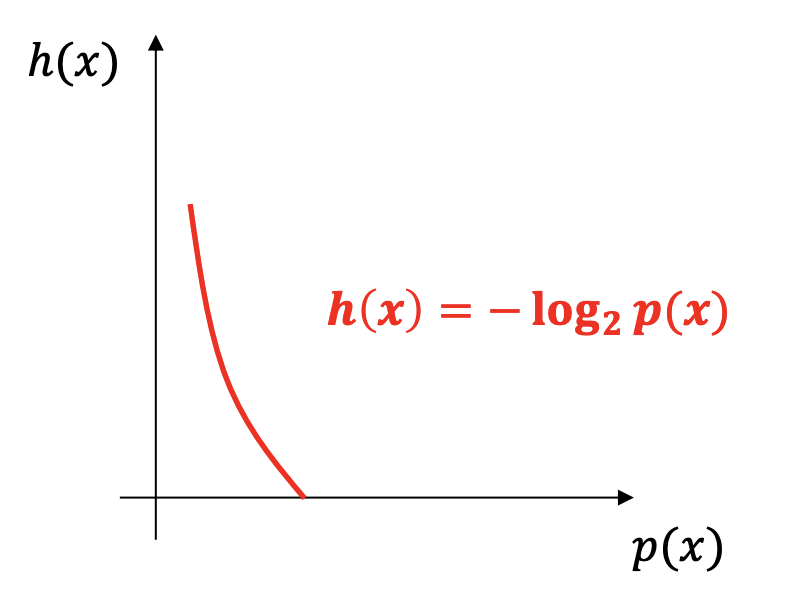Cross Entropy와 KL-Divergence에 대해서 알아보자
Cross Entropy
크로스 엔트로피에 대해서 알아보기 전에, 엔트로피 식을 다시한번 확인해 보자
엔트로피는 $H(x)=-\sum P(x)log_2P(x)$로 확률분포 $P(X)$에 대한 기댓값이다. 엔트로피는 확률분포가 있어야 정의가 될 수 있다. 확률 분포의 불확실한 정도를 뜻하는 것이라고 생각하면 된다.
이제 크로스 엔트로피 식을 확인해 보자
$H(P,Q)=-\sum_{X} P(x)logQ(x)$(자연로그 또는 이진로그)
식을 자세히 보면, $P(x)$가 들어갈 자리에 $Q(x)$가 들어가 있다. 어떤 의미가 숨어져 있는 것 같은데,
이 수식이 의미하는 것이 무엇일까?
크로스 엔트로피(Cross Entropy)는 실제 데이터는 $P$의 분포로부터 생성되지만, 분포 $Q$를 사용해서 정보량을 측정해서 나타낸 평균적 bit수를 의미한다. 이제 수식이 눈에 들어오기 시작할 것이다.
실제 데이터는 분포 P로 부터 생성되는데, 우리가 실제 P에 대해서 몰라서 분포 Q의 정보(or 코딩 스킴)을 대신 활용하면 어떨까?에 대한 답으로써 만들어졌다고 생각하면 편할 것이다.
크로스 엔트로피는 $H(P,Q)$와 같이 나타내고 일반적으로 $H(P,Q) >=H(P)$이다. 항상 크로스 엔트로피가 크거나 같을 수 밖에 없는 것은 데이터의분포를 Q로 가정한 코딩방식을 사용하게 되면, 실제의 분포 P를 가정한 코딩방식 보다 질의응답에 필요한 코드의 수(code length)가 많아지게 되기 때문이다.
KL-Divergence
KL-Divergence는 쿨백 라이블러 발산이라고 불리기도 한다. 이 역시 수식으로 먼저 확인해 보자
$D_{KL}(P||Q)=\sum_{X}P(x)log {P(x)\over{Q(x)}}$이다. 이 수식을 자세히 보면, Cross entropy 식이 들어가 있는 것을 확인 할 수 있다. 좀 더 풀어서 써보면
$D_{KL}(P||Q)=\sum_{X}P(x)log{1\over Q(x)}-P(x)log{1\over P(x)}$로
결국 $H(P,Q) - H(P)$, 즉 P와 Q의 크로스엔트로피에서 P의 엔트로피를 빼준 식이다. 이것은 결론적으로 Q를 이용한 정보량이 P의 분포와 얼마나 차이가 나는 지를 알려주는 것이다. 일종의 분포사이의 거리로 이해를 하면 된다. (KL divergence는 두 확률 분포 P와 Q의 차이를 측정한다. 하지만 엄밀히 말해서 거리는 아니다.)
다른 표현으로 데이터 인코딩 관점에서 보면 KL divergence는 데이터 소스의 분포인 P 대신 다른 분포 Q를 사용해서 인코딩하면 추가로 몇 bit의 낭비가 생기는지 나타낸다고 이해할 수 있다.
KL-Divergence는 거리함수가 아니다. 왜냐하면 교환법칙이 성립하지 않기 때문이다. Reverse KL은 별도의 개념으로 사용된다. 하지만, 두 분포가 다를수록 큰 값을 가지며 둘이 일치할 때에만 0이 되기 때문에 거리와 비슷한 용도로 사용할 수 있다.
[https://wiseodd.github.io/techblog/2016/12/21/forward-reverse-kl/]
Cross Entropy와 KL-Divergence가 어떤 관계에 있느냐고 묻는다면, KL-Divergence의 앞쪽 수식에 크로스 엔트로피가 있으므로, 크로스 엔트로피가 작을 수록, KL-Divergence값이 작아진다. 즉, 두 분포가 가까워진다고 말할 수 있겠다.