2019 GDG DEVFEST SEOUL 행사를 다녀오다
GDG Devfest 행사를 다녀왔다
2019 GDG DEVFEST SEOUL
2019 GDG DEVFEST SEOUL 행사가 세종대학교 광개토관 지하 2층 컨벤션홀에서 열렸습니다. 2주 전에 행사 소식을 접했는데 타임 테이블을 보니 ML/AI관련 세션이 많이 준비되어 있고 관심있는 내용이 있어서 바로 티켓을 구매했습니다. 특히 캐글 코리아에서 활동하시는 이유한 님의 BERT in Kaggle, 분자대회에서 BERT를 이용해서 어떻게 금메달을 획득했는지가 궁금해서 질러버렸습니다.(캐글 코리아 짱짱)
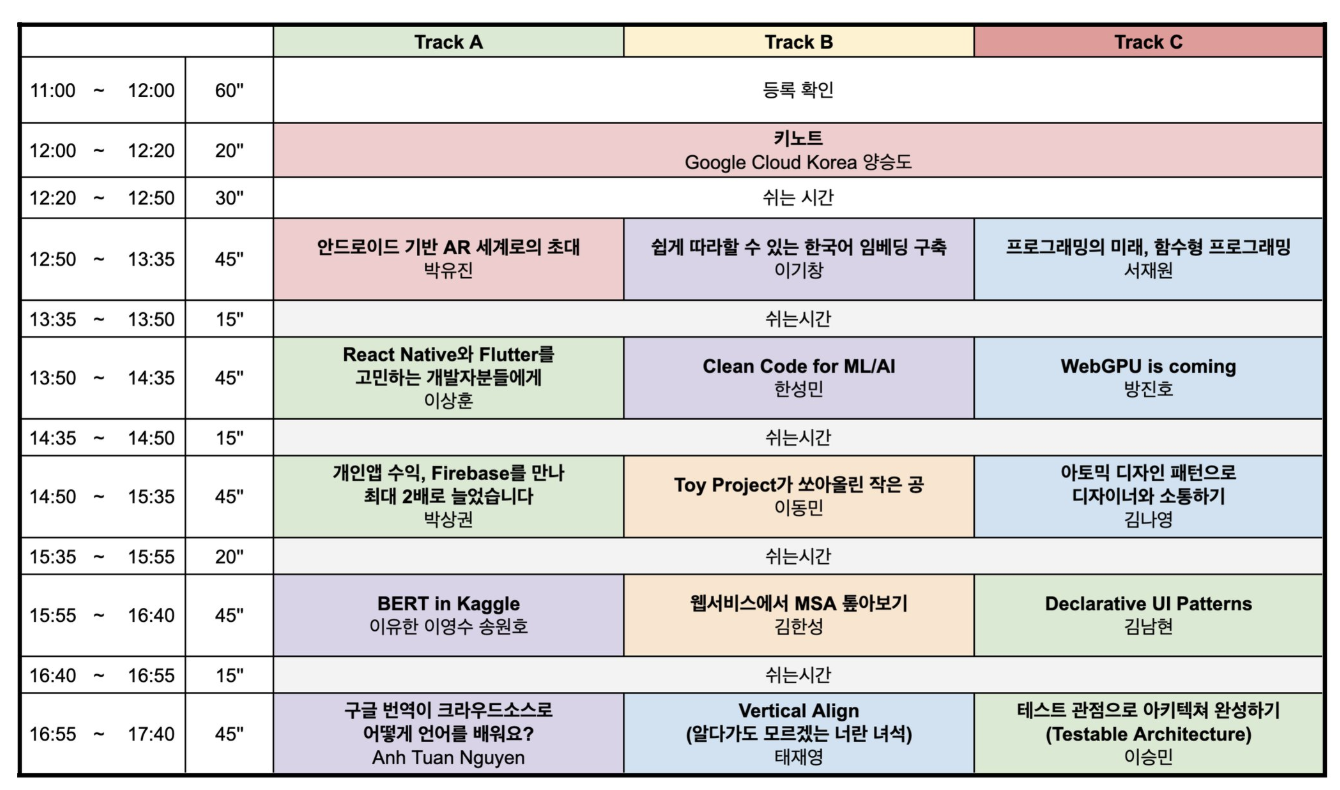
타임테이블은 다음과 같았습니다.
쉽게 따라할 수 있는 한국어 임베딩 구축 by 이기창님
맨 첫 번째로 Google Cloud Korea 양승도님께서 키노트 발표를 해주셨고 30분간의 쉬는시간을 가졌습니다. 그리고 제가 첫번째로 들으려고 했던 세션은 Naver 이기창님의 쉽게 따라할 수 있는 한국어 임베딩 구축 이었습니다. 쉬는시간에 밥을 빨리 먹으려고 하는데, 식사가 너무 늦게나오는 바람에 세션의 앞부분은 놓쳤습니다(ㅠㅠㅠㅠㅜㅠ). 아쉬운 부분이 있었지만, 핵심은 기존의 워드 기반의 임베딩보다 최근에는 문장 수준의 임베딩이 잘 된다는 것이었습니다. 문장 수준의 임베딩이 나온 이후로는 워드 기반의 임베딩에 관한 페이퍼가 거의 등장하지 않는다고 하셨습니다. 그 만큼 문장 수준의 임베딩의 결과가 훌륭하다는 것이겠습니다. 실제로 ELMo가 등장한 이후에 리서치 트렌드가 아예 문장 수준의 임베딩으로 바뀐것이 관찰되었습니다. 문장 수준의 임베딩에는 대표적으로 두 가지 알고리즘이 있는데 바로 앞서 말씀드린 ELMo와 그 유명한 BERT입니다. BERT는 transformer network이며 attention 기반으로 만들어진 것입니다. BERT는 기존의 일방향성의 문맥 흐름에서 양방향성의 문맥을 읽어냄으로써 동음이의어 분간을 가능하게 만들었습니다. BERT는 pretrain하고 fine tuning 하는 작업이 필요한데, pretrain하는 작업은 추천하지 않는다고 하였습니다. 그 이유는 이 모델을 훈련시키는데 GPU 8개로 2주의 시간이 필요하기 때문입니다. GPU리소스가 충분하다면야 가능하겠지만, 그 보다 공개된 BERT를 사용하면 좋겠습니다. 공개된 BERT 성능이 나쁘지 않기 때문입니다. 그리고 세션에서 마지막으로 강조한 부분은 임베딩 하고 그 위에 무엇을 올릴까에 관한 것이었습니다. 보통 Bi-Direction만 사용하곤 하는데, 그 위에 활용하는 부분은 자유롭게 바꿔보면서, 실험해보며 다양한 모델들을 만들어 볼 수 있다는 것으로 세션이 종료되었습니다.
쉬는시간에 밥을 빨리 먹으려고 하는데, 식사가 너무 늦게나오는 바람에 세션의 앞부분은 놓쳤습니다(ㅠㅠㅠㅠㅜㅠ). 아쉬운 부분이 있었지만, 핵심은 기존의 워드 기반의 임베딩보다 최근에는 문장 수준의 임베딩이 잘 된다는 것이었습니다. 문장 수준의 임베딩이 나온 이후로는 워드 기반의 임베딩에 관한 페이퍼가 거의 등장하지 않는다고 하셨습니다. 그 만큼 문장 수준의 임베딩의 결과가 훌륭하다는 것이겠습니다. 실제로 ELMo가 등장한 이후에 리서치 트렌드가 아예 문장 수준의 임베딩으로 바뀐것이 관찰되었습니다. 문장 수준의 임베딩에는 대표적으로 두 가지 알고리즘이 있는데 바로 앞서 말씀드린 ELMo와 그 유명한 BERT입니다. BERT는 transformer network이며 attention 기반으로 만들어진 것입니다. BERT는 기존의 일방향성의 문맥 흐름에서 양방향성의 문맥을 읽어냄으로써 동음이의어 분간을 가능하게 만들었습니다. BERT는 pretrain하고 fine tuning 하는 작업이 필요한데, pretrain하는 작업은 추천하지 않는다고 하였습니다. 그 이유는 이 모델을 훈련시키는데 GPU 8개로 2주의 시간이 필요하기 때문입니다. GPU리소스가 충분하다면야 가능하겠지만, 그 보다 공개된 BERT를 사용하면 좋겠습니다. 공개된 BERT 성능이 나쁘지 않기 때문입니다. 그리고 세션에서 마지막으로 강조한 부분은 임베딩 하고 그 위에 무엇을 올릴까에 관한 것이었습니다. 보통 Bi-Direction만 사용하곤 하는데, 그 위에 활용하는 부분은 자유롭게 바꿔보면서, 실험해보며 다양한 모델들을 만들어 볼 수 있다는 것으로 세션이 종료되었습니다.
Clean Code for ML/AI by 한성민님
15분의 휴식시간이 끝나고 두 번째 세션에 들어갔습니다. 두 번째로 들은 것은 Naver 한성민님의 Clean Code for ML/AI 였습니다. 클린 코드에 대한 중요성을 말하기전에 설명해주신 개념은 깨진 유리창 이론에 관한 것이었습니다. 품질이 떨어지는 코드를 쌓아올리는 시작하는 순간 부터 다른 협업자의 코드 품질도 떨어지기 시작합니다. 그렇기 때문에 보이 스카웃 규칙대로 코딩을 하는 것이 중요합니다. 그 규칙은 간단합니다.
클린 코드에 대한 중요성을 말하기전에 설명해주신 개념은 깨진 유리창 이론에 관한 것이었습니다. 품질이 떨어지는 코드를 쌓아올리는 시작하는 순간 부터 다른 협업자의 코드 품질도 떨어지기 시작합니다. 그렇기 때문에 보이 스카웃 규칙대로 코딩을 하는 것이 중요합니다. 그 규칙은 간단합니다.
- 떠날 때는 찾을 때보다 캠프장을 더욱 깨끗이 할 것
- 손을 거치게 된 코드는 원래 상태보다 더 낫게 만들고 떠나라
훌륭한 도입부와 더불어 기존에 제가 짠 코드가 더럽다고 계속 생각을 했었고, Clean Code에 대해서 중요성을 항상 들어왔기 때문에 더 집중하게 되었습니다. ML/AI 관련 코드를 짤 때면 If else구문을 자주 활용했었고, indentation이 복잡해져 가독성이 많이 떨어지는 일이 빈번했습니다. 역시 한성민님이 지적한 부분도 같았습니다.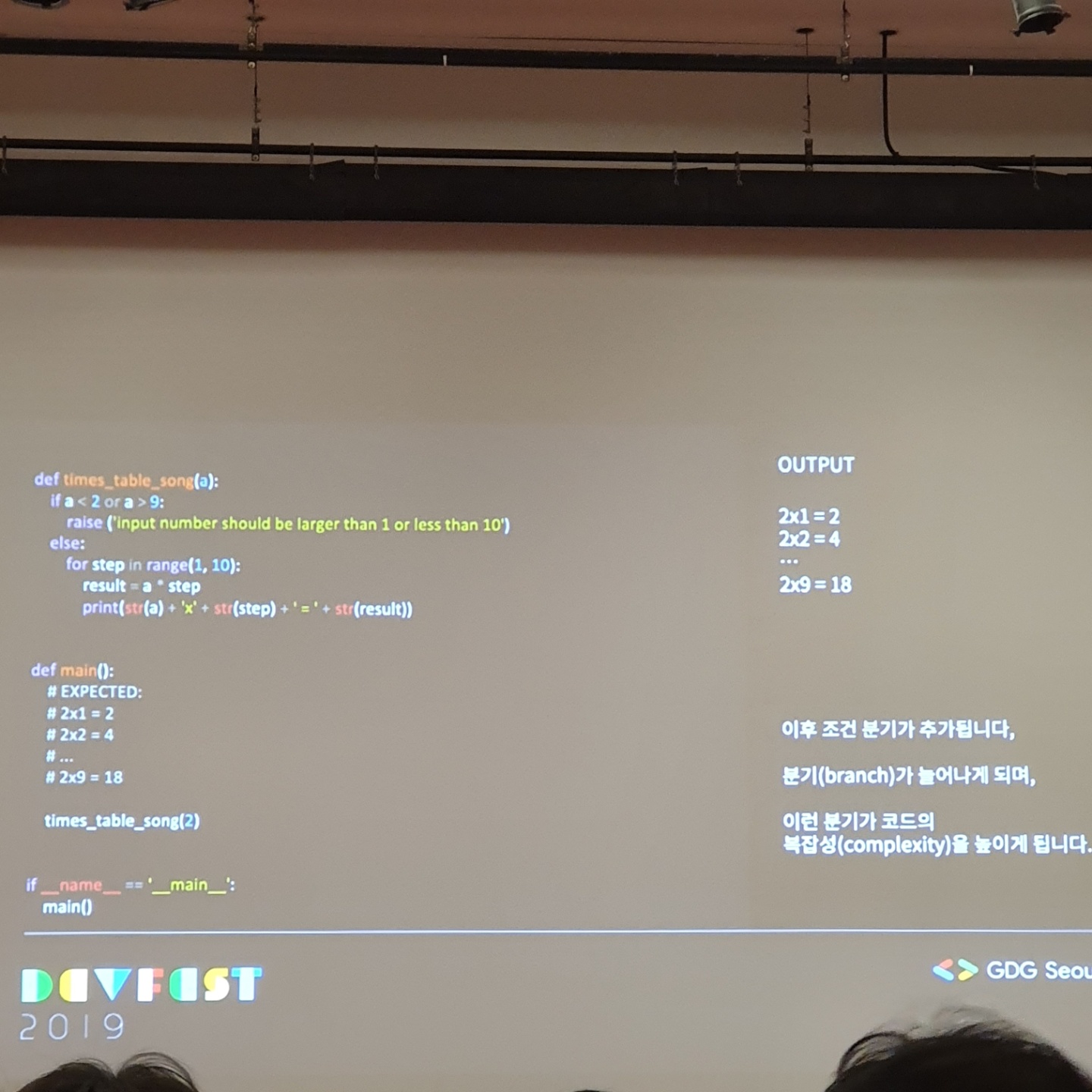
일명 코드 악취라고 불리는 더러운 코드들을 소개해주셨고, 깨끗하게 정리된 코드들을 보여주셨습니다.
보면서 느끼는 것이 너무 많았고, 회사에 있는 코드를 빨리 정리하고 싶다는 생각이 들었습니다. 최근에 한 프로젝트의 코드들이 눈앞에 지나가면서 다시보기 싫었던 그 느낌이 생각났습니다. 이 외에도 다양한 코드 악취 Case들을 보여주시고 정리한 내용들을 보여주셨습니다. 대표적으로 너무 많은 분기는 좋지 않으므로, return이나 continue를 이용해 가드 클로져 구문을 사용하는 것을 추천해 주셨고, 주ㅜ석 남용도 코드 악취에 해당하기 때문에 함수로 정의하는 것이 좋다고 말씀해 주셨습니다. 한 함수에는 너무 많은 기능을 담지 않고, 50줄 안으로 쓰는 것이 적정하며, 동일한 작동을 너무 많이 반복하는 것을 지양해야 함을 알려주셨습니다. 그 외에 연구자와 개발자끼리 코드 컨벤션이 맞지 않는 문제, IDE로 사용하지 않는 변수들 제거, 수정이 빈번한 변수들은 전역 변수로 추출, 복잡성이 높은 로직에 대해서 함수 추출해 optimizer과 hyperparameter로 뽑아내기 등을 설명해 주셨고
google/gin-gonfig나 Lint와 Quality Gate와 같은 클린코드 툴을 알려주셨습니다. 개인적으로 느끼기에는 바로 써먹을 수 있고, 코드의 퀄러티가 높아질 수 있기에 너무 좋은 세션이었습니다. 클린 코드에 대해서 제대로 느끼게 만든 훌륭한 강의였습니다.
BERT in Kaggle by 이영수님, 송원호님, 이유한님
세번째 세션은 듣고싶었던 캐글 세션이었습니다.
먼저 이영수님께서 BERT의 개념에 대해서 간략하게 설명해 주셨습니다. 맨 처음에 들었던 세션인, 이기창님의 세션에서 이해가 잘 안되었던 부분이 이영수님의 세션을 통해 어느정도 해결이 되었습니다.
설명이 어느정도 끝나고 다음 바통을 잡은 분은 송원호님이었습니다. 송원호님은 Toxic 대회를 진행하면서 BERT를 통해 스코어를 올렸었던 경험에 대해서 설명해 주셨습니다. Toxic대회는 2017년에 한번 진행했었던 대회인데, 어떤 코멘트에 대해서 이 코멘트가 정상인지 악성인지 분류하는 문제입니다. 2019년에 다시 열리기 된 것은 바로 Unintended Bias가 추가되었기 때문입니다. 특정 키워드가 들어가게 되면 악성으로 분류되어버리는 문제 때문에, 이것을 더 정밀하게 분류해 내는 모델이 필요했고, 더 정밀해진 Metric을 만족시켜야 하는 대회였습니다. 그렇기 때문에 Metric에 대한 설명이 쭉 진행되었고 Metric에 맞는, 기존 loss와 다른 loss function을 재 정의했어야 했던 점을 설명해 주셨습니다. 결구 새로 열린 이 대회에서 중요했던 것은 문맥이었습니다. 문맥을 잘 살려서 코멘트를 분류해야 했었기 때문에 BERT로 접근을 했고 그 결과가 Baseline을 사용할 때에 비해서 좋아질 수 있었습니다. Leaderboard 상으로는 10등으로 in-money권에 있었지만 결과는 26등이었습니다. 쉐이크업으로 인해 등수가 떨어지게 되었는데, 캐글의 discussion에서 그 이유가 등장했습니다. 원호님과 비슷하게 접근을 했지만 높은 등수를 기록했던 분과의 차이점은 모델에서 BERT large, small, medium을 다 사용했고 GPT 2 small도 활용하며, XLNet까지 사용했다는 점이었습니다. 크고 다양한 언어 모델을 사용했고 속도 문제에 있어서는 Sequence Bucketing을 통해 해결한 점이 큰 차이점이었습니다. 결론은 다음과 같았습니다.
- NLP 에서 좋은 머신은 꼭 필요하다.
- 작은모델 큰 모델 다 중요하다.
- Evaluation에 맞는 loss를 잘 정의해야한다.
- 파이프라인을 일찍 구성하고 실험을 많이 해봐야 한다.
- 제한된 시간하에 높은 점수를 위해 속도 줄이기 위한 여러 기술이 필요하다.
그 다음으로는 생일을 맞으신 이유한님이 발표해주셨습니다.
이유한님게서는 분자대회에서 BERT를 사용한 경험에 대해서 전달해주셨습니다. 먼저 과학에서 머신러닝이 어떻게 사용되는지에 대해 간략히 설명해 주셨고 과학과 머신러닝의 유사점에 대해서 정리해주셨습니다. 본격적으로 분자대회에 대해서 설명을 해주셨는데, 정확하게는 이해하지 못했고 아무튼 양자 계산으로 너무 힘든 분자에 관한 어떤 예측 문제를 딥러닝을 이용해서 풀어보는 대회였습니다. 보통 분자는 그래프 네트워크와 유사한 부분이 있습니다. 그래서 유한님도 처음에 GNN을 통해 접근을 했었다고 합니다. 하지만 분자를 sentence로 풀어서 BERT에 넣어봤더니 성적이 갑자기 뛰기 시작했습니다. 그래프 네트워크보다 오히려 더 좋은 성적이 나오기 시작한 것입니다. 분자의 정보를 문장화 시켰고, 각 정보를 임베딩하고 벡터화했습니다. 그리고 데이터에 기반해 자발적으로 학습된 임베딩을 뽑아냈습니다. 결국 임베딩도 학습된 것이고 임베딩된 결과도 학습되었습니다. end to end 모델로 구성한 것이고 결국 딥러닝 모델이 알아서 다 하게 되는 모델을 만들어 낸 것입니다. 여기에 Auxiliary targets을 이용해서 5개의 타겟으로 학습시켰고, 세밀한 정보가 도출되어 이것을 이용해서 점수를 끌어내었다고 설명해 주셨습니다. 여기까지 대회에 대해서 정리해 주셨고, 캐글 코리아 운영자답게 캐글 대회에서 높은 점수를 받는 방법에 대해서 알려주셨습니다.
캐글에서 높은 점수를 얻으려면?
- Diversity를 살려서 Ensemble하자
- 다양한 모델의 사용
- 다양한 시드, 아키텍쳐 같아도 시드가 다르면 다른 모델
- Pseudo Labeling, 예측한 값을 타겟으로 한 테스트 셋으로 새로 학습을 진행한다.(대회니까 가능함)
- 뭘 쓸까 항상 생각해야 한다. 학습 방식을 선택해야 하는데, EDA를 통해서 특성을 파악하고 모델을 선택해야 한다.
- Loss functionn을 잘 찾아야 함,
- BCE, MAE, MSE, CORAL, DICE 등, 다 해보고 좋은 것을 선택한다
- 학습이 잘 될 수 있는 학습 스케쥴링구글 번역이 크라우드소스로 어떻게 언어를 배워요? by Anh Tuan Nguyen
마지막으로는 구글 브레인의 안 투앙님의 발표였습니다. 프랑스분이셨는데, 한국어로 발표해주신 점이 인상깊었습니다.
발표는 간단했습니다. 머신러닝에 대해서 설명하고, 학습과 추론에 대해서 짚었습니다. 지도학습에 대해서만 말씀해주셨고 이 모델을 활용하는 것에서는 Google의 photo에서 텍스트를 감지하는 것, 그리고 동물 감지, 예를 들어 강아지를 포토에서 검색하면 찍은 사진중에 강아지가 감지된 사진이 선택되는 것을 말씀해 주셨습니다. 그리고 번역에 대해서 말씀을 하기 시작하셨는데, 가끔 번역이 잘 안되는 내용이 있다고 하셨습니다.

위의 사진들이 그 예를 찍은 것입니다. 고치는 방법은 여러가지가 있겠습니다만, 많은 데이터를 통해서 해결해 나갈 수 있습니다. Google Crowdsource라는 앱을 통해서 가능하다는 것입니다. 일종의 게임을 만들어서 사용자가 해석에 대한 맞는 라벨을 골라주는 것입니다. 이 게임을 통해서 뱃지를 얻을 수 있고 레벨을 올릴 수 있다고 설명해 주셨습니다. 발표시간이 조금 남아서 질문 답변 시간을 길게 가졌고 이 마지막 세션을 끝으로 GDG DEVFEST행사가 종료되었습니다.
처음 가본 GDG행사였는데, 알고 싶었던 BERT모듈에 대해서 일부 알게 되었고, Kaggle에 대한 경험담과 피와 살이 될 것 같은 Clean code에 대해서 제대로 알 수 있게 되어 좋았습니다. 일찍 예매해서 만원정도에 티켓을 구매할 수 있었는데, 값이 아깝지 않았습니다.(물론 GDG에 참여한 회사들의 굿즈들을 많이 받고 간식도 많이 먹긴 했습니다.) 다음에 또 이런 행사가 있으면, 꼭 참여하고 싶다는 생각이 들었고 언젠가는 저기서 발표하고 싶다는 작은 목표를 기록해두면서 글을 마무리합니다.
2019 GDG DEVFEST SEOUL 행사를 다녀오다