Time Seires, 시계열 분석 세번째
시계열 데이터 분석과 기계학습의 차이점, 회귀분석과의 차이점
Dive into 시계열 데이터 분석
시계열 데이터 분석에 대해서 공부해보자 03
시계열 데이터 분석과 기계학습의 차이점에 대해서 본격적으로 들어가보도록 하겠습니다. 시계열 알고리즘에는 기계학습과는 다른, 2가지 차별화 방향이 있습니다.
첫번째는 ‘과거데이터로 미래 데이터 뽑아낼 수 있는가’ 로 시간 축 기반의 예측이 가능하다는 것이고, 두번째는 시계열 알고리즘은 점추정이 아닌 구간추정 알고리즘으로 설명력 효과에 뿌리를 두었다는 것입니다. 대부분의 기계학습 모델은 통계분포에 기반하지 않끼 때문에 점추정 알고리즘이고, 시계열 알고리즘은 구간추정을 하기 때문에 점추정 보다 더 다양한 해석이 가능합니다.
(특별한 모델들)
- Dynamic Modeling : y가 여러개인 모델입니다. y에 대한 영향을 비교하고 싶다면 y를 두 개로 둬서 모델을 두개 만들고 실험하는 것을 생각해 볼 수 있습니다.
- XAI, LIME : 최근에 등장한 개념으로, 설명가능한 Aritificial Intelligence, 설명가능한 딥러닝에 대한 것입니다. Random Forest의 feature importance와 비슷하게 측정이 가능하다고 합니다.
시계열 데이터 분석 준비
데이터 분석 준비는 기존 머신러닝 데이터를 준비하는 것과 비슷하지만, 시계열 데이터만의 특징이 있기 때문에, 머신러닝 데이터 준비와 다른 몇 가지 특징들이 존재합니다.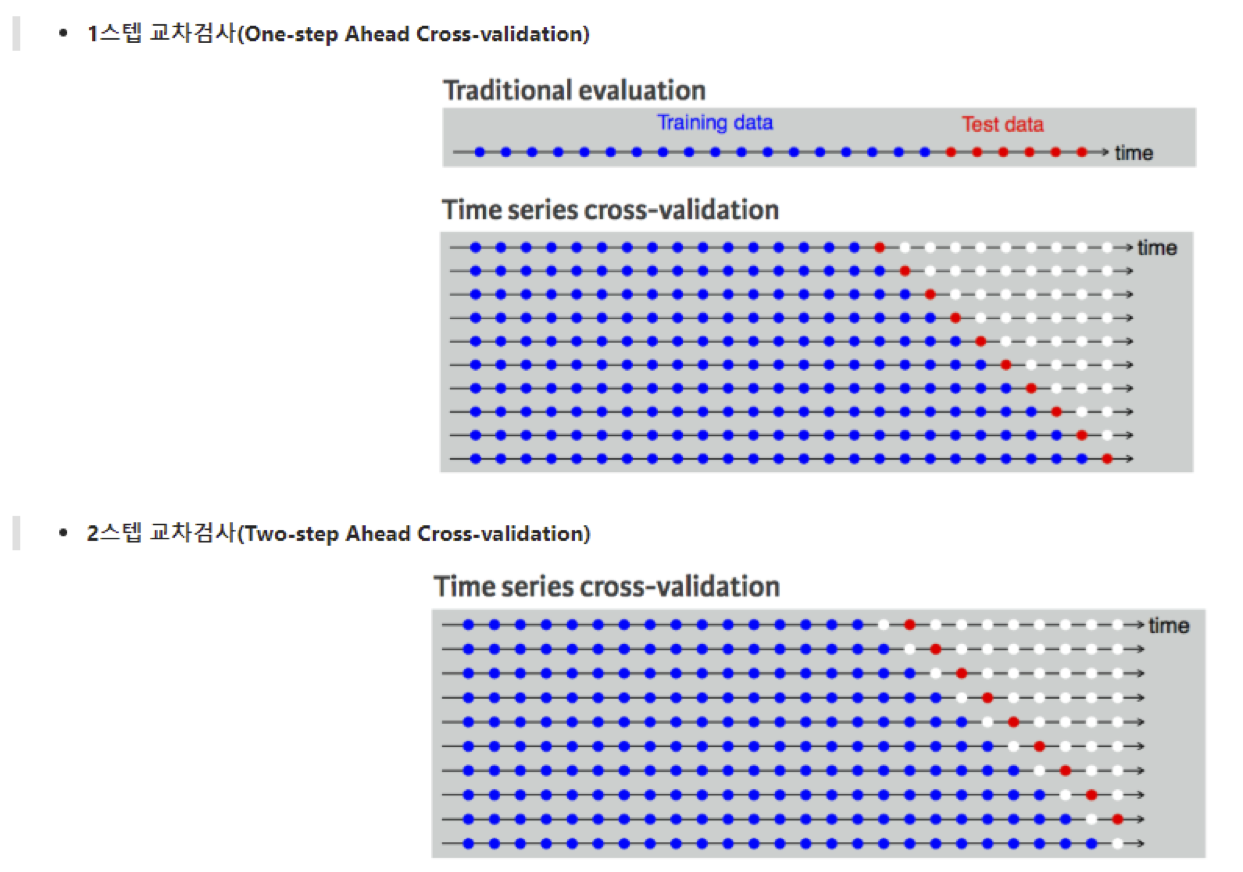
- 가장 옛날 것을 훈련데이터로 사용하고, 그 다음 것을 Validation 데이터, 가장 최근 것을 test데이터로 사용합니다.
- 기간을 두고 훈련셋을 만듭니다. 시간축을 잘 보존해야합니다.
- 훈련세트에서 하나 건너서 Validation set을 만들면 ⇒ 1스텝 교차검사
- 훈련세트에서 두 개 건너서 Validation set을 만들면 ⇒ 2스텝 교차검사
- 모델이 월 마다의 예측력이 다를 수 있기 때문에, 월별 모델을 만들기도 한다. (실제로 이렇게 모델을 만드는 경우가 많음)
검증지표와 잔차진단
분석하고 예측만 잘하면 될까요? 큰 착각일 수 있습니다. 중요한 것은 예측이 잘 되었는지 평가하는 것 그리고 데이터의 시간패턴이 잘 추출되었는지 확인하는 작업입니다.
검증지표는 예측값과 실제값이 얼마나 유사한지 측정하는 것이고, 잔차진단은 데이터의 시간패턴을 잘 뽑아내었는지 알아보는 작업입니다.
검증지표 에는 흔히 사용되고 눈에도 익숙한 MSE가 대표적입니다. 그 외에 MAE, MAPE, MAPE, MPE(y가 %로 나올 때) 등 다양한 검증지표가 사용되며, 왠만하면 다 사용해보고 수치가 안정될 때까지 모델을 만드는 것이 좋습니다. 또한 기존의 검증지표가 맘에 들지 않는다면, 분석가나 데이터 사이언티스트가 직접 고안해서 검증지표를 사용해도 됩니다.
훌륭한 데이터 사이언티스트라면 검증지표를 직접 만들어서 사용해야하는 경우가 많을 것입니다. 왜냐하면 검증지표만 가지고 사용하면 결과에 대한 해석을 다르게 할 수 있기 때문입니다. 예를들어 MSE의 경우는 오차에 대한 가중치를 확 올려버리는 검증지표입니다. 오차에 대해서 제곱을 하기 때문에 가중치가 급격하게 증가하게 됩니다. 분석가가 보기에 이 가중치가 너무 과하다고 생각되면 절대값을 사용할 수 있습니다. 이렇게 되면 MAE를 사용하는 것이 되겠습니다.
$$MSE = {1\over n}\sum(y-\hat{y})^2$$
$$MAE = {1\over n}\sum|y - \hat{y}|$$
잔차진단 는 말 그대로 잔차, $$y-f(x)$$ 에 대한 값을 보고 진단하는 것을 말합니다. 회귀분석을 해보신 분들을 아시겠지만, 잔차는 정의가 존재합니다.
잔차의 정의
- 잔차들은 정규분포이고, 평균 0과 일정한 분산을 가져야 한다.
- 잔차들이 시간의 흐름에 따라 상관성이 없어야 한다.
- 자기상관 함수를 통해 Autocorrelation이 0인지 확인
- 공분산
- 자기상관함수
- 편자기상관함수
자기상관 정도를 확인하기 위해서는 일반적으로 랜덤으로 epsilon을 두 개 뽑아서 자기상관성이 있는지 확인합니다. 자기상관성 뿐 아니라, 잔차가 잘 뽑혔는지 확인하기 위해서는 시각화를 통해서 확인하고, 자기상관성이나 평균, 분산과 같이 통계량을 계산해서 확인하는, 두 가지 방법을 모두 사용해야 합니다.
잔차를 보고 더 뽑아내야 할 것이 있는지, 분석이 잘되고 있는지 안되고 있는지를 확인해 나가야 합니다.
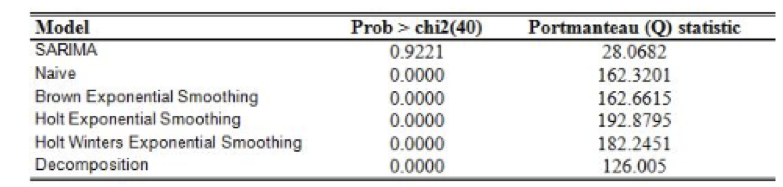
예를 하나 들어서 보겠습니다. 여기에 다양한 모델들이 있네요. Autocorrelation에 대해서 가정을 설정했고, 가정에 대한 결과표가 나왔습니다. 대중 주장은 모델의 잔차가 White Noise라는 것이고, 내 주장은 모델의 잔차가 White Noise가 아니라는 것입니다. 모델을 쭉 보니, SARIMA 모델은 p-value값이 굉장히 높고 나머지는 0에 가깝습니다. 이것을 어떻게 해석하면 될까요? p-value가 크다는 것은 대중 주장이 맞다는 것입니다. 대중 주장이 맞으니까 SARIMA의 잔차는 White Noise이고 모델이 잘 만들어졌다고 추측해 볼 수 있습니다. 나머지 모델들은 영 꽝이네요. 이런 식으로 모델에 대한 잔차를 검증해 나가면 됩니다.
시간영역 선택하기
시계열 분석이 머신러닝 분석 방법과 다른 것은 시간 축입니다. 이 시간 축을 어떻게 두느냐에 따라 분석 결과가 급격하게 달라집니다. 따라서 시계열이 분석효과에 도움이 될 시간영역(해상도)를 선택해야 합니다. 일종의 window size를 정한다고 생각하면 이해가 잘 되실 겁니다. 시간축을 년 단위로 할지, 월로 할지, 일주일로 할지는 사실 다 해보는 수 밖에 없습니다. 알 수가 없기 때문입니다. 그래서 다 해보고 잘되는 시간 영역을 선택해야 합니다. 물론 선택하는 기준은 있습니다. 바로 통계량과 잔차를 기준으로 잘 나오는 시간축을 선택하는 것입니다. 분석은 항상 이 방법으로 진행이 됩니다. 통계량과 잔차!
회귀분석 요약 / 시계열 분석 요약
계수 추정 방법은 두 가지 방법이 있습니다. 수학자(수식)방법과 통계학자(확률)의 방법입니다. 수학자의 방식은 결정론적 모형입니다. 잔차벡터를 구하고, 잔차 제곱합을 구한 후, 그레디언트를 계산합니다. 그 이후에 미분을 하여 최적점을 구하고 추정된 계수를 얻는 방법입니다. 이 때, $X^T X$ 행렬은 역행렬이 존재해야 합니다. $X$ 가 full rank가 아니면 계산이 되지 않겠습니다. 결국 $X^TX$ 행렬은 Positive Definite이 아니면 계산 되지 않습니다.
확률론적 모형은 다음과 같습니다. Main Equation에서 $X$ 가 있을 때의 $Y$ 의 기대값과 분산을 구합니다. 이를 통해 분포를 추정할 수 있게됩니다. 구한 평균과 분산을 가지고, $Y$ 값 각각의 확률을 구합니다. 그 이후에는 $Y$ 의 발생가능성에 대해서 Likelihood를 구합니다. Maximum Likelihood Estimation을 하려는 것입니다.
Log를 취해 계산을 편리하도록 만들어주고 미분으로 0값이 되는 지점을 구합니다. 통계학자의 방식은 이렇게 분포에 대한 계산을 해놓는 다는 점입니다. 이런 식으로 계산이 되면 구간추정도 가능해지게 됩니다. $beta$ (coefficient)값에 대한 분산은 $Covariance$ 를 통해서 구합니다.
역행렬이 없을 수록 에러값이 증가하게 되고 이것은 구간이 넓어지는 것을 의미하게 됩니다. 결국 넓어진 구간을 좁히는 것이 목표가 되겠습니다. beta값의 분포에 대해서는 $t$ 분포 따르는 게 증명이 되었기 때문에 $t$를 사용하면 됩니다. $beta$ 가 $t$ 에서 나온다는 성질은 가설검정을 할 때 이용됩니다. 추가로 딥러닝에 대해서 덧붙이자면, Neural Network는 신뢰구간의 범위가 너무 넓습니다. 이론적 근거가 없기 때문입니다. 검증을 할 때는 P-value를 보고 값이 높은 것은 coefficient가 몇이든 다 0으로 보면 됩니다. $R^2$ 값이랑은 별개의 문제입니다.
시계열 데이터 분석은 분석하고 검증하고 모델링하는 것도 중요하지만, 데이터에 따라 높은 정확도나 높은 에러를 가지게 됩니다. 시계열 분석은 단기적인 상황에서는 성능이 좋지만 중 장기 예측에 대해서는 잘 맞지 않는 다는 단점이 존재합니다. 물론 변화가 별로 없고 일반적인 패턴을 지닌다면 잘 맞추겠지만 변화가 굉장히 극심하다면 잘 맞추기 못 하게 됩니다. 애초에 데이터를 정렬할때도 시간축을 잘 살려서 정제를 해야하니 데이터 정렬 자체, 데이터 준비하기도 굉장히 어려운 작업이라고 할 수 있겠습니다.
Time Seires, 시계열 분석 세번째