Spark에서 데이터 분석 시, RDD로 연산하면 안되는 이유
Spark를 사용해서 데이터를 읽고 분석하자
데이터 분석하기 전, 데이터부터 읽자
Spark Session, conf 설정
기존 python의 pandas를 이용해서 데이터를 읽으려면 pd.DataFrame(‘…….’)를 통해 파일을 읽으면 간단히 해결 되었다. 하지만 spark에서 데이터를 읽기 위해서는 조금 더 손을 거쳐야 한다. 물론 Zeppelin을 이용한다면 바로 파일을 읽어들일 수 있겠지만, pycharm을 이용해서 pyspark application을 만드는 작업을 할 것이기 때문에 직접 spark세팅을 해주어야 한다.
pycharm에서는 Spark Session을 설정해줘야 spark를 사용할 수 있다. 이 Spark Session에 대한 설정값으로 Spark Conf를 설정해주어야 한다.
먼저 필요한 라이브러리를 불러들이고 Spark conf와 session을 설정한다.
1 | from pyspark.conf import SparkConf |
conf.set에는 mongoDB와의 연결을 위한 spark connector를 넣어줬다. 이렇게 하면 mongoDB에 있는 데이터를 바로 읽을 수 있을까? 아직 할 작업이 조금 남았다. data를 불러오기 전에 스키마 지정을 해줘야 하기 때문이다.
스키마 지정
스키마란 간단하게 말해서 데이터 구조와 제약 조건에 대한 명세(Specification) 기술한 것을 의미한다.
여기서 설정할 스키마는 이 데이터의 칼럼이 어떤타입으로 들어갈 것인지(string, integer, double …)를 주로 뜻하게 될 것이다.
mongoDB에서 사용자들이 거래한 내용 중 카트에 어떤 상품을 담았는지 알기 위해서 다음과 같이 코드를 작성했다.
1 | cartSchema = StructType([ |
이렇게 카트 데이터에 대한 스키마를 작성해서 유저스키마의 cart 부분에 넣어준 뒤 합쳐진 userSchema를 이용해 데이터를 읽었다.
1 | df = spark.read.schema(userSchema).format("com.mongodb.spark.sql.DefaultSource") \ |
읽은 결과는 따로 dataframe을 지정할 필요없이 바로 dataframe으로 떨어진다. 이제 바로 데이터에 대해서 작업을 수행할 수 있게 되었다.
카트에 담은 상품이 무엇인지 알고 싶어서 actionType이 viewCart인 부분을 가져왔다.
1 | view_cart_df = df.filter(df.actionType =='viewCart') |
가져오고 나서 전처리 작업을 하려고 했는데, 데이터프레임에 대한 이해가 적었었던 때라 어떻게 작업해야 할지 몰랐다. 그래서 먼저 RDD로 작업을 했고 뼈저리게 후회했다. 절대 발생하면 안되는 일이 일어났기 때문이다.
RDD를 사용한 결과
RDD를 사용해서 전처리를 해보고 Cart에 담긴 Top N개의 상품을 가져와보기로 했다.
1 | def get_info(x): |
RDD를 이용해 전처리를 할 때 쓸 함수를 지정해 놓고 작업을 하기로 했다. 함수는 다음과 같이 작성했고 상품의 코드와 그 상품이 얼마나 담겼는지를 Row로 생성했다.
1 | df = df.filter(df.cart.isNotNull()).withColumn("currentTime", to_timestamp("currentTime", "yyyy-MM-dd HH:mm:ss")) |
이렇게 만든 함수를 df의 cart에서 rdd의 map을 이용해서 결과를 가져왔다. 그리고 상품코드 별로 그룹화 하고 sum을 해서 결과를 출력했다.
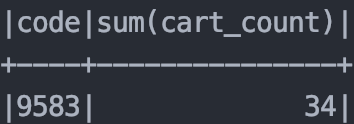
그런데 뭔가 이상했다. sum을 했으면 결과값이 적어도 100은 넘어야 했는데, 100넘는 값이 너무 적었다. 그래서 특정 상품코드에 대해서 python으로 데이터 분석을 실시해서 결과를 매칭시켜 비교해보기로 했다.

결과가 너무 차이가 났다. 이렇게 나온 결과로 아이템을 추천하게 되면 제대로 된 상품이 추천되지 않을 것이다. RDD에 함수를 map하는 것에 뭔가 문제가 있는 것이 분명했다. 방법을 찾다가 Dataframe으로 작업을 해보기로 했다.
Dataframe을 사용한 결과
데이터 프레임으로 작업해야 결과값이 바뀌지 않는 다는 정보를 알게 되어 기존에 있던 df에 filter를 걸어 새 DF를 만들고 이걸 가지고 전처리 해보기로 했다.
1 | cartDF = df.filter(df.cart.isNotNull()).withColumn("currentTime", |
작업은 다음과 같이 실시했고 상품 갯수를 정렬하기 위해서 orderBy를 사용했다.
결과는 어떻게 나왔을까?
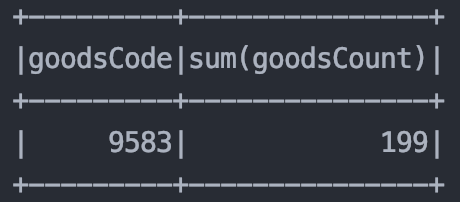
python을 사용한 결과와 똑같은 값이 등장했다. 성공했다!!!
왜 값이 다를까?
그렇다면 왜 RDD를 사용해서 함수를 적용할 때랑 Dataframe을 갖고 작업한 결과가 다른 것일까?
일단
1 | view_cart_count = df.select('cart').rdd.map(get_info) |
이 코드에서 rdd.map한 부분까지 가져와서 확인해보니 결과값이 많지 않았다. rdd에서 df로 바꿀때 데이터가 변하는 일은 없다는 것이다.
그렇다면 이 코드 전에 rdd.map(get_info)하는 부분에서 변형이 일어난 거라고 추측할 수 있다. 하지만 spark 이론에서 map을 적용할 때는
map 자체가 narrow transformation에 해당되기 때문에, shuffle이 일어나지 않는다고 나와있다. 결국 shuffle에 의한 데이터 변형의 가능성도 없다고 할 수 있는 것이다. 함수 자체에 이상이 있는 것일까? 그렇다고 보기엔 어렵다. 이 코드를 갖고 구매-할인율에 대한 것을 집계했을 때는 정확한 값이 나왔기 때문이다.
조금 더 공부해보고 왜 값이 다른지에 대해서는 추후에 계속 수정을 해 나가야겠다.
결국은 spark에서는 RDD를 사용할지 Dataframe을 사용할지, 그리고 Dataset을 사용할지 먼저 생각하고 작업하는 것이 중요하다.
이것에 관련해서는 Databricks에서 나온 문서가 있는데, 이것은 추후에 번역해서 업로드할 예정이다.
Spark에서 데이터 분석 시, RDD로 연산하면 안되는 이유