Ensemble에 대해 자세히 알아보자 (Bagging, Bootstrap, 그리고 RandomForest)
앙상블 모델에 대해서 공부하기 전에, 그 배경부터 알아볼 필요가 있다.
NFL (No Free Lunch)
No Free Lunch 이론은 David H. Wolpert가 정리한 이론으로 모든 문제에 대해 다른 모든 알고리즘을 능가하는 모델은 없다는 이론이다. ‘어떤 특정 정책에 의해 얼핏 보면 이득을 얻는 것 같지만, 그것은 한 측면의 이득일 뿐이고 반드시 이면에 다른 측면이 있고 그 측면에서 손해가 발생한다.’는 것이 핵심이다.
이 이론에 따라서 혼성모델의 필요성이 대두되었다. 혼성모델이란 여러 알고리즘을 결합하는 모델이다. 이 모델은 특정 문제가 주어진 상황에서 그 문제를 가장 높은 성능으로 풀 수 있는 알고리즘에 대한 필요성에 의해서 제시되었다.
Resampling
리샘플링은 데이터가 부족할 때 같은 샘플을 여러번 사용하는 것을 말한다. 성능 통계치의 신뢰도를 높이기 위해 사용된다. Resample을 하는 이유는 다음과 같다.
실제 상황에서는 만족할 만한 큰 샘플을 얻기가 힘들다.
Bias-Variance Trade off를 통해 큰 샘플이 중요하다는 것을 알 수 있다.
sample의 집합이 커지면 variance가 감소한다!, MSE도 감소한다!
모델의 선택은 별도의 검증이 필요하다.(검증용 데이터, 큰 샘플의 필요성)
Bootstrap, Statistical term for “roll n-face dice n times”
부트스트랩은 Resampling을 이용하여, 분류기의 성능을 측정하는 방법 중 하나이다. 통계에서는 추정치에 대한 검증용(가설 검증)으로 많이 사용된다. 부트스트랩의 장점은 한번도 뽑히지 않은 데이터가 발생한다는 것이다. 이를 통해 데이터를 아낄 수 있게 된다.
Ensemble
앙상블 모델은 혼성모델 중 하나이다. 앙상블은 두가지 방식이 존재한다.
같은 문제에 대해 서로 다른 여러 알고리즘이 해를 구하고, 결합 알고리즘이 그들을 결합하여 최종 해를 만드는 방식
문제와 유사한 여러 하위 문제들에 대해 하나의 알고리즘이 해를 구하고, 결합 알고리즘이 그들을 결합하여 최종 해를 만드는 방식
앙상블의 동기는 단순히 통계적, 수학적일 뿐만 아니라, 사람들의 심리 등 여러부분을 관통하는 내용이기도 하다.
1 2
어느 도시에서는 소를 광장에 매어 놓고 참가자들에게 체중을 추정하여 적어 내게 하고 실제 체중에 가장 가까운 사람에게 상품을 주는 대회가 있다고 한다. 수백 명이 참가하는데 그들이 적어낸 숫자들을 평균해 보면 답과 아주 근사하다고 한다.
사람들은 중요한 결정을 할때 여러 사람의 의견을 들어보고 결정하려는 경향이 있고, 이런 경향은, 통계학이 아닌 다른 분야에서도 사용되는 개념이다.
다양성
앙상블 모델의 핵심은 다양성이다. 앙상블에 참여한 모델이 모두 같은 결과를 낸다면, 그것은 앙상블 모델로써 어떠한 장점도 갖고 있지 않다. 한 분류기가 틀리는 어떤 문제를, 다른 분류기에서는 맞출 수 있어야 앙상블 모델로써 가치가 있을 것이다.
앙상블 분류기 시스템은 앙상블 생성, 앙상블 선택, 앙상블 결합의 단계를 거친다.
앙상블 생성
Resample을 이용해서 (Bagging, Bootstrap) 샘플 집합들을 생성하고, 분류기를 훈련한다.
Feature Vector의 subspace를 이용해서 샘플 부분 집합을 생성하고 분류기를 훈련한다.
앙상블의 분류기는 요소분류기와 기초분류기로 구분된다.
앙상블 결합
요소 분류기(기초 학습기)들의 출력을 결합하여 하나의 분류 결과를 만드는 과정이다. 요소 분류기의 출력은 세가지의 방식으로 나뉜다.
Class Label
Majority Vote : class 라벨이 많이 나온 쪽으로 분류한다.
Weighted Majority Vote : 성능 좋은 분류기에 가중치를 부여한다.(Adaboost)
Behavior knowledge space(BKS/행위지식공간) : 경험한 케이스를 테이블로 갖고 분류기 결과를 보고 경험적으로 결정한다(테이블에서 찾아서). 다수결 방법의 성능을 고도화 할때 사용됨
Class Ranking
Borda 계수
Class Probability
Softmax
Bagging (Bootstrap + Aggregating)
부트스트랩을 다중 분류기 생성 기법으로 확장한 것이다. 부트스트랩 된 샘플 집합에서 훈련을 하고, 입력 값에 대해 분류기들의 평균값이나, 다수결 투표를 취한다. 샘플링은 복원추출하는 방식으로 하고, 훈련된 분류기의 결과를 모두 종합하기 때문에 Bagging이라고 부른다.
반복적인 복원 추출 (Bootstrap)
결과를 모두 종합 (Aggregation)
Bagging, 배깅은 언제 사용할까?
배깅은 편향이 작고 분산이 높은 모델에 사용하면 효과적이다.
트리 분류기와 같이 불안정성을 보이는 분류기에 큰 효과를 발휘
훈련 집합이 달라지면 차이가 큰 트리가 생성 ⇒ 다양성 확보
Bias를 변화시키지 않고 variance를 감소시킨다.(Bias를 쪼오오오오끔 희생한다.)
배깅은 분산을 감소시키기 위해, 훈련데이터에서 많은 샘플링을 하고(Bootstrap), 샘플들로 별도의 Decision Tree를 구성한 후, 회귀나 분류문제를 푸는데 사용된다. 회귀는 분류기 결과의 평균값을 사용하고, 분류는 최빈값을 취한다.
배깅은 이미 저분산 모델인 경우 별로 효과가 없다. Bias-Variance Tradeoff 를조금만 생각해보자. 분산이 이미 줄어있는 상태에서는 더 줄일 분산이 없다. 배깅은 오직 분산을 줄이는 데 효과적이다.
부트스트랩되지 않은 샘플들은 한번도 사용되지 않은 샘플들로 검증데이터에 활용할 수 있다. 이런 training observations은 out-of-bag observations이라고 불린다.
OOB estimate of test error
부트스트랩 샘플을 이용하여 개별 학습기를 학습한 후, OOB에 속하는 샘플들에 대한 예측값을 모두 구한다.
OOB의 실제 라벨값과 OOB의 예측값을 이용하여 OOB error를 구한다.
모든 부트스트랩 샘플 sets에 대하여 위의 과정을 반복하면, 샘플 sets 수 만큼의, errors를 모을 수 있다.
OOB errors의 평균값을 이용하여 bagging 모델의 최종 테스트 error를 계산한다.
Weakness of Bagging
배깅은 엄청나게 효과적인 것처럼 보이지만 약점이 존재한다. 배깅은 feature를 모두 사용하고, row를 랜덤하게 선택하는 것이다. Decision Tree를 만든다고 해보자, 만약 영향력이 높은, Information Gain이 높은 모델을 사용한다고 했을때, 특정 Feature만 계속 선택되서 트리가 만들어질 가능성이 있다. 즉, 중요한 칼럼들이 트리의 초기 분기때 모든 표본에 그대로 존재하게 된다. 이렇게 되면 만들어진 대다수의 트리들의 결과가 비슷해진다. 이것이 반복되면 트리간의 상관관계가 발생해서 분산 감소의 효과가 줄어들게 된다. (배깅의 약점은 IID condition이다. IID 조건을 만족하는 경우 분산은 $Var={\sigma^2\over n}$이 되지만, IID를 만족하지 못하는 경우, 상관관계가 발생하여 $Corr = p$이라고 할때, $Var = p\sigma^2$가 된다.)
그래서 혁신적인 아이디어와 함께 등장하게 된 것이 Random Forest이다.
Random Forest
랜덤 포레스트는 일반적으로 bagging 방법(또는 pasting)을 적용한 결정 트리의 앙상블이다. 랜덤 포레스트 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 더 주입한다. 트리를 더욱 다양하게 생성하고 (트리의 의존성을 낮추고, 다양성을 증가) 편향을 손해 보는 대신 분산을 낮추어 전체적으로 더 훌륭한 모델을 생성한다.
Random Forest는 쉽게 말해 Tree 모델에 Bagging과 Subsampling기법을 사용한 모델이다. 훈련 데이터에서 bootstrap 샘플을 뽑아내고, 노드 분기 시, 모든 Feature가 아니라, 일정 Feature만 사용하는 것이 특징이다. 이를 통해 Tree간의 Correlation을 줄이고, 분산을 감소시킬 수 있다.
Subspace Sampling
샘플링 시에는 일반적으로 전체 변수가 p라고 할 때, $m = \sqrt{p}$를 사용한다. (m = p이면 Bagging이다. 또한 회귀에서는 경험적으로 $m ={p\over3}$를 사용한다.)
Random Forest 모델의 장단점?
장점 : 굉장히 간편하다. 스케일링도 필요없고 파라미터 튜닝을 많이 안해도 성능이 뛰어나다. 의사결정의 트리의와 배깅의 단점은 극복하고 장점만을 가져온 것이라고 할 수 있다.
단점 : 차원이 높고 매우 희소한 데이터에서는 잘 작동하지 않는다. 이런 희소한 데이터에는 선형 모델이 더 적합할 수 있다.
Posted Updated ML / Statistics8 minutes read (About 1145 words)
Kaggle이나 데이터 분석을 하다보면 성능을 높이기 위해 여러가지 feature들을 만들어낸다. 그런데 feature를 무조건 많이 만든다고 성능이 올라갈까? 아니다. target에 대한 영향력이 큰 feature들이어야 성능에 영향을 줄 수 있을 것이다. 그렇다면 중요한 건, 만들어낸 feature들을 어떻게 평가할 것인가이다.
Kaggle에서 Feature Selection 하는 방법들을 보면 gbm모델들의 Feature Importance를 이용하거나 DecisionTree나 RandomForest의 Classifier 객체의 feature_importances_ 메서드를 활용해 Feature Importance를 구해서 비교하는 모습들이 자주 보인다.
하지만 또 다른 방법으로, Information Value를 이용한 Feature Selection을 소개해보고자 한다.
1. Information Value (정보 가치)
모델에서 변수의 사용유무를 판단하는 feature selection에서 유용한 방법이다. 주로 모델을 학습하기전 첫 단계에서 변수들을 제거하는 데 사용한다. 최종 모델에서는 대략 10개 내외의 변수를 사용하도록 한다(여러개 만들어 보고 비교해보는 것이 좋다). IV와 WOE 신용채무능력이 가능한(good) 고객과 불가능한(bad) 고객을 예측하는 로지스틱 회귀 모델링과 밀접한 관계가 있다. 신용 정보 관련분야에서는 good customer는 부채를 갚을 수 있는 고객, bad customer는 부채를 갚을 수 없는 고객을 뜻한다. 일반적으로 이야기할 때는 good customer는 non-events를 의미하고 bad customer는 events를 의미한다.
신용 관련 분야
$${WOE} = ln{\frac{\text{distribution of good}}{\text{distribution of bad}}}$$
$${IV} = \sum{(\text{WOE} \times (\text{distribution of good} - \text{distribution of bad}))}$$
일반적
$${WOE} = ln{\frac{\text{distribution of non-events}}{\text{distribution of events}}}$$
$${IV} = \sum{(\text{WOE} \times (\text{distribution of non-events} - \text{distribution of events}))}$$
Information Value 값의 의미
Information Value
예측력
0 to 0.02
무의미
0.02 to 0.1
낮은 예측
0.1 to 0.3
중간 예측
0.3 to 0.5
강한 예측
0.5 to 1
너무 강한 예측(의심되는 수치)
Information Value를 통해서 ‘이 feature를 꼭 사용해야하나?’에 대해 어느정도 답을 내릴 수 있다.
Information Value가 0.5~1.0인 구간을 보면, 강한 예측이지만 의심되는 수치라고 되어있다. 처음보면 이게 무슨 의미인지 잘 이해가 안될 것이다. ‘너무 예측을 잘하는데 수치를 의심하라고?’
하지만 잘 생각해보자. IV는 WOE를 활용한다. WOE는 good과 bad의 분포를 이용하는데, 데이터가 good으로 쏠려있을 경우 WOE는 무조건 잘 나올 수 밖에 없고, 이에 따라 IV값도 잘 나오게 된다.
프로그래머스 문제를 쭉 풀면서, 코딩테스트를 몇번 보게 되면서 느낀 점은, 내가 알고리즘 기초가 부족하다는 것이었다. 문제를 보고 고민하는 시간이 너무 길었다. 고수들의 코드를 보면 고민한 시간은 잘 모르겠지만, 생각하는 방향이 딱딱 정해져서 배운 알고리즘과 자료구조 지식을 활용해서 답을 작성한 것이 눈에 띄었다.
반면에 나는 너무 막코딩하는게 아닌가 하는 생각이 들었다. 막코딩의 단점은 문제를 풀었어도 머리 속에 정리가 되지 않는다는 점이다. 머리에 남지 않으면 비슷한 문제가 나와도 틀릴 확률과 문제에 푸는 시간이 증가한다.
막코딩의 이러한 악효과를 차단하기 위해서 프로그래머스도 뒤져보고 엘리스도 뒤져보던 도중 엘리스의 프로그램 중 구독 시스템이 맘에 들어서 신청하게 되었다. 사실 엘리스는 양재 RNCD AI 실무자 양성 과정을 참여하고, 각종 무료 교육을 들으면서 친숙했다. 엘리스의 플랫폼에서는 메세지를 통해서 소통을 빠르게 할 수 있었던 것이 기억이 났다. 답답한 게 있으면 빠르게 물어보고 답을 얻어야 하는데 이런 점을 통해서 내가 원하는 바를 만족시킬 수 있을 것 같았다. 또한 개인적으로 문제를 다 풀고 100점이 나오면 토끼 애니메이션이 나오는데 이게 은근히 성취감을 불러일으킨다. 혼자 알고리즘 공부하다보면 문제를 깔끔하게 풀어도 ‘칭찬해 주는 사람도 없는데…’라는 생각이 항상 드는데, 토끼 애니메이션이 문제를 더 잘 풀고 싶게 하는 자극을 주는 게 참 맘에 들었다. 칭찬은 고래도 춤추게 한다고 하지 않은가. 나는 칭찬에 약하고 인정욕이 강한 동물이다.
어쨌든 큰 맘 먹고 10만원으로 퍼플키를 질렀다. 퍼플키를 지르게 되면 곧 튜터가 배정된다. 튜터는 쉽게 말해서 막히는 문제에 대해서 도움을 줄 수 있는 사람이다. 메세지를 통해서 소통하고, 문제가 있으면 답을 해준다. 아직 튜터에게 완전한 답을 받은 적은 없지만, 맘에 드는 시스템 중 하나다.
현재 수강 신청한 건 알고리즘 트랙(트랙으로 강의를 보거나, 구독을 하면 원하는 강의를 한달 동안 볼 수 있다.), 자료구조, 알고리즘1, 알고리즘2이다. 맘 같아서는 다 보고 싶은데, 실습 문제를 풀어야 하니 은근히 시간이 소요가 된다. 자료구조 먼저 끝내고 싶지만, 문제가 있는 것 같아서 알고리즘 트랙부터 끝내고 다른 강의들을 마저 들어야겠다.
문자열(패턴) 하나와 문자열의 배열 하나가 주어집니다. 패턴 문자열의 각각의 문자 하나는, 두번째 문자열 배열의 각각의 문자열 하나에 대응 될 수 있습니다. 해당 배열이 해당 패턴으로 표현 되는지 아닌지의 여부를 확인하는 함수를 만들어 보세요.
예를 들어서, aabb 와 [‘elice’, ‘elice’, ‘alice’, ‘alice’] 가 주어졌을 경우에는 함수가 True를 반환해야 합니다. 이 경우에는 a가 elice에, b가 alice에 대응되도록 하면 배열을 해당 패턴으로 표현 하는 것이 가능하기 때문이죠.
반면, aabb 와 [‘elice’, ‘alice’, ‘elice’, ‘alice’] 가 주어졌을 경우에는 함수가 False를 반환해야 합니다. 모든 문자는 영어 소문자라고 가정합니다.
문제를 보고 쉬울거라고 생각했다. 패턴을 쪼개서 각 단어에 매칭을 시켜주면 간단히 해결될 것 같았다. 하지만 패턴을 쪼개서 단어에 매칭 시키는 게 간단한 문제가 아니었다.
지금은 a와 b뿐이지만 만약에 단어리스트가 주어지는개 100개라면 abcd…로 매칭시키는게 힘들다. 물론 그 정도까지로 테스트 케이스가 나올 것 같지는 않지만…
따라서, 일일이 패턴을 매칭시켜서 판단하는 건 힘들다고 판단해서 이렇게 가는 건 아니라고 생각했고 다른 방향을 모색했다.
그러던 중에 불현듯 패턴과 단어리스트를 zip해보고 싶어졌다. 일단 길이는 서로 무조건 같을 거니까. 그리고 패턴이 일치하는 것을 찾는 거니까 set을 하면 의미있는 결과가 나올 듯 싶었다. 코드와 결과는 다음과 같다.
1 2 3
pattern = "aabb"
strList = ["elice", "elice", "alice", "alice"]
1
set(zip(pattern, strList))
1
Out : {('a', 'elice'), ('b', 'alice')}
잘 생각해보니, set을 한 pattern하고 길이가 똑같을 것 같았다. 직관적으로 그런 생각이 들었다. 일단 테스트로 다음과 같은 코드를 작성해봤다.
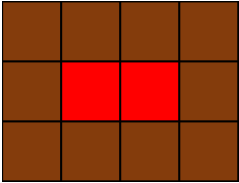
Leo는 카펫을 사러 갔다가 아래 그림과 같이 중앙에는 빨간색으로 칠해져 있고 모서리는 갈색으로 칠해져 있는 격자 모양 카펫을 봤습니다.
Leo는 집으로 돌아와서 아까 본 카펫의 빨간색과 갈색으로 색칠된 격자의 개수는 기억했지만, 전체 카펫의 크기는 기억하지 못했습니다.
Leo가 본 카펫에서 갈색 격자의 수 brown, 빨간색 격자의 수 red가 매개변수로 주어질 때 카펫의 가로, 세로 크기를 순서대로 배열에 담아 return 하도록 solution 함수를 작성해주세요.
제한사항
갈색 격자의 수 brown은 8 이상 5,000 이하인 자연수입니다. 빨간색 격자의 수 red는 1 이상 2,000,000 이하인 자연수입니다. 카펫의 가로 길이는 세로 길이와 같거나, 세로 길이보다 깁니다.
문제는 완전탐색으로 풀라고 하는 것 같았지만, 이 문제는 수학적으로 풀 수 있을 것 같았다. Brown과 Red를 이루는 수를 Red의 m과 n으로 표현해보고 (Red = (m x n)꼴, m>n) 나온 (m,n)꼴에 +2를 해주면, return값이 (m+2,n+2) 나오게 된다는 것을 깨달았다.
하지만 문제가 있었다. 이 경우는 Red가 Square꼴이 아닐 때만 해당했던 것이었다. Red가 Square꼴일 경우, m과 n으로 문제를 풀 수 없다.
이 경우는 다른 케이스를 생각해 봐야 한다. R을 (nxn)꼴이면 Brown이 4(n+1)로 나온 다는 것을 알아야 한다. return은 처음의 케이스와 같이 2만 더해주면 된다.
첫번째 케이스의 경우를 n에 대해서 쭉 풀어주면 이차방정식 꼴이 나온다. 아마도 테스트 케이스는 근이 정수로 나올 것 같아서 중근이나 허근이 나올 경우를 제외한, 근의 공식을 코딩해서 함수화 하였다.
1 2 3 4 5 6 7 8 9 10
deffun(a,b,c): D=b*b-4*a*c if D>0: x1=round((-b-D**0.5)/2*a) x2=round((-b+D**0.5)/2*a)
if x1>x2: return [x1+2,x2+2] else : return [x2+2,x1+2]
그 다음 두번째 케이스로 넘어가는 것이 중요했는데, Brown과 Red를 받았을 때, 특히 Red를 가지고 제곱수인지 판별하는 함수가 필요했다. 만약 Red가 제곱수라면 Red에 루트를 씌워서 값을 받아 2만 더해주면 될 것이고, 제곱수가 아니라면 위의 함수를 이용해서 return을 받으면 된다. 그래서 제곱수 판별하는 함수를 다음과 같이 작성했다.
1 2 3 4
import numpy as np defissquare(n): ifint(n ** 0.5) ** 2 == n : returnint(np.sqrt(n))
마지막으로 solution 함수에서는 이 함수들을 모두 합쳐주고 조건문을 통해서 return값을 다르게 받아준다.
1 2 3 4 5 6 7 8 9
defsolution(brown, red): # return이 제곱 수 아닐 때 if issquare(red) : return [issquare(red) + 2,issquare(red) + 2] else: a = 1 b = (4-brown)/2 c = red return fun(a,b,c)
정리 : 코딩 연습을 꾸준히 해야하는 것이 느껴진 문제였다. 제곱수를 판별하는 문제나, 이차방정식의 해를 구하는 문제는 연습문제로 간간히 나오던 것이었다. 기초적인 문제가 제대로 학습이 되어있지 않으면, 문제 푸는데 굉장히 오랜 시간이 걸리지 않을까 생각했다. 기본적인 문제도 중요하다!
0 또는 양의 정수가 주어졌을 때, 정수를 이어 붙여 만들 수 있는 가장 큰 수를 알아내 주세요.
예를 들어, 주어진 정수가 [6, 10, 2]라면 [6102, 6210, 1062, 1026, 2610, 2106]를 만들 수 있고, 이중 가장 큰 수는 6210입니다.
0 또는 양의 정수가 담긴 배열 numbers가 매개변수로 주어질 때, 순서를 재배치하여 만들 수 있는 가장 큰 수를 문자열로 바꾸어 return 하도록 solution 함수를 작성해주세요.
제한 사항
numbers의 길이는 1 이상 100,000 이하입니다. numbers의 원소는 0 이상 1,000 이하입니다. 정답이 너무 클 수 있으니 문자열로 바꾸어 return 합니다.
처음 이 문제를 봤을 때, ‘어 permutation 쓰면 끝이네 개꿀ㅎㅎ’ 이런 생각이 들었다. 바로 itertool을 import 해서
1 2 3 4 5 6 7 8 9 10 11
from itertools import permutations defsolution(numbers): str_list = [] for i in numbers: str_list.append(str(i)) first=list(map(''.join, permutations(str_list))) int_list = [] for li in first: int_list.append(int(li)) answer = sorted(int_list, reverse=True)[0] returnstr(answer)
이런 코드를 작성해서 제출했다.
결과는!!
시간초과가 떠 버렸다. 효율성이 제로라는 말이다. 검색해보니 permutation은 필요하지 않은 부분까지 순열 조합을 만들어 내기 때문에 굉장히 비효율적인 코드라는 것을 알아냈다.
‘그렇다면 순열같이 코드를 짜되 효율적으로 작성해야 한다는 것인가?’ 라는 고찰과 함께 코딩을 시작했고 하루를 날렸다.
당연했다. 문제푸는 방향이 완전히 잘못되었었다. 효율적으로 순열조합 만드는 코드를 짠다면 내가 라이브러리를 새로 만드는 수준인 것이었다.
방향을 다시 생각해봤다. 사실 이 문제를 풀다보면 list에 있는 원소를 편하게 처리하기 위해 str으로 바꿔야 하고 비교하기 위해 int로 다시 바꿔줘야 하는 번거로움이 있다.
빅데이터 시대에 SQL공부가 필수적이다. 머신러닝, 딥러닝 뭐 할게 너무 많지만 일단 데이터를 이해하기 위해서는 SQL공부를 먼저 해야한다고 생각한다.
이런 마음에 SQL을 공부하기로 마음먹고 세달전에 샀던 데이터 분석을 위한 SQL 레시피를 다시 폈더랬다. 책은 매우 훌륭했다. 기본적인 SQL뿐 아니라, 내가 관심있었던 SparkSQL, Big Query에 대해서도 다뤄주고 있었다. 눈으로 SQL을 슬슬 할 때쯤, SQL을 직접 입력해보고 결과를 보고 싶어졌다.
소스코드가 있나 뒤져봤더니, 한빛 미디어에서 제공해 주는 코드가 있었다. 신나게 받아놓고 1년전에 세팅해둔 Mysql 서버를 실행시켰다.
뭐 잡 에러 덩어리가 많았지만 우여곡절 끝에 해결하고
드디어 MySQL Workbench로 들어가서 쿼리를 날렸다.
Success!가 나왔다.
음, 근데 결과창이 보이지 않는다.
바로 StackOverFlow를 뒤져봤다. 쿼리 옆에 있는 돋보기를 눌러보고 Result Grid를 눌러보랜다. 안된다.
Mac에 있는 버그라며 쿼리 박스에 마우스를 신중히 갖다대고 바를 늘려보랜다. 회색화면만 나온다.
껐다 다시 키면 될 것이란다. 바뀐 게 없다.
아, 모든 게 거짓말 같았다. 오늘은 만우절ㅎㅎ***
이렇게 6시간 넘게 삽질을 지속하다가, 빛 갓 Yogev의 Stackoverflow 글을 보게 되었다.
요약하자면 수정된 버전이 올라와 있다는 말이다. ‘아니 최신 버전을 받았는데 왜 또 안됐었던 거지???’ 이해가 안되긴 하지만 빛요게프 선생님께서는 친절히 공유경제의 장점에 대해 설파하고 계시었다.
upvote를 찍어드리기 위해서 stackexchange에 가입했고 upvote를 꾸우우욱 눌러드렸다.
124 나라에는 자연수만 존재합니다. 124 나라에는 모든 수를 표현할 때 1, 2, 4만 사용합니다. 예를 들어서 124 나라에서 사용하는 숫자는 다음과 같이 변환됩니다.
10진법
124 나라
1
1
2
2
3
4
4
11
5
12
6
14
7
21
8
22
9
24
10
41
자연수 n이 매개변수로 주어질 때, n을 124 나라에서 사용하는 숫자로 바꾼 값을 return 하도록 solution 함수를 완성해 주세요.
문제를 보고 패턴을 찾아야겠다는 생각부터 했다. 3의 배수로 끊어지고, 끝자리가 1, 2, 4로 반복된다는 것을 파악했다.
끝자리는 그럼 1,2,4를 돌려주는 것으로 끝낼 수 있는데, 이제 앞자리가 문제가 된다. 앞자리 패턴을 찾기 위해서 문제 표에는 10까지만 나와있지만, 21까지 구해봤다. 21까지 쭉 따라 쓰다보니, 앞자리 역시 1,2,4가 반복되고 있다는 것을 파악했다. 맨 뒷자리 1,2,4가 끝나면 그 다음 자리 index가 하나 올라가고 그 앞의자리도 마찬가지였다.
그렇다면, 뒤에서부터 자리 수를 채워주는 게 낫다고 생각했고 다 채워준 다음에 뒤집어 버리는 방식을 택했다. 그래서
Class는 객체지향 프로그래밍에서 가장 중요하고도 까다롭다. 흔히 말하는 상속이 무엇인지, 어떤 상황에서 상속을 하는지, 상속을 할 수 없을 때는 객체 관계를 어떻게 표현하는지 알아보자.
클래스 관계
클래스 관계를 나타내는 방법으로 IS-A와 HAS-A가 있다.
1.1 IS-A : 상속
IS-A는 ‘은 ~의 한 종류다’를 말한다. 노트북과 컴퓨터를 예를 들어보자. 노트북은 컴퓨터의 한 종류일까? 그렇다. 이런 관계일 경우 Computer와 laptop 클래스는 IS-A관계라고 말할 수 있다. IS-A관계 인지 아닌지 분간이 안된다면, ‘한 종류다’라는 의미가 있는지 생각해 보자.
이런 IS-A관계를 프로그램에서 표현할 때는 상속을 사용한다. 상속은 IS-A관계에서 설계가 쉽다.
이 코드에서 인스턴스 멤버는 CPU와 RAM이다. 인스턴스 메서드는 browse()와 일을 하는 work()이다. 노트북은 컴퓨터의 모든 멤버와 메서드를 가진다. 노트북에도 CPU와 RAM이 있고, 같은 일을 하기 때문이다. 어떤 객체가 다른 객체의 모든 특성과 기능을 가진 상태에서 그 외에 다른 특성이나 기능을 가지고 있다면 상속해서 쓰는게 편하다.
노트북의 클래스 옆에 Computer가 붙은게 보인다. 이는 컴퓨터 클래스를 상속하겠다는 뜻이다. 이렇게 되면 노트북은 컴퓨터 클래스가 가진 모든 멤버와 메서드를 가지게 된다. 노트북도 browse()와 work()가 가능하다는 말이다. 확실히 손이 덜 피곤하다는 게 느껴질 것이다.
super는 무엇일까? 이것은 기본 클래스를 의미한다. 기본 클래스는 위에서 써놨듯이, 상속을 하는 클래스, 즉 컴퓨터 클래스를 가리킨다. CPU와 RAM은 기본 클래스의 생성자를 이용해 초기화가 되었기 때문에 남은 한 멤버인 battery만 할당해 주면 된다.
그리고 노트북에만 있는 move메서드를 입력해준다. 이렇게 되면, 노트북만의 메서드를 하나 갖게 된다.
이 관계에서는 Police 객체가 만들어질 때 Gun 객체를 가지고 있지 않다. 이후 acquire_gun()메서드를 통해서 Gun 객체를 멤버로 가지게 된다. 이 관계 역시 HAS-A이다. 또한 release_gun()으로 가진 총을 반납할 수도 있다. 이 두 메서드를 이용해 총을 가진 경찰, 총이 없는 경찰 모두를 표현할 수 있다.
하지만 컴퓨터 클래스와 다른 점은, 경찰은 언제든지 Gun을 가질 수 있고 해제할 수 있다는 점이다. 관계가 컴퓨터에 비해 훨씬 약하다는 느낌이 들 것이다. 이런 약한 관계를 통합이라고 부른다.
2. 메서드 오버라이딩과 다형성(Polymorphism)
OOP에서 가장 중요한 개념은 다형성이다(polymorphism). 나는 이 ‘폴리몰피즘’에 대해 노이로제가 걸렸었던 적이 있다. 고려대에서 진행한 Bigdata X Campus 교육에서였다. 파이썬 강의를 들으면서 강사는 “뽈리몰피즘! 뽈리몰피즘이 중요하죠!” 라고 열변을 토했고, 매 강의마다 항상 강조되었었다. ‘도대체 polymorphism이 뭐길래’ 라는 생각이 들었었고, 이 책을 보면서 그 갈증이 어느정도 해결이 되었다.
다형성이란 ‘상속 관계에 있는 다양한 클래스의 객체에서 같은 이름의 메서드를 호출할 때, 각 객체가 서로 다르게 구현된 메서드를 호출함으로써 서로 다른 행동, 기능, 결과를 가져오는 것’을 의미한다. 이를 구현하기 위해서는 파생 클래스 안에서 상속받은 메서드를 다시 구현하는 메서드 오버라이딩이라고 부른다.
2.1 메서드 오버라이딩
먼저 코드를 살펴보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classCarOwner: def__init__(self, name): self.name = name defconcentrate(self): print('{} can not do anything else'.format(self.name))
classCow(Animal): defeat(self): print('eat grass') classHuman(Animal): defeat(self): print('eat meat and grass')
if __name__ == "__main__": animals = [] animals.append(Lion()) animals.append(Cow()) animals.append(Human()) for animal in animals: animal.eat()
이 코드의 Animal 클래스에는 eat()메서드가 있다. 모든 동물은 반드시 먹어야 한다는 가정이다. 하지만 동물마다 먹는 종류는 다르기 때문에 육식 동물의 대표로 사자를 설정했고, 초식 동물의 대표로 소를 설정했다. 그리고 잡식 동물로 사람을 설정했다. 나는 소고기를 쌈싸먹는 것을 좋아한다.
코드의 반복문의 마지막 부분에서 animal.eat()은 다형성을 구현한 부분이다. animals 리스트에서 객체를 하나씩 불러와 eat()메서드를 호출할 때, 메서드를 호출한 쪽에서는 육식동물인지 초식동물인지 잡식인지 고민할 필요가 없다. 각 객체는 오버라이딩된 메서드를 호출하기 때문이다.
그렇게 되면 여기서는 그냥 무엇인가를 먹는 동물은 없다. 그러니까 Animal은 eat something하는 게 있는데 사용하는 동물이 아무도 없다. 안써버리자니 문제가 되고, 뭔가 낭비같다.
이럴 때는 Animal 클래스를 추상 클래스로 만들면 된다.
추상 클래스는 독자적으로 인스턴스를 만들 수 없고 함수의 몸체가없는 추상 메서드를 하나 이상 가지고 있어야 한다. 또한 이 클래스를 상속받는 파생 클래스는 추상 메서드를 반드시 오버라이딩 해야한다. 당연히 아무것도 없으니까!
먼저 abc모듈을 가져온다.(abstract base class) 그 후 @abstractmehod 데코레이터를 붙여준다. 여기서 메서드 구현하는 부분을 pass로 비워두면 eat()은 추상 메서드가 된다. 이제 Animal을 상속받는 모든 파생 클래스는 eat()을 오버라이딩 해야한다.
클래스 설계 예제
클래스를 설계할 때느느 다음 두가지를 고려해야 한다.
공통 부분을 기본 클래스로 묶는다.
부모가 추상클래스인 경우를 제외하고, 파생 클래스에서 기본 클래스의 여러 메서드를 오버라이딩한다면 파생 클래스는 만들지 않는 것이 좋다.
Character 클래스 만들기
게임 캐릭터를 만들어보면서 클래스를 정리해보자. 게임에 등장하는 캐릭터는 플레이어 우리 자신과 몬스터이다. 모든 캐릭터(추상 클래스)는 다음과 같은 특성을 지닌다.
인스턴스 멤버 : 이름, 체력, 공격력을 가진다.
인스턴스 메서드 : 공격, 공격당했을 때는 피해를 입는다.(모두 추상 메서드로 구현한다.)
attack : 플레이어는 공격할 때 공격 종류가 기술 목록 안에 있다면 상대 몬스터에게 피해를 입힌다.
get_damage : 플레이어가 피해를 입을 때 몬스터의 공격 종류가 플레이어의 기술 목록에 있다면 몬스터의 공격력이 반감되어 hp의 절반만 깎인다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classPlayer(Character): def__init__(self, name = 'player', hp = 100, power = 10, *attack_kinds): super().__init__(name, hp, power) self.skills = [] for attack_kind in attack_kinds: self.skills.append(attack_kind) defattack(self, other, attack_kind): if attack_kind in self.skills: other.get_damage(self.power, attack_kind) defget_damage(self, power, attack_kind): if attack_kind in self.skills: self.HP -= (poewr/2) else : self.HP -= power
코드에서 살펴보면 플레이어는 캐릭터를 상속했다.
3.3 Monster, IceMonster, FireMonster 클래스 만들기
몬스터에는 불 몬스터와 얼음 몬스터가 있으며 다음과 같은 특징이 있다.
추가되는 멤버 : 공격 종류를 가진다. 불 몬스터는 Fire, 얼음 몬스터는 Ice를 가진다.
공통 메서드 : 두 몬스터는 같은 행동을 한다.
attack : 공격 종류가 몬스터의 속성과 같다면 공격한다.
get_damage : 몬스터는 자신과 속성이 같은 공격을 당하면 체력이 오히려 공격력만큼 증가한다. 그렇지 않으면 체력이 공격력만큼 감소한다.
여기서 고민해야 할 점이 있다. FireMonster 클래스와 IceMonster 클래스를 Character 클래스에서 상속받아 구현할지, Moster 클래스라는 부모 클래스를 따로 만들어야 할지. 설명에 따르면 추가되는 멤버도 겹치고, fireball()메서드를 제외한 나머지 메서드도 겹친다. 그러면 공통되는 부분을 기본 클래스로 만들고 이를 상속받는 게 좋을 것 같다.
몬스터를 만들고 몬스터는 캐릭터 클래스를 상속받을 것이다. 그리고 몬스터 클래스를 상속받아 각 몬스터를 만들어보자.
if __name__ == "__main__": player = Player('sword master', 100, 30, 'ICE') monsters = [] monsters.append(IceMonster()) monsters.append(FireMonster()) for monster in monsters : print(monster) for monster in monsters: player.attack(monster, 'ICE') print('after the plater attacked') for monster in monsters: print(monster) print('') print(player) for monster in monsters: monster.attack(player, monster.get_attack_kind()) print('after monsters attacked') print(player)
4. 연산자 오버로딩
연산자 오버로딩은 클래스 안에서 메서드로 연산자를 새롭게 구현하는 것으로 다형성의 특별한 형태이다. 연산자 오버로딩을 사용하면 다른 객체나 일반적인 피연산자와 연산을 할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classPoint: def__init__(self, x=0, y=0): self.x = x self.y = y defset_point(self, x, y): self.x = x self.y = y defget_point(self): return self.x, self,y def__str__(self): return'({x}, {y})'.format(x = self.x, y = self.y) if __name__ == "__main__": p1 = Point(2,2) p2 = p1 + 3 print(p2)
결과를 실행해 보면 에러가 발생할 것이다. Point와 int 객체 사이는 덧셈을 할 수 없다고 나온다.
1 2 3 4 5 6 7 8 9
def__add__(self, n): x = self.x + n y = self.y + n return Point(x,y) if __name__ == "__main__": p1 = Point(2,2) p2 = p1 + 3 print(p2)
이렇게 add메서드를 추가해보자. 예약한 함수를 사용해서 x좌표와 y좌표에 인자 n을 더한 새로운 x와 y로 새로운 객체를 만들어 반환한다. 실행 결과는 (5,5)가 나오게 된다.