Zeppelin으로 Spark를 다뤄보자 01
pyspark로 데이터를 읽으려면 어떻게 해야할까?
Zeppelin 이용해서 pyspark로 데이터 읽기 01
Spark는 고속 범용 분산 컴퓨팅 플랫폼으로 정의되곤 합니다. 대용량 데이터를 가져와 빠르게 분석해 낼 수 있다는 점에서 많은 기업들에서 도입을 검토하고 있고 실제로도 많이 사용되고 있습니다. 오늘은 이 유명한 Spark를 다운받고 Zeppelin으로 띄워서 pyspark를 이용해 데이터를 읽어보는 작업까지 해 보겠습니다.
먼저 Spark를 다운받아 줍니다. Spark 설치

링크로 들어가면 다음과 같이 나오는데 다운받는 버전은 아무거나 받아도 상관 없지만 저는 AWS EMR로 Spark를 도입하기 전에 연습하는 용으로 사용하는 것이기 때문에 AWS EMR 버전과 같은 2.4.4버전을 다운받았습니다.
하둡 버전은 사진 그대로 2.7버전으로 진행 했습니다.
다운이 완료되면 폴더를 만들어서 그곳에 저장해주고 압축을 풀어줍니다.
tgz로 되어있는 파일은
1 | tar -xvf [filename] |
이렇게 풀어줍니다.
다음은 Zeppelin입니다. Zeppelin 설치
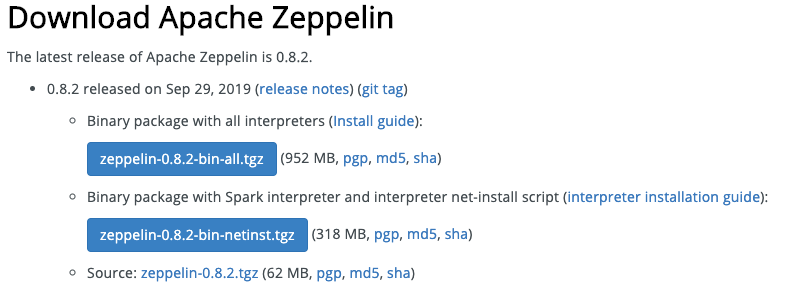
제플린도 역시 두 가지 버전이 등장하는데, 저는 용량이 작은 버전으로 받았습니다. 큰 용량의 버전은 카산드라 등이 다 포함된 버전이기 때문에 굳이 받지 않았습니다.
제플린도 특정 폴더에 저장해주고 압축을 풀어줍니다.
Spark 경로 지정
Spark의 경로를 잘 지정해줘야 Zeppelin이 실행되고 코드를 돌렸을 때 오류가 나지 않습니다.
먼저 쉘의 프로파일을 열어줍니다. 저는 zsh을 사용하기 때문에 zshrc를 열겠습니다.
1 | vi ~/.zshrc |
그 다음 설정해야 할 것은 java home 경로입니다. jdk가 없다면 jdk 1.8이상 버전을 다운받아 설치합니다.
java home 경로는
1 | echo $JAVA_HOME |
이 명령어로 알아낼 수 있습니다. java home의 경로를 알아냈다면 zshrc에 이 위치를 알려줘야합니다.
1 | export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home" |
저의 경우는 위치가 다음과 같아서 zsh의 아래쪽에 작성해 주었습니다.
그리고 설치된 Spark의 위치도 알려줘야 합니다. 아까 저장했던 폴더의 주소를 입력해 줍니다.
1 | export SPARK_HOME=/Users/sanghyub/spark-2.4.4-bin-hadoop2.7 |
저의 경우는 이렇게 되어있습니다. 절대경로로 작성해 주시면 됩니다.
Spark 세팅은 일단 여기까지 하고 Zeppelin으로 넘어가겠습니다.
Zeppelin 환경 설정
Zeppelin이 저장된 폴더로 들어가서 conf로 들어가줍니다. conf에는 ls를 입력해보면 여러 파일들이 있는 것을 볼 수 있습니다.

이 파일들 중에서 zeppelin-env.sh와 zeppelin-site.xml을 사용해야 하는데, .template으로 된 파일들이 보일 것 입니다. template를 cp를 이용해서 바꿔줍니다.
1 | cp zeppelin-env.sh.template zeppelin-env.sh |
cp는 복사하는 것도 있지만, 이렇게 이름을 바꿔주는데에도 사용됩니다.
zeppelin-env.sh와 zeppelin-site.xml을 얻었다면 vi를 이용해서 zeppelin-env.sh로 들어갑니다.
아까 작성한 자바 경로와 스파크 홈 경로를 그대로 갖고와서 작성해줍니다. zeppelin이 이 위치를 보고 Spark와 jdk를 이용할 수 있도록 적어두는 것 입니다.
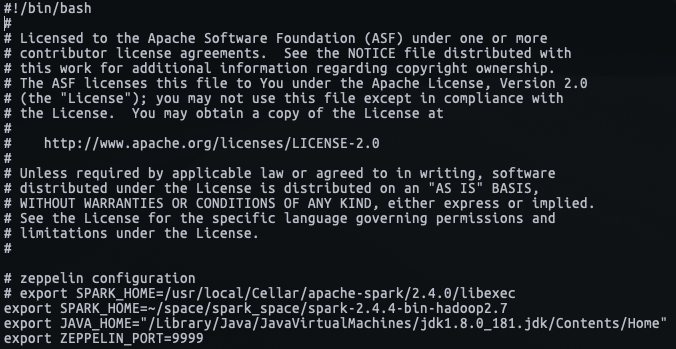
zeppelin의 포트도 수정해 줍니다. 기본 포트는 8080포트인데 혹시 충돌될 수 있으니, 저는 안정적으로 9999포트로 변경하겠습니다.
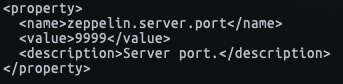
이제 기본적인 세팅은 끝났고 zeppelin을 실행시켜 봅니다.
Zeppelin 실행
Zeppelin 실행은 jupyter notebook여는 것과는 조금 다릅니다. zeppelin을 입력해도 아무일도 일어나지 않습니다. Zeppelin을 열기 위해서는 zeppelin daemon을 실행시켜줘야 합니다.
zeppeliln daemon은 bin폴더에 있습니다. conf에서 빠져나와서 bin으로 들어가줍니다.
1 | cd ../bin |
ls를 입력하면 찾았던 daemon이 보일 것 입니다. 너무 반갑지만 쉘이 익숙하지 않다면 실행하는 방법을 모를 것입니다. 저도 그랬고 같이 공부했던 사람들도 눈치만 봤었습니다. 백날 눈치를 보고 째려봐도 실행은 되지 않습니다.
1 | ./zeppelin-daemon.sh start |
이렇게 데몬을 실행시켜줍니다. 확인은 (https://localhost:9999)로 들어가서 해 보면 됩니다.
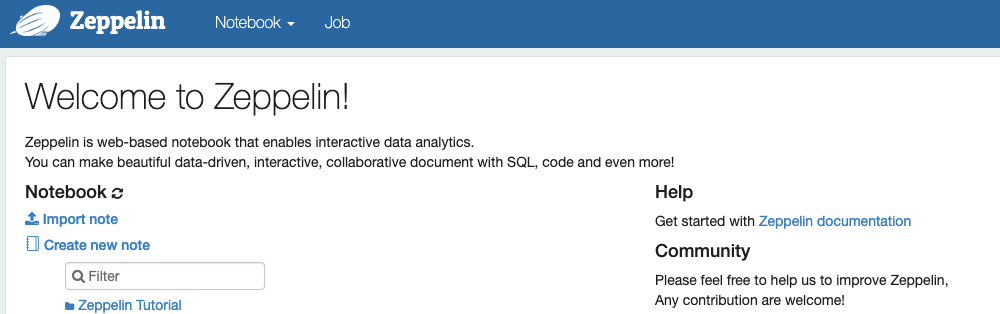
짠! 제플린의 날개가 등장했습니다. 이제 노트를 만들고 데이터를 로드해보는 작업을 하겠습니다.
Zeppelin으로 Spark를 다뤄보자 01