시계열 분석 시리즈 두 번째
시계열 데이터 분석의 특성들
Dive into 시계열 데이터 분석
시계열 데이터 분석에 대해서 공부해보자 02
시계열 데이터도 그렇고 데이터 분석 자체도 그렇습니다만, 내가 어떤 문제를 풀어야 하는지 알게 되면, 문제에 대한 기획/접근/해결 방향은 단순해집니다.
문제가 무엇일까?
내가 사용가능한 알고리즘은?
알고리즘의 입력과 형식은?
알고리즘의 출력은?
보통 이런 4단계를 거치게 되겠습니다. 항상 알고리즘을 사용하기 전에 위의 4가지 물음에 대해서 고민해 보는 게 좋을 것 같습니다. 학습하는 방향에 따라서 알고리즘은 달라집니다. 대표적인 알고리즘 유형은 다음과 같습니다.
Supervised Learning
- Regression
- Instance Based
- Regularization
- Tree
- Bayesian
- ANN
Unsupervised Learning
- Clustering
- Association Rule
- Dimensionality Reduction
- Ensemble
- Deep Learning
머신러닝에 대해서는 어느정도 알고 있습니다. 그렇다면 머신러닝과 시계열 분석의 차이는 무엇일까요? 큰 차이점은 바로 시간축을 고려하는가? 아닌가?에 관한 것입니다. 시계열 분석은 시간축에 대해서 고려를 해야하고, 학습데이터와 테스트 데이터를 나눌때도 시간축을 신경 써서 나누어야 합니다.
시계열 데이터의 독자적인 성분들 7종
시계열 데이터를 다루다 보면 시계열 데이터만의 독특한 성분들이 발견됩니다. 대표적인 7종을 알아보겠습니다.
빈도
빈도는 말 그대로 frequency를 나타내는 말입니다. 하지만 조금 다른게 있다면, 계절성 패턴이 나타나기 전까지의 데이터 갯수로 사람이 정해야 한다는 점입니다. 일 단위, 월 단위, 연 단위로 나누어서 빈도를 측정합니다. 나누는 기준은 따로 없지만, 비즈니스 사이클이 복잡할수록 작은 시간축, 단순하다면 크게 월로 해도 어느정도 맞아들어갑니다. 혹시 작업을 하다가 시간축이 안맞아 Null이 발생할 수 있는데, 파이썬의 여러 메서드를 사용한다면 금방 채울 수 있습니다.bfill(Backward fill)이나ffill(Forward fill)등을 이용하면 됩니다.추세
추세는 트렌드를 말합니다. 시계열이 시간에 따라 증가, 감소 또는 일정 수준을 유지하는 경우를 말하며, 아마존의 주식 챠트를 보면 우상향하는 그래프를 볼 수 있는데, 그런 경향을 바로 트렌드라고 합니다. 확률과정(Yt)이 추정이 가능한 결정론적 추세함수 f(t)와 정상확률과정(Yt)의 합으로 나타내어집니다.
$$Y_t = f(t) + Y_t(Seasonal)$$
추세를 제거하게 되면 추세를 제외한 함수로 예측하는 것이 일반적이고 상한, 하한을 만들어 놓습니다. X에 대해서는 일/월/년 인지 모르기 때문에 frequency 세팅을 꼭 해주어야 합니다.
계절성
계절성은 일정한 빈도로 주기적으로 반복되는 패턴(m), 특정한 달/요일에 따라 기대값이 달라지는 것을 말합니다. 주기적 패턴이 12개월마다 반복된다면 m=12로 설정합니다. $Sin$함수나 $Cos$함수를 그려보면 이해가 빠를 것 같습니다.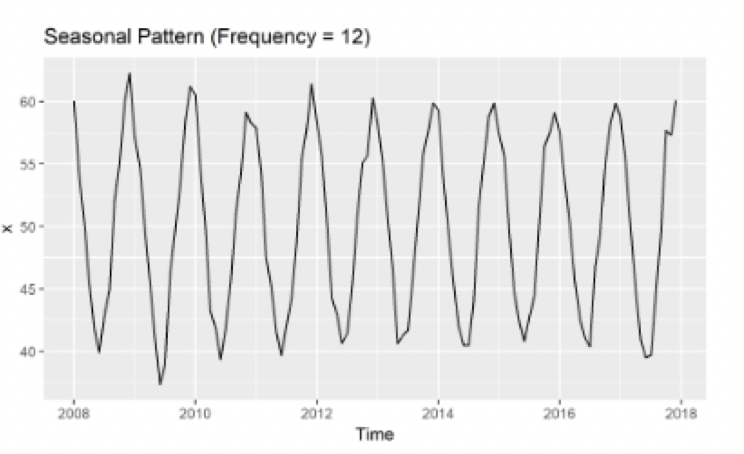
주기
주기는 계절성과 많이 헷갈릴 수 있습니다. 주기는 일정하지 않은 빈도로 발생하는 패턴을 말합니다. 계절성과는 일정한 빈도라는 부분에서 차이가 납니다. 빈도가 1일 때도 발생가능하며, 쉽게말해 Variance가 비슷하면 계절성이고, 다르면 주기(Cycle)이라고 볼 수 있습니다.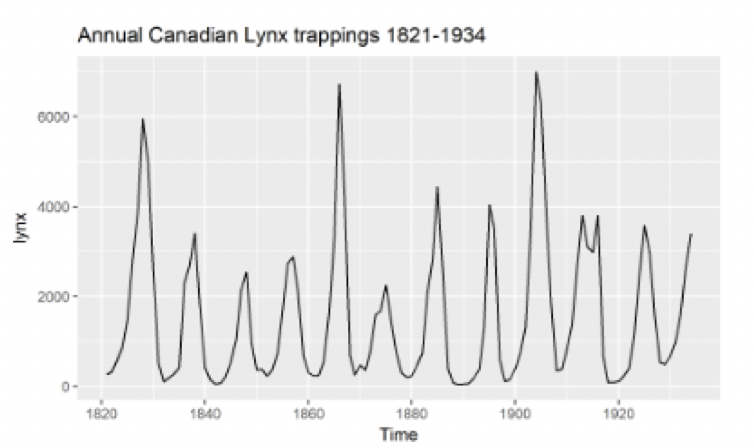
더미변수
더미변수는 이진수의 형태로 변수를 생성하는 것으로 휴일, 이벤트, 캠페인, Outlier 등을 생성할 수 있습니다. 범주형 변수의 기준값을 미리 결정해야 하며, 기준 값을 제외한 채 더미변수를 생성합니다.(N개의 변수라면 하나는 빼주어야 합니다.) 각 더미변수의 값을 0 또는 1로 채우며 1은 각 더미변수의 정의와 같음을 의미합니다. 물론 더미변수는 N-1개를 만들어야 하지만, 더미변수는 해석에 자신이 있을때의 경우이고 자신이 없다면 N개 만들어도 됩니다.지연값(Lag)
Lag는 변수의 지연된 값을 독립변수로 반영합니다. 과거의 X를 현재에 반영하고 싶을 때 사용하고 python의 shift를 이용해서 간단하게 Lag를 만들 수 있습니다. shift(1) 바로 이전의 것, shift(2) 두 단계 전의 값. ARIMA, VAR, NNAR 등이 활용합니다.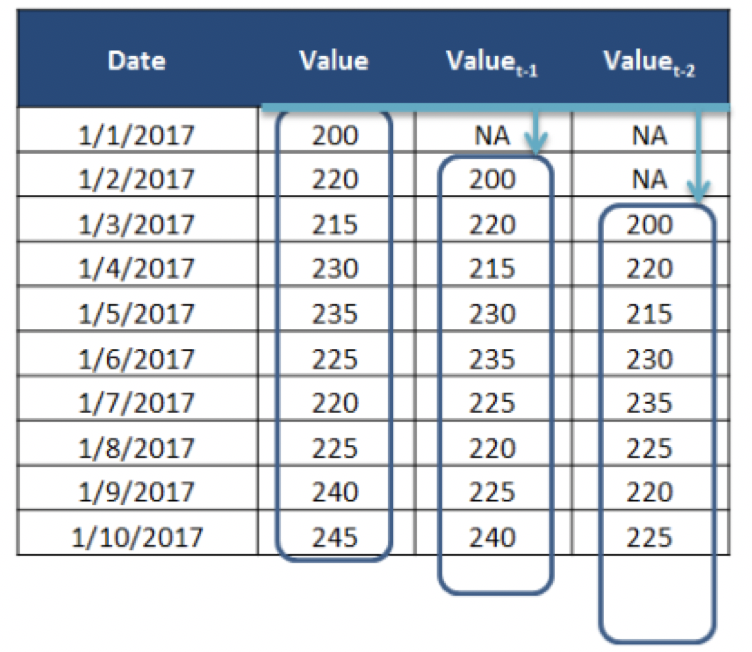
시간변수
시간 변수를 미시/거시적으로 분리하거나 통합하여 생성된 변수를 말합니다.
시계열 구성요소는 각 변수의 시간패턴을 알아내는 데 중요합니다. Feature Engineering을 통해 생성된 변수의 input형태로 모델 선택을 하는 데 필요합니다. 생성된 변수의 패턴이 이전 모델에서 발견되지 않은 패턴이라면 모델의 성능을 높일 수 있습니다. 또한, 예측 성능 뿐 아니라, 결과를 해석하고 해당 속성을 분석하며 가능한 원인 식별에 도움이 됩니다.
기본적으로 시계열 데이터 분석은 Numpy와 Pandas를 가지고 분석을 하게 됩니다. statsmodels라는 패키지의(sm)sm.tsa.seasonal_decompose를 통해 분석을 하게 됩니다. 여기서 parameter를 살펴보면, additive와 multiplicative모델을 고르는 부분이 있습니다. 뭘 선택해야 할지 고민을 할 수 있습니다. 일반적으로 additive모델을 주로 사용합니다. multiplicative모델은 언제 사용하느냐 하면, y가 %, 즉 비율로 표현되어 있을 때 사용하면 됩니다.sm.tsa.seasonal_decompose를 통해서 개략적으로 파악하고, 잔차까지 확인합니다.
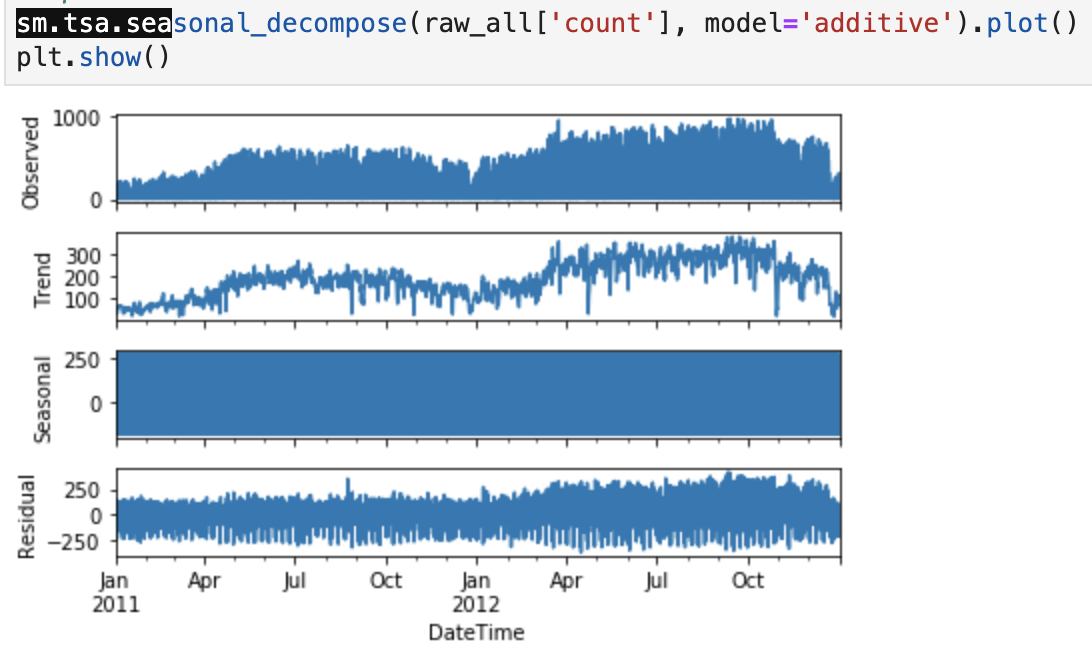
Residual을 확인하면서 추출해 나가야합니다. Residual을 봤는데, Y = T + S + Residual이므로
Residual은 Y-T-S가 됩니다.
이런식으로 잔차를 확인하고, 잔차에 트렌드가 있으면 트렌드를 잘못 추출한 것이고 잔차에 계절성이 있으면 계절성을 잘못 추출한 것이라고 판단하면서 분석의 방향을 잡아나아가면 됩니다.
시계열 분석 시리즈 두 번째