Time Series Analysis Begins
시계열 데이터 분석의 시작
Dive into 시계열 데이터 분석
시계열 데이터 분석에 대해서 공부해보자!
저번 주부터 고대하던 시계열 분석에 대해서 본격적으로 공부해보게 되었습니다. 공부한 내용에 대해서 차근차근 정리를 해보는 시간을 갖겠습니다.
분석적 사고의 필요성
시계열 분석에 앞서 강조하는 부분이 있었습니다. 데이터 분석에는 6가지 사이클이 있습니다.
- 문제정의
- 데이터 수집
- 데이터 전처리
- 데이터 정리
- 데이터 분석
- 결과 정리
그 중 가장 중요한 것은, 데이터 분석이 아니라 분석적 사고의 필요성입니다. 특히 데이터 사이언티스트에게 중요한 덕목으로서 강사님께서 강조해 주셨는데요, 결국은 문제 정의를 잘하는 것이 중요하다는 것이었습니다. 문제가 잘 정의되면 데이터를 어디서 갖고 올지 어떤 알고리즘을 사용할지 등이 정리가 될 수 있습니다. 사실 캐글 = 데이터사이언스로 보는 사람들이 많은데, 엄밀히 따지면 캐글은 알고리즘을 공부할 수 있는 대회일 수 있습니다. 이미 사전에 문제정의가 끝나고 데이터를 잘 모으고 정리되어서 캐글쪽에 전달되기 때문에 정말 필요한 능력인 문제정의 능력을 키우기는 힘들 수 있습니다.(개인적으로 가장 신선한 충격을 받았던 설명이었습니다)
문제 정의 후에는 이것을 고객들이나 관리자에게 잘 전달해주어야 합니다. 그래서 중요한 것은 설득 및 설명 능력입니다. 사실, 데이터분석 관련지식(이론), 프로그래밍 활용능력(실습) 등은 금방 늘어날 수 있는 능력이지만, 잘 설득하고 이해하기 쉽도록 설명하는 능력은 정말 키우기 어렵습니다. 어쩌면 데이터 사이언티스트에게 커뮤니케이션 능력은 잘 키울 수 없기에 더 중요하지 않을까 생각되기도 합니다.
정확한 문제 정의의 중요성
앞서 말씀 드린 것처럼, 정확하게 문제를 정의하고 분석을 시작해야 합니다. 이를 위해서는 가설을 설정하고 검정하는 것이 필요하게 됩니다. 가설 설정의 세가지 조건은 다음과 같습니다.
가설 설정 세가지 조건
- 상호배반적
- 증명가능성
- 구체성
상호배반성은 나의 주장과 대립 주장이 모호함이 없어야 한다는 것으로, 서로 겹치는 영역이 없어야 된다는 것을 말합니다. 증명가능성은 성급화 일반화에 빠지지 않기 위해서는 증명 가능한 것이나, 범위로 내세워야 한다는 것을 말합니다. 마지막으로 구체성은 충분히 구별되고 실현가능한 표현으로 정의되어야 한다는 것입니다.
검정
가설을 세웠으면, 이제 그 가설이 맞는지 검정을 해야 합니다. 주의해야할 점은 모집단에 대한 것입니다. 모집단은 논란이 있을 수 있지만, 관찰이 불가능한 것입니다. 이상적인 샘플 집단이기 때문입니다. 그렇기 때문에 우리는 항상 샘플을 갖고 분석을 할 수 밖에 없습니다. 샘플에 Bias가 있다면, Bias를 제거하고 사용합니다.
귀무가설과 대립가설은 통계에서 정말 자주 등장하는 개념입니다. 하지만 익숙하지 않은 단어들이기 때문에 항상 헷갈리는에요, 귀무가설은 기존의 주장(대립 주장), 대립가설은 내 주장 이라고 생각하면 사고하기 편리합니다.
귀무가설과 대립가설을 세웠다면, 이제 통계량을 보고 어떤 가설이 맞는지 확인해야 합니다. 이때 우리가 확인하는 통계량을 검정 통계량이라고 합니다. 대립가설과 귀무가설을 비교하기 위한 검증지표값으로 흔히 ‘점추정’이라고 부릅니다.
검정통계량이 발생가능한 구간에 대해서도 용어가 정리되어 있는데, 이것을 신뢰 구간이라고 부릅니다. 또 귀무가설이 참일 때 검정통계량으로 대립가설이 발생활 확률을 말하는 p-value가 있습니다. 일반적으로 p-value 기준으로 0.05보다 크면 대립가설을 기각하고, 0.05보다 작으면 대립가설을 채택합니다.
통계량
분석 단계별 의사결정을 위해서는 수학/통계적 언어를 이해하는 것이 필요합니다. 변동/산포 특성, 지표의 변동성을 나타내는 통계량에는 분산과 표준편차가 있습니다. 분산은 편차제곱의 합을 데이터의 수로 나눈 값이고, 표준편차는 분산에 루트를 씌운 값입니다. (참고로 편차는 관측값과 평균의 차이입니다)
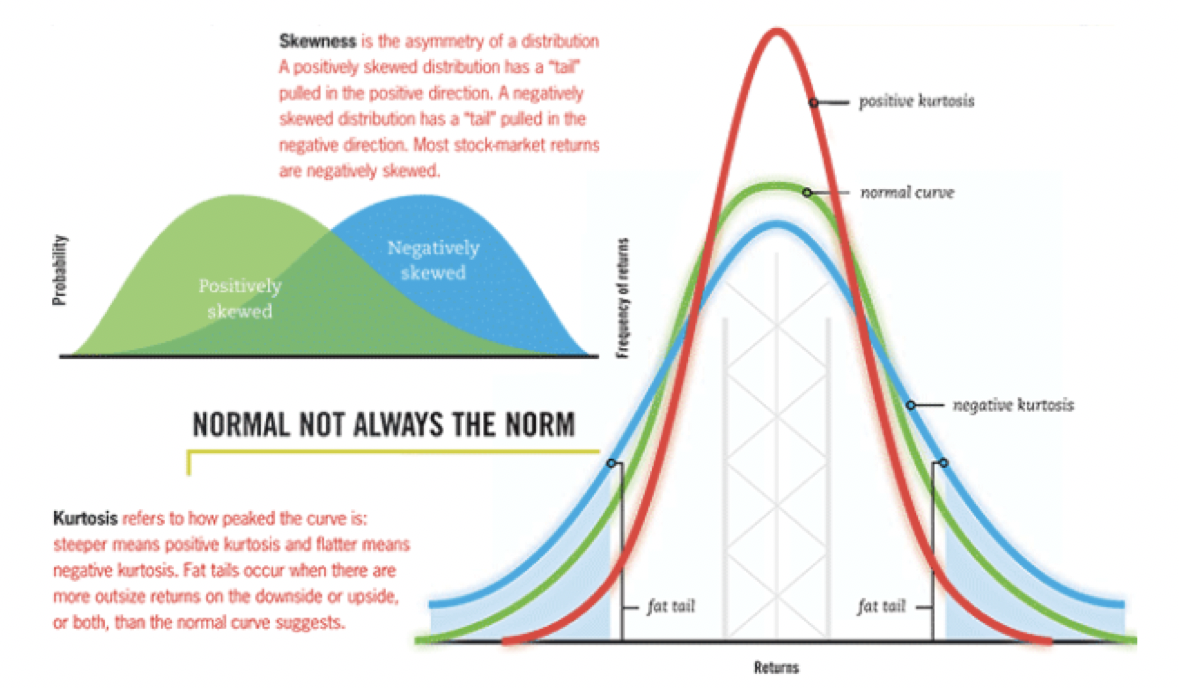
분포의 형태 특성을 나타내는 것으로는 대표적으로 Skewness와 Kurtosis가 있습니다. 왜도와 첨도라고 부를 수 있습니다. 왜도는 평균을 중심으로 데이터가 좌우로 편향되어 있는 정도를 말하고, 첨도는 뾰족한 정도로, 사실 더 중요한 것은 tail의 fat함을 보는 데 사용될 수 있습니다. fat-tail하다면 정규성 가정이 깨지게 되므로(정규성 가정 중 하나 : 분포의 tail은 슬림하다, kurtosis값은 0에 가까울 수록 좋다) 만든 모델이 제대로 작동하지 않을 가능성이 높습니다.
시계열 데이터와 횡단면 데이터
이제 데이터에 대한 얘기를 시작하겠습니다. 횡단면 자료(Cross-Sectional data)는 일정시점에서 하나 이상의 변수에 대해 수집된 자료를 말합니다. (예: 2016년 전국 16개 시도의 GRDP와 최종소비)
시계열 데이터는 일별, 주별, 월별, 분기별, 연도별 등 시간에 걸쳐 수집한 자료로 거시경제변수를 측정한 자료에서 많이 발생하는 데이터 입니다. 시계열 데이터는 보통의 데이터에 비해서 레코드(또는 로우)에 타임스탬프 또는 각 시간구간에 따른 집계 레벨(분별, 시간대별, 일별, 주별, 월별, 분기별, 년도별)에 대한 순서가 있는 시간값을 함께 가지고 있습니다. 시계열 데이터는 횡단면 데이터에 비해 고려해야 할 시간축이 하나 더 있는 것이 문제이며 시간축이 선후관계를 가지는 것, 그리고 시간축에 대한 것을 드릴다운하거나 다시 롤업(roll-up)해서 집계 응집도를 높여야 할 수 있습니다.
http://intothedata.com/02.scholar_category/timeseries_analysis/
시계열 데이터 분석을 위한 준비는 이것으로 어느정도 마무리 된 것 같습니다. 이외에도 Anaconda 설정이나, Numpy, Pandas를 다루는 부분이 있지만 블로그 글에서는 생략하겠습니다.
다음 포스팅 부터는 본격적인 시계열 데이터의 계절성이나 주기의 차이점, Residual을 주의깊게 관찰해야 하는 이유 등에 대해서 다뤄보겠습니다.
Time Series Analysis Begins